An Efficient and Accurate Scene Text Detector
tags: Target Detection
In this paper, we propose a fast and accurate scene text detection algorithm, only two steps. The full convolution algorithm uses the network model to generate predicted word or text line level directly, eliminating redundancy and slow intermediate steps. Generated text prediction, may be a rectangular quadrilateral may be rotated, these projections into the non-maximum suppression results to obtain the final result.
This article is a contribution to the works of three parts:
We have proposed a two-step scenario include text detection method: FCN and NMS consolidation phase. FCN text area produced directly, eliminating the intermediate steps have redundant and time-consuming.
Algorithm generating word level is too flexible or too predictive text lines, geometric shapes may be rectangular or quadrangular rotatable, depending on the particular application.
The proposed algorithm on the accuracy and speed significantly better than the best way now.
The method utilizes a convolutional neural network multilayer image feature extraction, and then were characterized using the two tasks, the return block of pixel classification, and the corresponding pixel points. Finally, the combined result of two tasks, and to suppress non-NMS to obtain a final maximum value detection results.
Network Architecture
We model diagram shown in Figure 3. Model can be divided into three parts: trunk feature extraction, feature merging branches and output layer. . PVANet used herein and VGG16, the FIG. 1 is a network configuration diagram of the original (PVANet)
ImageNet backbone may be a pre-trained data set convolutional network, and the cell layer alternately convolution. The network input picture, four stages convolutional layer can be obtained four feature map, respectively, f4, f3, f2, f1, which are reduced with respect to the input image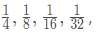 After using the samples, the concat (serial), to give successively convolution h1, h2, h3, h4, h4 obtained after fusion of the feature map, having a size of 3 × 3 channels of a roll 32 convolution kernel convolution final feature map.
After using the samples, the concat (serial), to give successively convolution h1, h2, h3, h4, h4 obtained after fusion of the feature map, having a size of 3 × 3 channels of a roll 32 convolution kernel convolution final feature map.
In the feature merging branches, we gradually merge them:
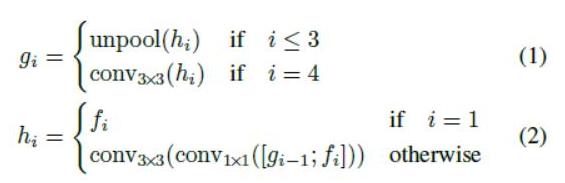
gi is an intermediate state, FIG Hi is integrated feature, operator [;.] represents the dimension along the channel mosaic. In each of the merge phase, wherein a phase map from the first layer to expand unpooling fed twice its size, and then splicing the current map features. Next, convolution bottleneck 1 * 1 will reduce the number of channels to reduce the amount of calculation, behind a 3 * 3 convolution with the fusion to generate a final output information to the merger phase. The final output, a 3 * 3 convolution generate a final combined features of FIG branches, feeding the output layer.
After obtaining a final feature map, using a number of channels, a 1x1 convolution kernel obtained a score map 1 is represented by Fs. Using a feature map on the size of 1 × 1 4 the channel number is obtained by a convolution kernel text boxes, using a size of 1 × 1 number of channels is obtained by a convolution kernel text rotation angle, where text boxes and text rotation angle collectively referred to as geometry map is represented by Fg.
This paper has defined in the text box on the two types of rotary rectangular (RBox), the other is a quadrangle (QUAD). Because the code is only achieved RBOX, so the following only for RBOX box for analysis.
Below we explain in detail the second representation RBOX. We know that, for any fixed point, if it is determined that the distance between the point of the four sides, then it can determine a rectangular frame. If we add the angle information, the five parameters d1, d2, d3, d4, theta and a rectangle can be determined uniquely angled. The use of this method is the way to get back in the box GroundTruth. For example in FIG view showing four distance d of each point, e view showing a corresponding angle.
Some of the above Fs, Fg be explained
Fs original size is the number of channels is 1 1/4, each pixel represents a pixel corresponding to a text original probability values, the value of [0,1] in the range of .
Fg size is also 1/4 the number of original channels 5, i.e. 4 + 1 (text boxes + text rotation angle).
text boxes number of channels 4, wherein if the text boxes corresponding to each pixel in the original image is a text pixel, the four channels respectively from the four sides of the pixel to the text box, the size range is defined as the input image, if the input image 512, that is, the range [0, 512]. D represents the FIG.
text angle rotation number of a channel, wherein if the text rotation angle corresponding to each pixel in the original image is a text pixel, the pixel where the inclination angle of the frame, is defined as the angular range [-45,45] degrees. E represents the FIG.
Generate labels on training
As can be seen, the training label consists of two parts, one is the score map label is a label geometry map.
The method of generating tag 1. score map
First generate a picture with the same size of the matrix, values are 0
Good rectangular frame zoom out calibration according to the rectangular frame, the method will be described in detail below reduction, to give the final result as the green box 2a in FIG.
The assignment of pixels in the green box represents the score 1 positive samples, the other for the negative sample score
Finally, according to every four pixel samples, 1/4 the size of the image obtained score map
Reduction of the above-described quadrilateral:
First, define the four vertices The four vertices are arranged in a clockwise direction
The four vertices are arranged in a clockwise direction
Reference size reduction calculation shown in the following formula is represented by the formula selected two connected edges and vertices of the smallest edge size denoted ri
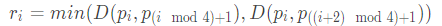
Where D (pi, pj) denotes the distance l2 between points pi and pj
for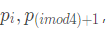 Two points, respectively, to move
Two points, respectively, to move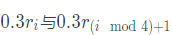 To narrow his
To narrow his
The method of generating a geometry map label
Geometric map may be any of a RBOX or QUAD. For the generation process of FIG RBOX above (c-e) below. QUAD For text regions are in the form of calibration data set (e.g. ICDAR2015), we first generate a rotated rectangle covering a minimum area of the region. Then for each pixel has a positive score, we calculate the distance to the boundary of the four text boxes, and drop it in four channels RBOX.
Defined loss function


Intelligent Recommendation

[Learning] paper Feature Pyramid Based Scene Text Detector
Feature Pyramid Based Scene Text Detector Publications: ICDAR 2017 Author: MengYi En, Beijing University of Technology Content: OCR, text detection in multi-scale scene Abstract Question: CNN network ...

"TextBoxes++: A Single-Shot Oriented Scene Text Detector" paper notes
1 Overview The method given in this article is to solve the problem of rotating text detection. Therefore, the method TextBoxes++ of the article can detect slanted text. The method of detecting text i...
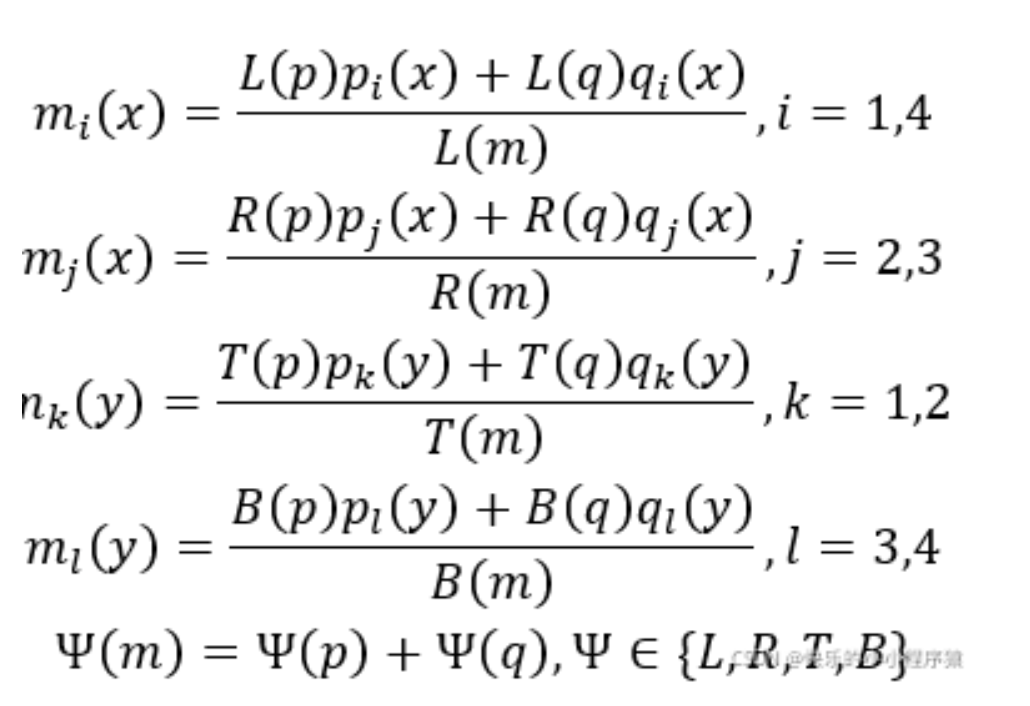
MOST: A Multi-Oriented Scene Text Detector with Localization Refinement
1 Introduction Modern text detectors are capable of capturing text in a variety of different challenging scenarios. However, they may still fail to detect text instances when dealing with extreme aspe...

Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network(PANNET)
Basic Information Source: AAAI2019 Author: wenhai wang, enze Xie ... Tags: text detection; ocr; segment; curve text Paper address:arxiv Detailed Core task Aware of oneHigh efficiency (fps = 84.2) And ...

PAN++: Towards Efficient and Accurate End-to-End Spotting of Arbitrarily-Shaped Text
PAN++: Towards Efficient and Accurate End-to-End Spotting of Arbitrarily-Shaped Text Basic Information Source: TPAMI Author: Wenhai Wang, Enze Xie… Tags: text detection, end2end, text spotter, ...
More Recommendation
Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network
1. Introduction: TextSnake and PSENet are text instances designed to detect curves and are also widely seen in natural scenes. However, complex pipelines and a large number of convolutional operations...
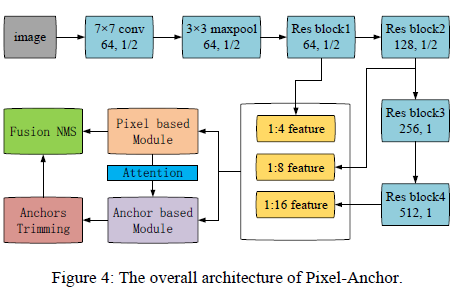
[Interpretation of the paper] Pixel-Anchor: A Fast Oriented Scene Text Detector with Combined Networks
Perface Recently, I was curious about the detection problem of large and long text lines in the text detection of the scene. So I investigated the detection results of the ICDAR2017MLT data set and fo...
[Training test process record] SSD: Single Shot Detector for scene text detection
Introduce the use of SSD model for scene text detection. Example data set: COCO-Text. Compilation part: 1. Error when compiling with cuda8 /usr/include/boost/property_tree/detail/json_parser_read.hpp:...
PHP7 extended development hello word
This article is based on PHP7 and explains how to create a PHP extension from scratch. This article focuses on the basic steps of creating an extension. In the example, we will implement the following...