[Interpretation of the paper] Pixel-Anchor: A Fast Oriented Scene Text Detector with Combined Networks
Perface
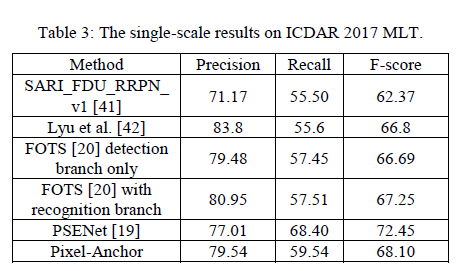
Recently, I was curious about the detection problem of large and long text lines in the text detection of the scene. So I investigated the detection results of the ICDAR2017MLT data set and found that the best result of the current open source is the "Pixel-Anchor" of Yuncong Technology. The result of the competition Reached 74.54%, the editor is very curious about what fairy operation can achieve such a good result, so I found the original text of the paper and intend to find out (although the result of MLT in the paper is only 68.1%, but IC2015 reached 87.68%), strong self There is a strong truth.
There are many operations in the article. I will try to find a way to sort out the ideas and make the article easy to understand. The author combines the advantages of Pixel-based and Anchor-based methods, so it is called Pixel-Anchor (this is my guess)
Link to the original paper:https://arxiv.org/abs/1811.07432v1
Abstract
- end-to-end trainable, including the combination of semantic segmentation and SSD (through shared features), and anchor-level attention mechanism to detect multi-directional text
- In order to detect text with a larger size and aspect ratio, in the semantic segmentation, the author combines FPN and ASPP as the structure of the encoder-decoder
- There is no complicated post-processing in the test phase, only "Fusion NMS"
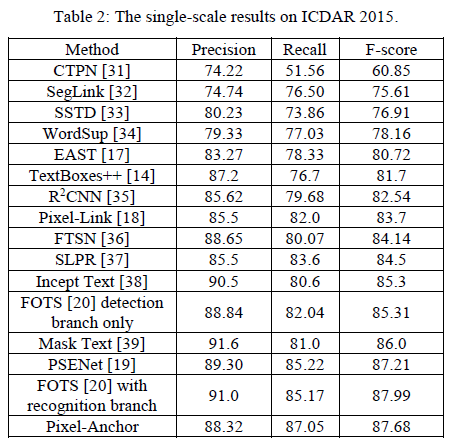
- In IC2015, it reached 87.68%, 10FPS, for 960 * 1728 resolution pictures
1.1 Motivation
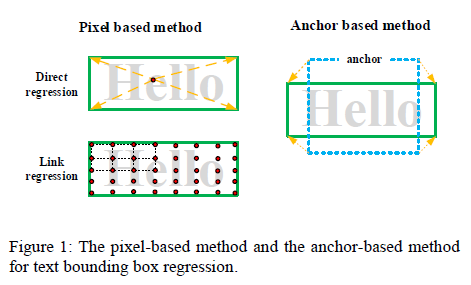
- Current text detection algorithms are mainly divided into Pixel-based and Anchor-based, but these two methods have drawbacks
- The Pixel-based method has high precision but low recall:
- Fine features based on Pixel level, making precision higher
- For small texts, Pixel-level features are too sparse (sparse), so recall is not high for small texts.
- Anchor-based method, with low precision, but high recall
- The low precision is because the anchor is based on the coarse-grained features of the entire text, rather than the fine features at the Pixel level, and its accuracy is often not as good as pixel-level detection.
- The high recall is because the anchor-based method is not sensitive to the size of the text.
- In addition, the anchor-based method will cause "Anchor Matching Dilemma" for "large angle dense text blocks" (anchor matching dilemma, explained later).
- Whether it is Pixel-based or Anchor-based, it is not very good for detecting "long Chinese texts".
- The Pixel-based method has high precision but low recall:
- Therefore, the author's approach:
- Combining the advantages of Pixel-based method with high accuracy and the advantages of Anchor-based method with high recall rate:
- The Segmentation heat map obtained by the Pixel-based method is used to guide the Anchor-based methods, so that the anchor based method can obtain high accuracy while obtaining high accuracy
- Trim the anchor, keeping only the anchors of small and long, and remove the prediction of small texts by Pixel-based method
- In order to be able to predict text with a larger range of scales and aspect ratios:
- Combining FPN and ASPP, do ASPP on 1 / 16Size feature map to improve RF (Receptive Field), and only doing ASPP on 1/16 map is low-cost
- In addition, the author has also designed a network Adaptive Predictor Layer (APL) to adjust the aspect ratio of the anchor, the aspect ratio of the anchor, the shape of the convolution kernel and the spatial density of the anchor, with higher efficiency for the characteristics of different levels Better adapt to changing text scale and aspect ratio.
- Combining the advantages of Pixel-based method with high accuracy and the advantages of Anchor-based method with high recall rate:
1.2 Contributions
- Pixel-Anchor, through feature sharing (implemented by anchor-level attention mechanism) to combine Pixel-based method and Anchor-based method to detect text, and finally obtain the detection result through the "Fusion NMS" proposed by the author
- On the basis of SSD, Adaptive Predictor Layer (APL) is proposed to better detect text with variable scale and aspect ratio, which is very effective for long text lines
- The model can be end-to-end trainable, which improves the speed and accuracy (even in the case of low resolution inputs, you can get good results)
1.3 Other points of view
- The stroke characteristics of the text are obvious, so it is easy to segment the text pixel from the background.
- Although EAST and FOTS have very good results, but the maximum text size they can predict is proportional to the RF of the network, so they are limited by the receptive field, and they are not good for long text.
- Although the method of Pixel Linking is not limited by the receptive field and can detect "very long text lines", this type of method requires a complicated post-processing process and is easily interfered by complex background
- Textboxes++ fails to deal with “dense and large-angle texts”
- In order to solve the "dense and large-angle texts" problem, DMPNet and RRPN proposed multi-directional anchors, but greatly increased the number of anchors. In addition, when calculating any two quadrilateral intersections, it is particularly time-consuming (especially the number of anchors is very When there are many)
- Anchor-based methods learn abstract features describing text instances, not pixel-level stroke features. Therefore, the abstract features of Anchor-level need face more diversity, therefore, there will be more false positives, but anchor is more robust to text size, so it detects small text.
1.4 Definition of “Anchor Matching Dilemma”
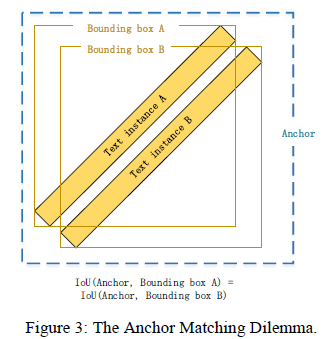
- Textboxes ++ uses horizontal rectangles as anchors. When it encounters two "large-angle" text instances that are close together, it is difficult to decide which text instance the current anchor should match, which is called "Anchor Matching Dilemma". This makes the network less effective for dense, large-angle text.
2.1 Overall Architecture
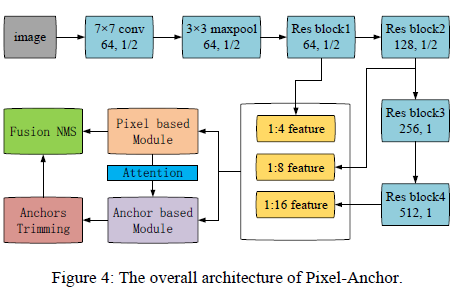
- Based on Resnet-50, the feature size before classification is 32
- For the semantic segmentation of the pixel-based method, the more dense feature of Size 16 is used, and the hollow convolution of Rate 2 is added
- The characteristics of 1/4, 1/8, 1/16, are shared by Pixel-based and Anchor-based
- Segmentation heat map is fed to Anchor-based method, through anchor-level attention mechanism
- No complicated post-processing, only a "Fusion NMS"
2.2 Pixel-based Moduls
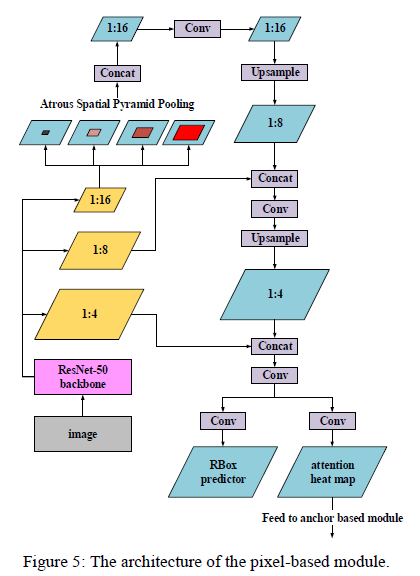
- Based on EAST, there are a total of 7 channels, including text-non text prediction, 4 upper right, lower left distance, 1 rotation angle, and 1 Attention heat map
- In order to get the characteristics of high resolution, high semantics and high receptive fields: combining FPN and ASPP, the dilation rate of ASPP is adjusted from {6,12,18} to {3,6,9,12,15,18}, to "obtain a finer receptive field"; and most of the operations are done based on the 1:16 feature map, so while ensuring high efficiency, we also get a larger receptive field
- Some details:
- For the text example of distinguishing very close, only "shrunk polygon" is predicted. But for Attention heat map, "shrunk polygon" is not used, all the original text areas are treated as positive text areas
- The classification uses OHEM to calculate the pixel classification loss. The pixels used for classification include: 512 hard negative non-text pixels, 512 random negative non-text pixels, and all positive piexels. Using cross-entropy loss
- The regression uses OHEM, 128 hard positive text pixels, and 128 random positive text pixels. Adopt IOU loss regression
2.3 Anchor-based Modules
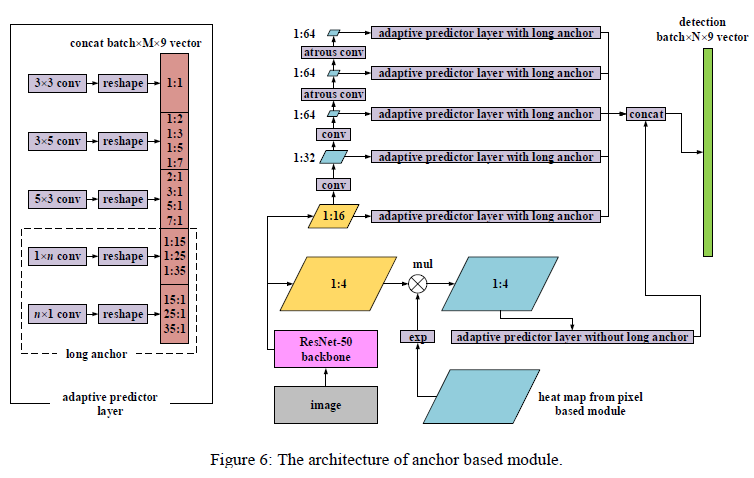
- Modify based on SSD to predict text of large variances in size and aspect ratio
- Only 1: 4 and 1:16 features are used, and they are shared by Pixel-based methods. In order to avoid too small feature maps, the size of the last two 1:64 features remains unchanged.
- Using 1: 4 instead of 1: 8 feature is to strengthen the detection ability of small targets
- Attention heat map acts on the 1: 4 feature through exponential enhancement, so that each pixel is mapped to [1.0, e], thereby highlighting the detection information while ensuring the background information, and also reducing the falseness of small text Positive test
- For APL:
- According to anchor's aspect ratios, they are divided into 5 groups, and different convolutions:
- Square anchors: aspect ratio = 1:1, convolutional filter size 3×3.
- Medium horizontal anchors: aspect ratios = {1:2, 1:3, 1:5,1:7}, convolutional filter size 3×5.
- Medium vertical anchors: aspect ratios = {2:1, 3:1, 5:1, 7:1}, convolutional filter size 5×3.
- Long horizontal anchors: aspect ratios = {1:15, 1:25,1:35}, convolutional filter size 1×n.
- Long vertical anchors: aspect ratios = {15:1, 25:1, 35:1},convolutional filter size n×1.
- For long anchor, the n of each feature map is different, depending on the length of the detected text line
- For the 1: 4 feature, we will not let him predict the long anchor
- For the remaining features, from bottom to top, n is {33,29,15,15,15}
- Through APL, feel the wild can better fits the text
- According to anchor's aspect ratios, they are divided into 5 groups, and different convolutions:
- anchor-based methodsOutput9 channels: 1 prediction is the probability of a positive example, and the other 8 predictions are offset relative to the anchor coordinates
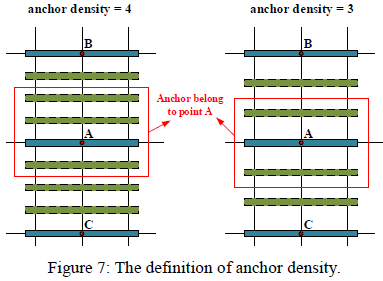
- In order to detect dense texts:
- Put forward the concept of "anchor density":
- In order to better cover dense texts, each anchor is duplicated with some offsets based on anchor density
- Put forward the concept of "anchor density":
3. Experiments


[Also recommend Lei Feng Network Pixel Anchor to understand]
Intelligent Recommendation

[ ]Fused Text Segmentation Networks for Multi-oriented Scene Text Detection
FuseTextIt is a very typical working mode.First look at the frame diagram, if you look at itFPNwithFCIS, It will be clear at a glance. Its architecture mainly depends on FCIS, and then I personally fe...
Natural scene text processing paper collation (1) Spatial Transformer Networks
paper:Spatial Transformer Networks In Theano framework, the STN algorithm has been encapsulated as an API and can be called directly. See the end of the article for tensorflow implementation. 1. Struc...
An Efficient and Accurate Scene Text Detector
In this paper, we propose a fast and accurate scene text detection algorithm, only two steps. The full convolution algorithm uses the network model to generate predicted word or text line level direct...

[Paper notes] Arbitrary-Oriented Scene Text Detection via Rotation Proposals
Arbitrary-Oriented Scene Text Detection via Rotation Proposals Paper address:https://arxiv.org/abs/1703.01086 github address:https://github.com/mjq11302010044/RRPN This paper is based on the faster-rc...
Interpretation of Fast BERT paper
Article Directory I. Overview Second, the detailed model BackBone Model Training Adaptive Inference 3. Experiment 3. Conclusion Reprinted from: https://zhuanlan.zhihu.com/p/143027221 Since the advent ...
More Recommendation

[Paper interpretation] [Paper translation] ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network
Author: Yuliang Liu ‡; South China University of Technology; the University of Art to Germany; Huawei Noah's Ark Laboratory background knowledge: Paper translation: Abstract Scene...

Paper interpretation: SSD: Single Shot MultiBox Detector
Codes provided in the paper is available at: https://github.com/weiliu89/caffe/tree/ssd Papers link:SSD:Single Shot MultiBox Detector Video Tutorial: The paper's contributions: Faster than the mo...
[Interpretation of the paper] R2D2: Reliable and Repeatable Detector and Descriptor
NeurIPS 2019 Code address Conference video abstract It is not enough to learn only repeatable and salient feature points. The salient regions are not necessarily discriminatory, so this may damage the...

"SSD-Single Shot MultiBox Detector" paper interpretation
"SSD-Single Shot MultiBox Detector" paper interpretation table of Contents "SSD-Single Shot MultiBox Detector" paper interpretation brief introduction SSD300 Architecture Detection...

[ ]EAST: An Efficient and Accurate Scene Text Detector
1 Overview EASTThis is one of my favorite papers related to text detection this year, because a great god has reappeared[2]And easy to learn. The reason for liking is mainly in the results, there are ...