Introduction to the text detector paper --- Scene Text Detector Overview
Introduction to the text detector paper --- Scene Text Detector Overview
I have recently begun to explore the algorithm of text detectors. The following are some of the content summarized these days. My idea is to provide you with a framework for quickly browsing, understanding and remembering the design ideas of mainstream text detectors when you get started. I hope it can be used as an introductory guide. A material for everyone to use. Since the initial purpose is to look at the Pixel-anchor, the design drawings of other algorithms are not attached. I have the opportunity to add them one by one in the future. This article continues to be updated, and I hope you can enlighten me.
Overview
Thoughts from
pixel_anchor detailed introduction
Reference Source
Introduction to OCR Technology
Deep learning OCR Overview
SOTA:(2019.05.27)
The top three algorithms currently on ICDAR15-17 are:
- FOTS (+recognition)
- Pixel-Anchor
- PSEnet
When only considering precision, recall, and Fscore, FOTS has the highest accuracy, PSEnet has better recall performance, and Pixel-Anchor is more balanced
Four types of errors in text detection
- Miss: Missing some text areas;
- False: treat some non-text areas as text areas by mistake;
- Split: Wrongly split the entire text area into multiple separate parts;
- Merge: Incorrectly merge several independent text areas
Methods Summary
I roughly categorize the paper into the following three categories in terms of ideas. The first category is Anchor-based methodm. The path is similar to target detection, but some meaningful improvements in text detection scenarios are appropriately updated. The most typical one is The algorithm of textboxes has been updated. The second category is the Pixel-based method, which takes the idea of image segmentation. According to the characteristics and tasks of different text detection data, different losses will be designed, and different methods will be formed. This method is also the most popular idea at present, because of the problems of the anchor-based method itself, such as the difficulty of long text detection, etc., do not discard There is no way to solve the ahchor setting. Of course, some of the current anchor-free methods will also be new ideas and directions for text detection. The third type is the fusion method, which is actually combining the above two methods to try to find the best candidate frame.
There is another classification method in the design of text detector, which is divided according to the different tasks of text detection. Specifically, it can be roughly divided:
- Long bar text (line text)
- Curved text (text with a curved direction, common in trademarks, signs, etc.)
- Irregular text (artistically designed distorted fonts, text mixed with patterns, etc.)
However, I personally think that this classification method does not well reflect the current development trends and ideas in the academia and industry, nor can it express the design principles of the text detector. So after weighing it over and over again, I still think that when reading papers at the beginning, you should browse the articles according to the design ideas.
Below I list some more classic articles from various perspectives for your reference or guidance.
Pixel based (segmentation)
Drawback: low recall, poor detection of small targets
-
direct regression:
directly return to five channels, corresponding to xywh + angle-
EAST
A pipeline, Unet as backbone + feature fusion to a scale + [cls_loss + (IOU_loss + theta_loss)] [tricks: Use ratio=0.3 to shrink gtbox during training to ease text overlap and adhesion The detection is not accurate; when cls_loss is weighted-CEloss, the weight setting is related to overlap] -
AdvanceEAST
EAST improves the poor detection of long text: the main improvement is in the loss design part, after feature fusion to a scale, the output part is connected from the original F_score and F_geometry [cls_loss + (IOU_loss + theta_loss)] changed to [inner_cls + edge_cls + front_end_cls + (IOU_loss + theta_loss)] -
PSEnet
Unet as backbone + feature fusion + FPN + [origin_scale_dice_loss + ith_scale_dice_loss]
[tricks: Set the corresponding indentation ratio according to the FPN zoom level during training, to achieve the purpose of multi-level learning to expand the detection box from the center, and design for irregular fonts 】
-
-
linked regression:
The method of regressing the connection relationship is based on the following two algorithms as classics.-
Seglink
Only connect the left and right adjacent in the horizontal direction (link), which means that two channels are set on the output channel, corresponding to the left link and right link operations, the value 1 is the link, and the value 0 It is not connected. Another point is that the connected object is called "segmentation" in the text, which is actually a bounding box, not a pixel on the feature map. -
pixel-link
The pixel-link improved from the idea of Seglink looks more reasonable. Compared with the above description, it can be considered that pixel-link has two main improvements over seglink. The first one is Abandon the use of segmentation and use pixel as the connection object. The second is in addition to the left and right connections, all 8 pixels in a pixel neighborhood are connected and returned. The results produced in this way are of course more convincing, and theoretically more robust, and there is no need to introduce operations such as rotating bbox to detect non-horizontal boxes.
Of course, I personally think that the biggest problem in the use of this algorithm is that there are too many hyper-parameters introduced, and these hyper-parameters have a great impact on the results, including the connection relationship confidence Once the code is incompletely written, super parameter adjustment is a nightmare.
-
Anchor based
Drawback: Low precision, severely affected by anchor design (semi-object detector)
Comparison of TextBoxes and TextBoxes++
-
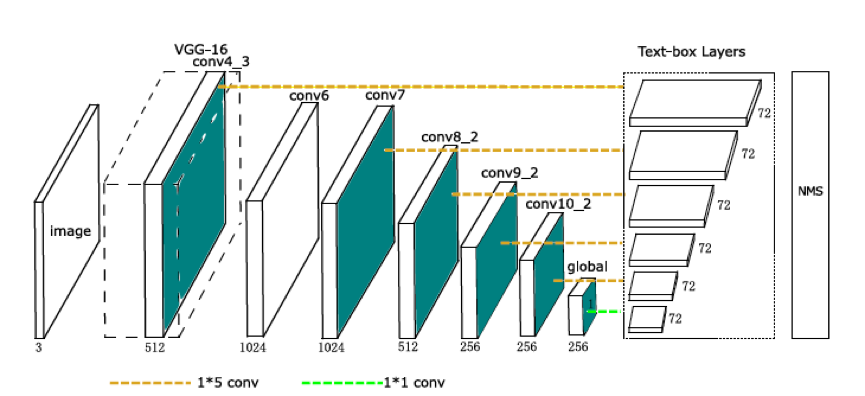
textboxes
An improved version of SSD for text detection, only the following modifications are made on SSD [Theoretically, only single word detection is performed, and only horizontal rectangular boxes can be displayed]- The 3*3 convolution kernel is changed to a 1*5 convolution kernel, which serves the horizontal bar shape text
- The default anchor box is changed to 1:1 and 1:5
- The default anchor ratio is changed to 2,5,7,10
- In order to avoid the slender horizontal frame causing insufficient vertical coverage, add a grid point in the middle of the vertical direction of the original grid point
-
DMPnet / RRPN:
rotate anchor boxes as post process [The simple understanding is that the regression part does not use xywh+ rotation angle to return, but returns to the four corners of the quadrilateral box with a total of eight values] -
textboxes++
Improved to solve the problem that textboxes cannot detect rotated text:- 1*5 convolution kernel is changed to 3*5 convolution kernel, and the output is used as a textbox layer to serve the subsequent output of the text box
- The default anchor ratio is changed to symmetrical form 1,2,3,5,1/2,1/3,1/5
- The network output is divided into two parts. After the horizontal box comes out, it matches the default_box (the horizontal rectangular box converted from gtbox from default_box), and then learns 8 offsets from default_box to gtbox
Fusion
-
FOTS
The advantage lies in the joint training of detection and recognition, excluding recognition, the speed effect is not amazing, and the detection performance is less than the top three (the recognition branch has at least 3 points of guidance for detection)- detector branch: shared Conv [ResNet50+UNet] --> EAST [Improved the feature fusion part of EAST, but does not use AdvancedEAST's out-of-frame mechanism]
- recognition branch: shared Conv [ResNet50+UNet] --> ROIRotate [Straighten the note by affine transformation] --> text recognition [VGG-block+LSTM+CTC]
The loss function is Loss = loss_dect + loss_reg
-
Pixel-Anchor
- Pixel-based branch:
【EAST + ASPP in 1/16】 as feature fusion module -->
[cls_loss + (IOU_loss+theta_loss)] + [attention-heatmap (no R version of cls_loss, not included in the loss function)] - Anchor-based branch: SSD-like fork [1/32, 1/64, 1/64 w atrous, 1/64 w atrous], four branches for APL [adaptive prediction layer, convolution according to anchor box matching], plus pixel -based-attention-heatmap, return after 5 feature maps concatenate [8-xy-offset+confidence]
- some tricks:
- OHEM divides 1:1 positive and negative samples
- extra-grid-point reference textboxes
- anchor truncate 【in anchor-based APL, truncate amount of conv kernel settings】
- Cascaded NMS [Because non-horizontal box NMS is time-consuming, the first step is to use horizontal rectangular box (default-box in textboxes++) as normal NMS, and then use shaply-NMS]
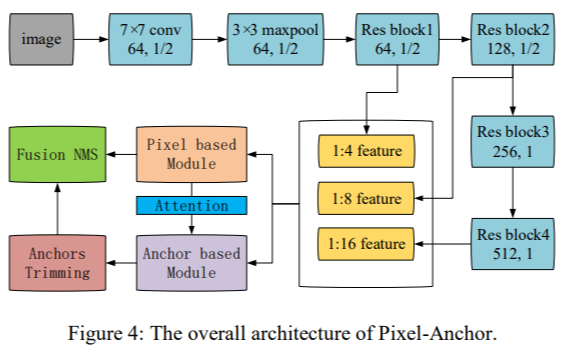
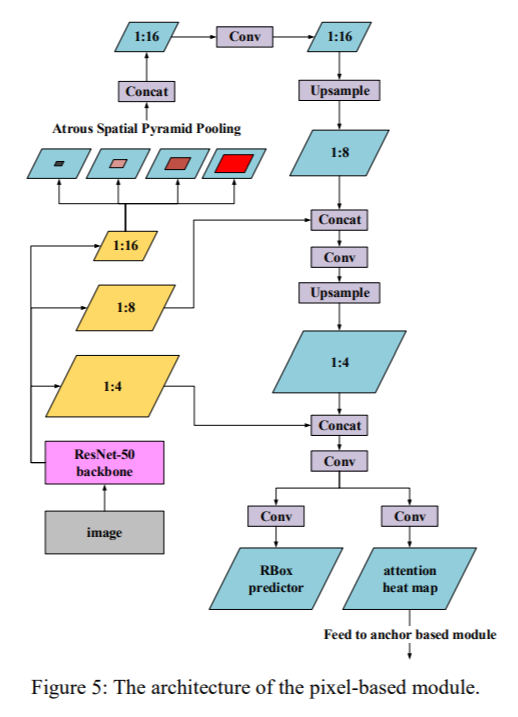
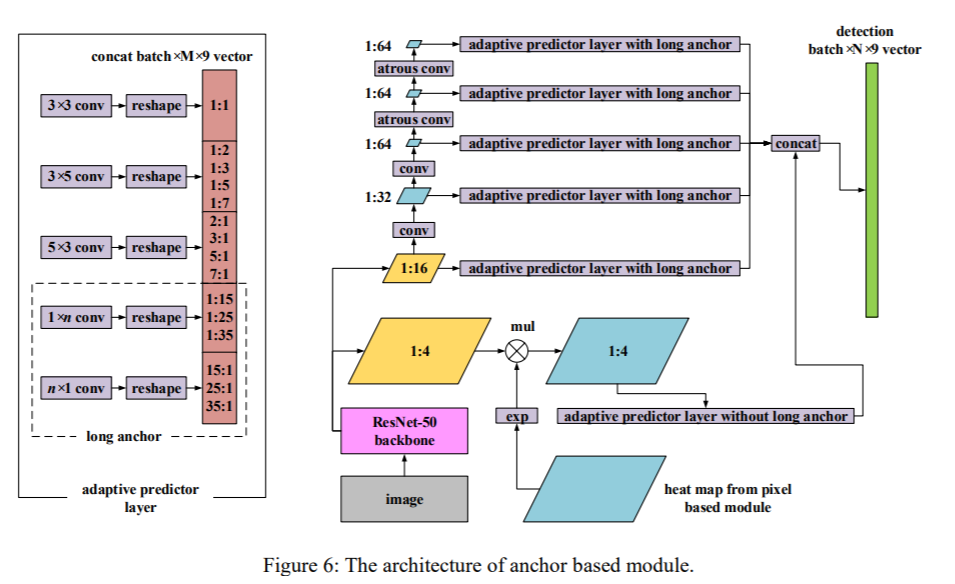
- Pixel-based branch:
Intelligent Recommendation
MOST: A Multi-Oriented Scene Text Detector with Localization Refinement
1 Introduction Modern text detectors are capable of capturing text in a variety of different challenging scenarios. However, they may still fail to detect text instances when dealing with extreme aspe...
Paper notes: TextBoxes: A Fast Text Detector with a Single Deep Neural Network
Transfer http://blog.csdn.net/w5688414/article/details/77986955 Impression This article is about the natural scene text detection paper, to detect the picture text with a deep neural network, also mad...
EAST: An Efficient and Accurate Scene Text Detector (text recognition in natural scenes) training, testing
First introduce my environment configuration, ubuntu16.04+cuda9.0, cudnn7.0, tensorflow-gpu=1.8 Introduction In fact, this is not very researched, just to participate in an Ali Tianchi competition, an...

EAST: An Efficient and Accurate Scene Text Detector Text recognition in natural scenes (principle and code understanding)
Recently, I am studying text recognition in natural scenes, and there is a relatively new model EAST, so I will learn it. Original address of the paper:https://arxiv.org/abs/1704.03155v2 Source code:h...
[Training test process record] SSD: Single Shot Detector for scene text detection
Introduce the use of SSD model for scene text detection. Example data set: COCO-Text. Compilation part: 1. Error when compiling with cuda8 /usr/include/boost/property_tree/detail/json_parser_read.hpp:...
More Recommendation
Pyramid Mask Text Detector reading notes
2020.9.9 Pyramid Mask Text Detector The author analyzed the problems of the previous Mask-RCNN-based method, and on this basis, proposed an improvement method and designed PMTD. problem an...

Overview scene text detection
Summary of the scene encompassing a text detection algorithm - known almost current regression-based method is not special, because of the need to manually adjust the parameters of the anchor (hyper-p...

11 skin tone "scene detector"
11 skin tone "scene detector" The three images in the program have been processed, and the brightness of the previous one is increased by 25. The specific code is as follows: The result of r...

Flashing detector (1) _ Flashing Detector Introduction
Blogger's WeChat public number: FPGA Power Alliance Blogger's personal WeChat: FPGA_START Blog Original link: Nuclear radiation interacts with certain transparent substances, which will ionize, excita...
PHP7 extended development hello word
This article is based on PHP7 and explains how to create a PHP extension from scratch. This article focuses on the basic steps of creating an extension. In the example, we will implement the following...