MOST: A Multi-Oriented Scene Text Detector with Localization Refinement
tags: computer vision deep learning artificial intelligence
1 Introduction
Modern text detectors are capable of capturing text in a variety of different challenging scenarios. However, they may still fail to detect text instances when dealing with extreme aspect ratios and different scales
In order to deal with these difficulties, we propose a new algorithm for scene text detection in this paper, which proposes a series of strategies to significantly improve the quality of text localization
EAST, a very representative one-stage scene text detector, has been proven to fail to detect text instances with extreme aspect ratios. (You can check out the EAST paper)
There are two main reasons for this:
1) The receptive field of the network is limited, so there is not enough information to accurately predict long text instances with spatial expansion.
2) In the NMS step of EAST, the detection fusion uses their text/non-text classification scores as weights, which ignores their quality differences caused by the limited receptive field of the network, and finally leads to biased geometric estimates
This paper proposes a Multi-Oriented Scene Text Detector (MOST) with localization refinement. The localization refinement part consists of a Textual Feature Alignment Module (TFAM) and a Position-Aware Non-Maximum Suppression (PA-NMS) module.
The former aligns image features with coarse detection results, which can dynamically adjust the receptive field of the localization prediction layer. On the other hand, the latter adaptively merges raw detections according to where they were predicted to focus on accurate predictions while discarding inaccurate ones.
2. Performance effect
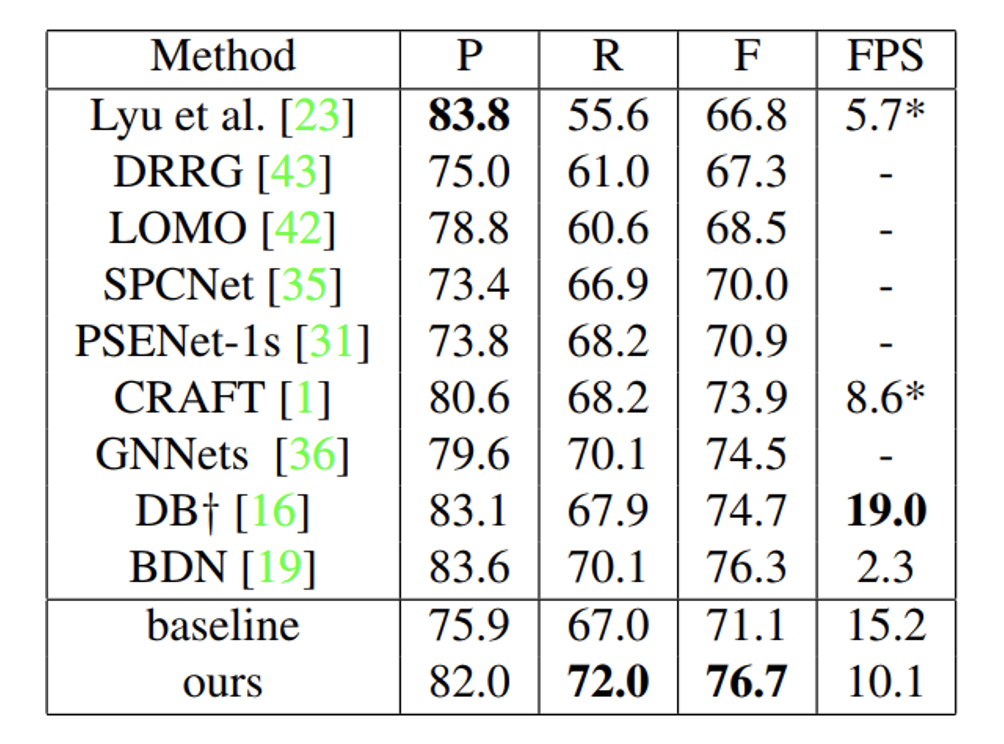
In particular, they improve performance by 4.0% and 9.5% on the MLT17 validation set (for different IoU criteria), and by 5.1% on the MTW1 test set. Also, our proposed text detector maintains a simple pipeline and runs very fast.
The contribution of this paper has 4 aspects:
1. We propose TFAM, which dynamically adjusts the receptive field based on coarse detection.
2. The proposed PA-NMS further improves detection by fusing location-based trusted predictions.
3. We introduce an instance-level IoU loss to balance training on text instances of different scales.
4. Our proposed MOST achieves state-of-the-art or competitive performance at fast inference speeds.
Bottom-up methods divide scene text detection into two steps: 1) detect basic elements; 2) aggregate these elements to generate detection results
3. Approach strategy
Top-down methods usually follow a common object detection pipeline and output word/text line detection results directly. These methods can be further specified into two subclasses. One-stage text detectors such as TextBoxes, EAST, TextBoxes++ and RRD directly regress the text box parameters on the entire feature map and use NMS to produce the final result. Two-stage text detectors like the Mask TextSpotter series, on the contrary, follow the MaskRCNN type framework, by first using a region proposal network (RPN) to generate text boxes, and then returning the corresponding border parameters. These methods usually have a relatively simple post-processing algorithm that avoids complex aggregation steps.
LOMO proposes an iterative refinement module (IRM) to perceive the entire long text through iterative refinement. It extracts multiple RoI features based on the preliminary proposal to form a multi-level detector.
It extracts multiple RoI features based on the preliminary proposal to form a multi-level detector
PA-NMS stands for position-aware non-maximum suppression.
Experiment: Comparing SimCLR vs. Non-SimCLR for comparison
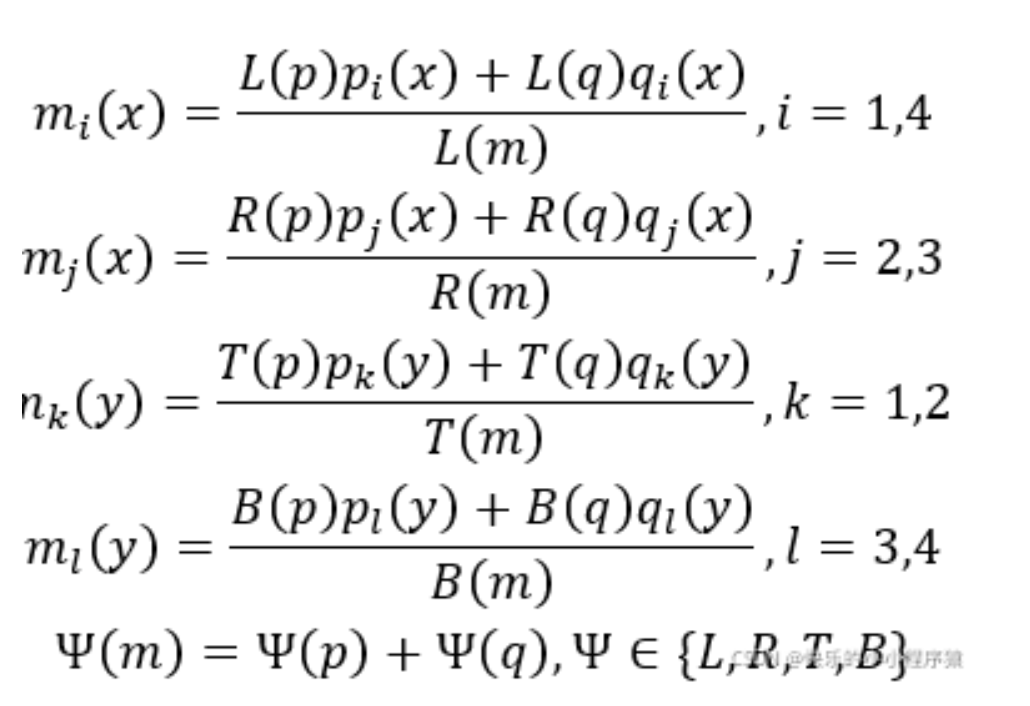
3.1 Supervised Learning
| DataSets: | public datasets of handwriten and scene text recognition. | Handwriten:IAM and CVL and French dataset RIMES |
| Scene dataset: syntheic dataset SynText and test IIT5K,IC03 and IC13 |
This work proposes a contrastive learning method: SeqCLR, for text recognition. Treating each feature map as a series of independent instances leads to contrastive learning at the sub-word level, e.g. extracting several positive pairs and multiple negative examples per image. In addition, to obtain effective visual representations for text recognition, new augmentation heuristics, different encoder architectures, and custom projection heads are further proposed.
Experiments on handwritten and scene texts show that the proposed method outperforms non-sequential alignment methods when training a text decoder with learned representations. Furthermore, when the amount of supervision is reduced, SeqCLR significantly improves performance compared to supervised training, and when fine-tuned with 100% labels, SeqCLR achieves state-of-the-art results on standard handwritten text recognition benchmarks.
3.2 Position-aware non-maximum suppression
Text and non-text can have scores S(p), S(q). And the corresponding weights are p(i) and q(i)
We propose position-aware NMS, which keeps accurate parts of detected boxes while removing inaccurate parts according to their positions during merging.
PA-NMS uses the value of the corresponding position-aware score, instead of the text/non-text classification score, as the weight of the box in the position-aware merging process, which can help to precisely locate the text boundary.
4. Experimental results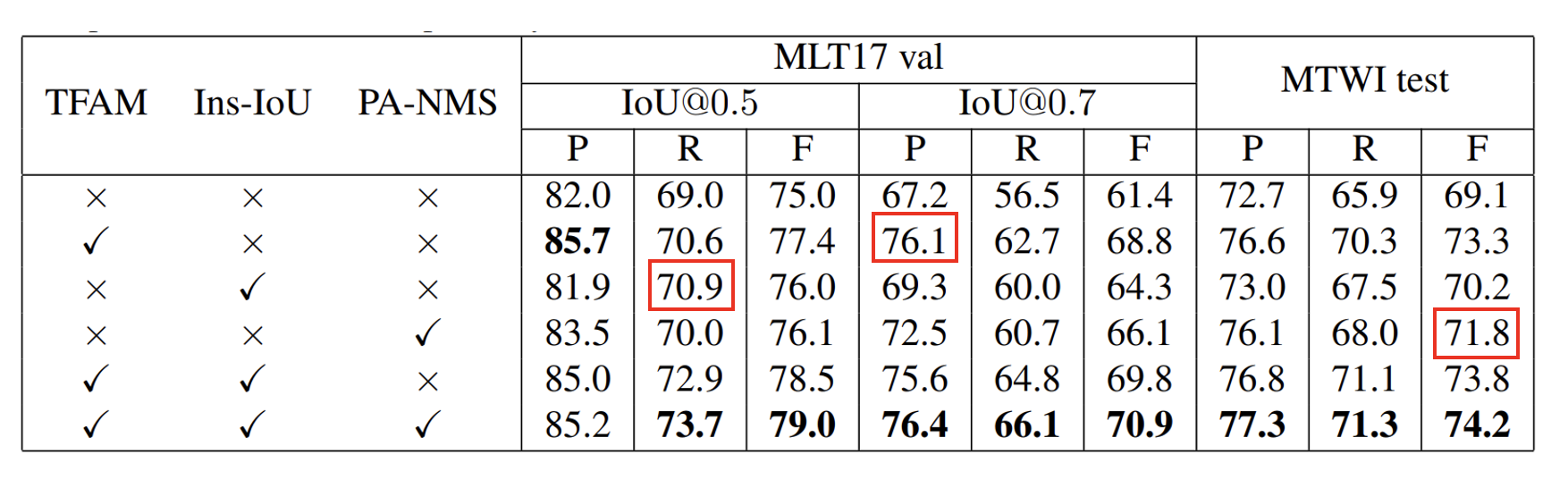
It can be clearly seen that either it is almost parallel to the baseline, or it is higher than the general baseline. But the speed exceeds the general training.
renderings

Intelligent Recommendation

EAST: An Efficient and Accurate Scene Text Detector implementation
URL:https://github.com/argman/EAST Test with the trained model python eval.py --test_data_path=tmp/images/ --gpu_list=0 --checkpoint_path=tmp/east_icdar2015_resnet_v1_50_rbox/ –output_dir=tmp/ou...

OCR paper reading notes 01--multi-oriented scence text detection via corner localization and regin segmentation
https://arxiv.org/abs/1802.08948 Topic: Multi-scene text detection based on corner location and regression Abstract: (1) At present, text detection methods based on deep learning are mainly divided in...

[Learning] paper Feature Pyramid Based Scene Text Detector
Feature Pyramid Based Scene Text Detector Publications: ICDAR 2017 Author: MengYi En, Beijing University of Technology Content: OCR, text detection in multi-scale scene Abstract Question: CNN network ...
[Paper reading] EAST: An Efficient and Accurate Scene Text Detector
Task: Text detection (can detect slanted text) contributions Proposed an End-to-End full convolutional network to solve the text detection problem Can generate geometric annotations in two formats: qu...
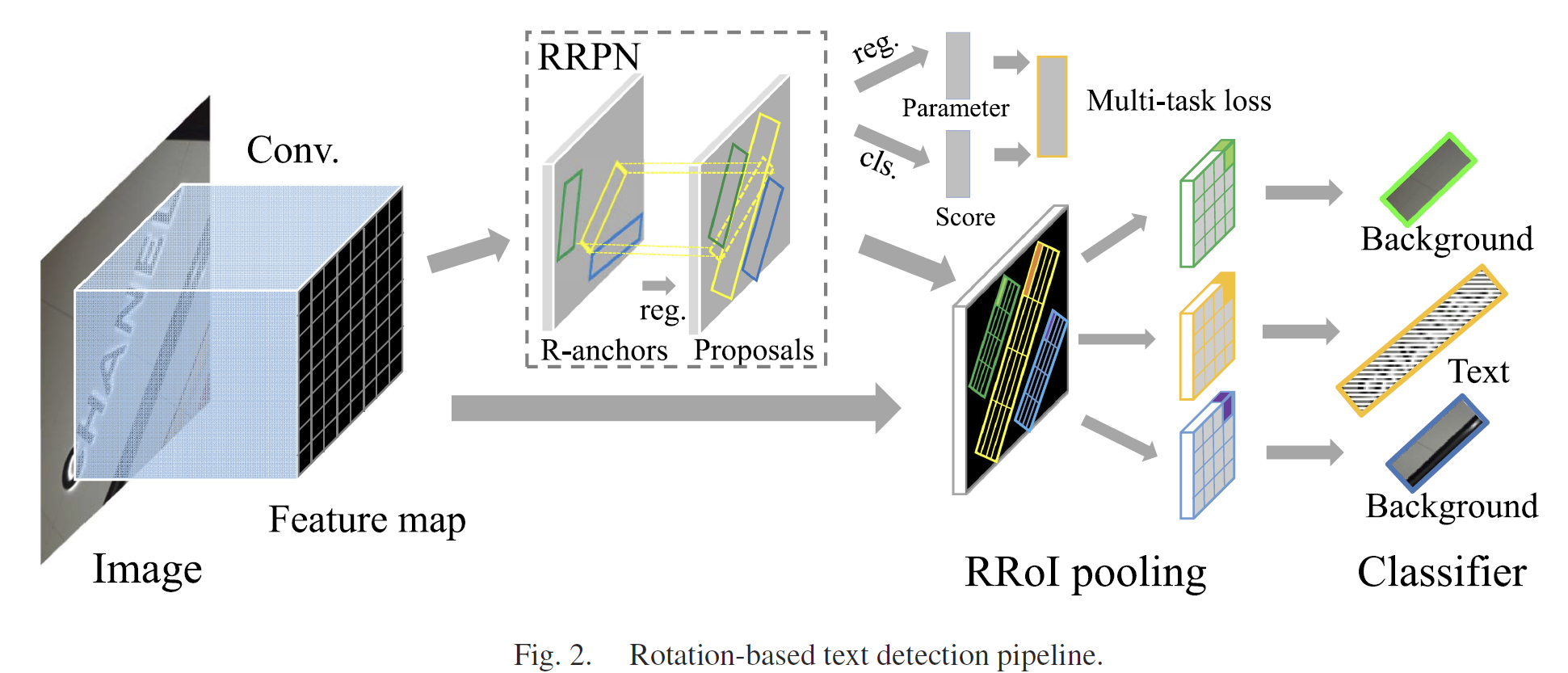
[Paper] RRPN: Arbitrary-Oriented Scene Text Detection
I. Introduction (1) Main content This paper introduces a rotation-based approach and an end-to-end arbitrary-orientation text detection system that can generate arbitrary-orientation candidate boxes d...
More Recommendation

The most complete Sublime Text localization and plug-in installation collection in history
5. Sublime Text plugin installation The installation of Sublime Text plug-ins is basically divided into two methods. The first is to directly find the Sublime Text plug-in directory, and then drag you...
EAST: An Efficient and Accurate Scene Text Detector (text recognition in natural scenes) training, testing
First introduce my environment configuration, ubuntu16.04+cuda9.0, cudnn7.0, tensorflow-gpu=1.8 Introduction In fact, this is not very researched, just to participate in an Ali Tianchi competition, an...

EAST: An Efficient and Accurate Scene Text Detector Text recognition in natural scenes (principle and code understanding)
Recently, I am studying text recognition in natural scenes, and there is a relatively new model EAST, so I will learn it. Original address of the paper:https://arxiv.org/abs/1704.03155v2 Source code:h...
[Training test process record] SSD: Single Shot Detector for scene text detection
Introduce the use of SSD model for scene text detection. Example data set: COCO-Text. Compilation part: 1. Error when compiling with cuda8 /usr/include/boost/property_tree/detail/json_parser_read.hpp:...

Lukas Neumann——【ICCV2017】Deep TextSpotter_An End-to-End Trainable Scene Text Localization and Recogn
Lukas Neumann——【ICCV2017】Deep TextSpotter_An End-to-End Trainable Scene Text Localization and Recognition Framework Download Code: https://github.com/MichalBusta/DeepTextSpotter Method Ove...