[Learning] paper Feature Pyramid Based Scene Text Detector
tags: OCR TEXT DETECT
Feature Pyramid Based Scene Text Detector
Publications: ICDAR 2017
Author: MengYi En, Beijing University of Technology
Content: OCR, text detection in multi-scale scene
Abstract
Question: CNN network in the text detection, low-level details of the high-level feature map is lost, resulting in a small target detection poor results.
Embodiment described herein: A new text based pyramid feature detector (Feature Pyramid based Text Detector, FPTD). The framework is based SSD (Single Shot Detector) target detection algorithms, but the binding characteristics of pyramid idea, to adopt a top-down feature fusion strategy to get new features, contains both a strong ability to distinguish high-level semantic information but also contains low-level features High resolution and full details of the features.
General process: text detection feature may independently occur on a plurality of fusion, non-maximal suppression results (Non-maximum Suppression, NMS) then pooled and then, due to the characteristics of FIG from different layers, which contain high-level semantic information, and different scales, so that the frame can be processed at different scales text detection scenarios.
Experiments Conclusion: This paper frame in the case of a weak increase in overhead, ICDAR2013 text in the calibration data set to achieve good results on.
ps: Actually this article is the application of FPN network in the OCR field. Framework of this idea is completely borrowed from the characteristics of pyramid network.
Feature Pyramid Networks for Object Detection,CVPR2017
Introduction
Compared to conventional OCR (optical character recognition), recognition and text location in complex scenes, there are many difficulties, such as text distortion by
Image blur, unevenness of light, the background is complex, interleaved character, character size and direction changing color problems.
CNN has a strong ability to learn features, but shortcomings in the multiscale detection problem. This paper presents a fusion wherein the layers wherein Fig pyramid level method for detecting a scene text of different scales.
The main contribution of this paper:
- Detection framework proposed a new end to end multi-scale scenario text
- The first scene features the pyramid into the text field of detection
Related Work
Object detection algorithm based on the depth of the network, the scene text detection algorithm and multi-scale features of the problem - progress research focuses on three aspects of the presentation.
Target detection algorithm depth of the network
- R-CNN. CNN used for the mountains Object detection, access to great accuracy improved, but the great time overhead.
- Fast R-CNN. FIG feature extracting only once for each view so as to enhance the speed of the detection algorithm.
- Faster R-CNN, the introduction of the recommended area network (Region Proposal Network, RPN), once again raise the basic rate to achieve real-time.
- YOLO. The target detection regarded regression problem, the whole picture input directly predicted object bounding box (Bounding Boxes), and predict the likelihood of categories on the uppermost characteristic graph (Feature Map). Although the expense of some accuracy, but to achieve real-time speed.
- SSD. Use multi-scale layers of different characteristics designed for different anchor block (anchor boxes) regional recommendation. Greatly improves the detection accuracy while maintaining an efficient algorithm.
In recent years, thanks to the development of object detection algorithms, scene text detection algorithm based on depth of the network is gaining popularity.
- "Serge Belongie. Detecting Oriented Text in Natural Images by Linking Segments". Full convolution Network (Fully convolutional network, FCN) is introduced into the extracted features for text. And to provide a text element is decomposed into two partial detectable, Segments (debris) and links (connections), while in the prediction CNN, after then combined to obtain the final detection result.
- "Deeptext: A unified framework for text proposal generation and text detection in natural images" text detection framework is proposed Faster R-CNN based on the design of a paper inception-RPN, for the proposed text region multiscale convolution .
- "Arbitrary-Oriented Text Detection via Scene Rotation Proposals" proposes a framework based on the detection Faster R-CNN multi-directional text.
- "A Fast Text Detector with a Single Deep Neural Network", "Deep Matching Prior Network: Toward Tighter Multi-oriented Text Detection" SSD based multidirectional text detection.
Multi-scale problems Target Detection
The traditional way is the image pyramid as input, but the depth of the network of multi-scale images simultaneously input memory consumption is too high. GoogLeNet using multi-scale filter in a single multi-scale-scale image to solve the problem. Faster R-CNN to deal with different scale and multi-scale problem by introducing a different aspect ratio of anchor boxes, but because of its characteristic from the final convolution of FIG layer, resulting in coarse resolution, small target detection performance impact.
FCN, HyperNet, ParseNet, RCF and FPN and other methods have been proposed to solve the scale problem of target recognition.
Methodology
1. CNN system
FPTD proposed as shown in FIG. SSD based framework, the networks VGG-16, but becomes a full fc6 fc7 and convolution layer connection layer, and additional layers (from conv6_1 to pool6)

Body next to the network adds several new layers, forming a bypass. Deconvolution layer comprising, an element accumulating layer, and novel features of the build-up layers. Pictures from entering the network through two paths through the network. A main frame network (Backbone) feature extraction is completed, the bypass layer construction of new features.
With the deepening network, main frame extracted features reduced-resolution, low-level details gradually lost, but the semantics strengthened. Forming a pyramid characteristic features different from building a new bypass path corresponding to the network layer.
2. Construction of the new features of the pyramid strategy
By way of high-level and low-level details of the full integration of space at the same time get rich semantic information features. However, the integration of the different layers of map features the face of a problem: features views of different layers are usually obvious differences in scale and size (activation layers available statistics, see below Table1). Such as high and low levels obtained directly fused FIG characteristics, it is obtained from the results obtained in FIG wherein "large value" lead (i.e., a small value that the information layer is little effect).

The following figure illustrates the process of feature fusion. FIG high resolution first feature deconvolution, so that two part size (resolution) fit. And then the high-resolution low-level features of FIG do Convolution. The last two sections are added as the element. The result again a Wherein the convolution of the final fused FIG.

Here Convolution role is as follows:
- Uniform number of channels in different layers. (3-dimensional convolution on? Obtain characteristic diagram of a single channel?)
- FIG feature value adjusted to the different layers within an appropriate range.
The following figure seen through Convolution statistic activation of the different layers substantially achieve a similar range.

After then through a Convolution to extract more semantic information, while reducing the adverse effects on sampling.
3. The text detection
- Pool6 selected on the network backbone, conv8_2, conv7_2 layer, and a bypass on the new network built conv6_2, new built fc7 and new features Built FIG conv7_2 layer is text detection.
- Each location (pixel) on the feature map is associated with a series of prior boxes. Each prior boxes are covered with a partial region of the input image.
- Each of which is used as a detection feature map are connected to two Convolution layer, a confident prediction do with each prior box scores. Compensation prediction is used as a coordinate (prior box size adjustment).
4. Learning process
Classified by the loss function loss and positioning loss consists of:
N is a positive number of prior sample boxes, Using L1 loss, 2 classification using the softmax loss. Weight is a key here is set to 1.
Experiments
Text positioning tasks ICDAR 2013 conducted a series of experiments, the use of scene text database. Assessment protocol is to assess the scale of ICDAR2013.
1. Dataset
Two sets of data throughout the experiment.
- SynthText: synthetic dataset. It contains 800,000 images, 8 million synthetic statement instance text. The data set is used to pre-train model.
- ICDAR 2013: The data set used for training FIG comprising 229, 223 for the test of FIG. For fine-tune the model pre-trained on, and then the test set ICDAR 2013 dataset evaluation model.
2. Implementation Details
- FPTD using pre-trained on Model VGG-16 ILSVRC CLS-LOC data set, using the training The single-scale images.
- Small batches using stochastic gradient descent optimization algorithm (Mini-batch stochastic gradient descent, MSGD).
- Momentum is set to 0.9, weight decay set .
- Training Phase I: with a pre-trained networks VGG-16 model initialization, then SynthText for 55,000 iterations on the training data set, before learning rate of 0.001 35,000 iterations, the next iteration of learning 5000 was 0.0005, the final 15,000 iterations using the learning rate of 0.0001.
- The second phase of training: 1000 times fine-tune data collection on ICDAR 2013
- Since the fusion process wherein elemental FIG addition operation, so FPTD input image size must be a power of 2 (to prevent loss of vertical sample size, and thus can not be fused).
3.Experiments for verifying the effectiveness of the new build features
TextBox using as a reference model. Test results are as follows

4. Experiments for detecting small text
- In order to detect small targets, we constructed FPTD-5, next to the road increases conv3_3 layer.
- When tested, in order to increase small target, we will test picture reduced to
- Similarly, TextBox model is also used as an input picture 256 (TextBox-2).

5.Comparisions with other state-of-the-art methods

Here FPTD is used in the experiment FPTD-3, the method of this higher recall rate, while the F-measure indicators are also very good.
ps: This article emphasis on project implementation, new innovation is not strong, in this case, the adequacy of the experiment is very important.
Intelligent Recommendation
Pyramid Mask Text Detector reading notes
2020.9.9 Pyramid Mask Text Detector The author analyzed the problems of the previous Mask-RCNN-based method, and on this basis, proposed an improvement method and designed PMTD. problem an...

Paper note: "Pyramid Scene Parsing Network"
paper:《Pyramid Scene Parsing Network》by Hengshuang Zhao etc. There are three common problems with semantic segmentation using FCN: Mismatched Relationship: Mismatched relationship, such as identifying...

"Pyramid Scene Parsing Network" paper notes
Papers Address: https://arxiv.org/pdf/1612.01105.pdf Source Address: https://github.com/hszhao/PSPNet Application pooling pyramid divided on the meaning of words, look at the papers have mentioned ear...

Pyramid Scene Parsing Network paper interpretation
Pyramid Scene Parsing Network link https://hszhao.github.io/projects/pspnet/ 1. Give reasons In order to solve the frequently-occurring problems in image analysis and semantic segmentation of commonly...
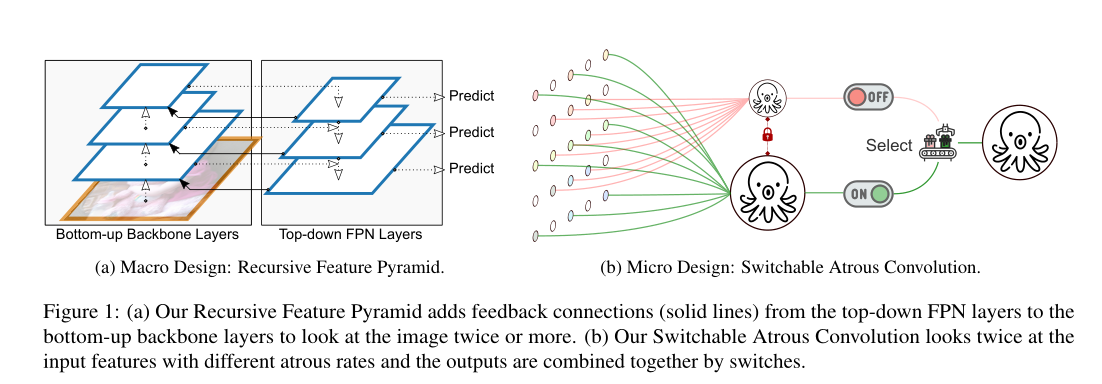
Detector: Detect objects with recursive feature pyramid and switchable Atoros convolution
Abstract Many modern target detectors have adopted the "thinking" mechanism, showing excellent performance. This article applies this mechanism to the backbone design of target detection. At...
More Recommendation
EAST Interpretation - An Efficient and Accurate Scene Text Detector
Article directory Brief Existing work problem data set Network structure Feature extraction layer Feature merge layer Result output layer Tag generation Loss function Text segmentation Loss RBOX bound...

[ ]EAST: An Efficient and Accurate Scene Text Detector
1 Overview EASTThis is one of my favorite papers related to text detection this year, because a great god has reappeared[2]And easy to learn. The reason for liking is mainly in the results, there are ...

EAST: An Efficient and Accurate Scene Text Detector
Questyle's works at CVPR2017 Advantage: Provides direction information, can detect text in various directions Disadvantages: The detection effect is not good for long text, and the feeling field is no...

EAST: An Efficient and Accurate Scene Text Detector implementation
URL:https://github.com/argman/EAST Test with the trained model python eval.py --test_data_path=tmp/images/ --gpu_list=0 --checkpoint_path=tmp/east_icdar2015_resnet_v1_50_rbox/ –output_dir=tmp/ou...

Natural scene text recognition based on deep learning
Statement: The source of this article, please refer to the original blog post for details. 1.1 Introduction Traditional optical character recognition is mainly for high-quality document images....