"TextBoxes++: A Single-Shot Oriented Scene Text Detector" paper notes
1 Overview
The method given in this article is to solve the problem of rotating text detection. Therefore, the method TextBoxes++ of the article can detect slanted text. The method of detecting text is represented by an angled rectangular box or a quadrilateral box. Since this method is derived from SSD, this network is straight-through, and it is not an understanding network similar to Faster R-CNN. The natural speed is very fast. The author has a resolution of Resolution ICDAR 2015 data set measured 11.6FPS and F-Measure=0.817, in The COCO text data set measured 19.8 FPS and F-Measure=0.5591.
Prior to this, the author of the paper also published a version called TextBoxes. The method of the paper has four improvements compared to the previous TextBoxes:
- 1) The original TextBoxes support horizontal detection, and now support the detection of angled text;
- 2) Optimize the network structure and training process, which further improves performance;
- 3) In order to show that Textboxes++ has better performance of text detection at any angle in natural scenes, more comparative experiments were done;
- 4) Integrate the detection and recognition information to optimize text detection and character recognition;
The relationship between SSD and TextBoxes++:
TextBoxes++ is derived from SSD. SSD does not perform well when detecting some texts with extreme length to width ratios. In TextBoxes++, a specially designed textbox layer is used to solve this problem. Therefore, compared with SSD, the detection performance has been further improved.
SSD can only generate candidate boxes in the horizontal direction, and TextBoxes++ can generate a rectangular text detection box with a rotation angle or a general quadrilateral detection box to adapt to the text with rotation.
The basic idea of returning:
In fact, TextBoxes++ still uses the rectangular box when matching with the GT box. The candidate box formed by the anchor returns to the horizontal rectangular box and quadrilateral box surrounding the GT. The benefits brought by this are The optimization strategy is simple and there are few candidates for each region.
The main contribution of the article:
- 1) Propose a new curved text detection model TextBoxes++, which has the characteristics of fast, accurate and end-to-end training
- 2) Provide research on detection frame representation, model configuration, and effects of different evaluation methods;
- 3) Use the results of recognition to optimize the results of text detection, which was not available in previous research.
2. Implementation method
2.1 Method network structure

As can be seen from the above structure, this structure is very similar to the original SSD method. The author's main focus is on the detection optimization of rotating text and the adaptation of the extreme length-width ratio detection frame. Since the network is composed of convolution and pooling layers, the benefit is that the network can accept images of any scale as input without worrying about the size of the input image.
2.2 Boundary box expression and regression
First define three boxes here: . It represents quadrilateral prediction box, rotating rectangular box and minimum horizontal bounding box respectively, and the minimum horizontal bounding box is obtained by regression of the default bounding box. What needs to be explained here is:Rotating rectangular frame and quadrilateral rectangular frame are separately regression, they are paired with horizontal rectangular frame to return. The expression of these three boxes is:
- 1) , Represents the center of the bounding box, and the nature behind represents the width and height of the bounding box.
- 2)
- 3)

2.2.1 Processing of quadrilateral frames
Then for the quadrilateral box, the variables it needs to return are:
, Its kind
Is confidence. Then for a quadrilateral box
The regression of can be expressed as:

2.2.2 Processing of rotating rectangular frame
What needs to be explained here is that for a rotating rectangular frame, the meaning is to use two points to determine the top two vertices of the rotating rectangular frame, plus a height to indicate a rotating rectangular frame. Its four vertices are expressed as:

Then the variables that need to be returned for rotating the rectangular frame are:
, Its kind
Is confidence.

2.2.3 Treatment of dense detection area
The aspect ratio used in the paper for the generated default bounding box is:
. For some dense cases, see Figure 4 below. The default bounding box does not well frame the text area. Therefore, the article adds an offset to the default bounding box to adapt accordingly.

2.2.4 Choice of convolution kernel shape
For the horizontal box, the shape of the convolution kernel is , But for the article with rotation, the choice is 。
2.3 Network training
The loss function of the network: The loss function is obtained by adding the positioning loss and the classification loss.

Set here for quick convergence
。
Data augmentation: Random cropping using the original data will produce the results in Figure 5 (a, b). Naturally, such results are difficult to conform to the form of text in the real scene, so the article has improved it.

This is used
Represents the bounding box,
Represents the GT box,
On behalf of Jaccard overlap,
Represents object coverage. Then the relationship between them is:

Multi-scale training: As mentioned above, because the framework proposed in the article only contains convolution and pooling operations, multi-scale training can be used to allocate the proportion of large and small targets in the training data set, thus showing better adaptation to small targets. Sex.
**Bounding box regression adds identification information: **(a, b) in the following figure 6 has the same IoU but the recognition results are not the same, so an idea given in the article It is to use the recognition results to further optimize the detection results, and finally obtain the results like (c).

3. Experimental results
3.1 The performance of the network on some data sets
Positioning performance:


operation hours:

F-measures:

3.2 The performance of network combination recognition

Intelligent Recommendation

Paper interpretation: SSD: Single Shot MultiBox Detector
Codes provided in the paper is available at: https://github.com/weiliu89/caffe/tree/ssd Papers link:SSD:Single Shot MultiBox Detector Video Tutorial: The paper's contributions: Faster than the mo...

"SSD-Single Shot MultiBox Detector" paper interpretation
"SSD-Single Shot MultiBox Detector" paper interpretation table of Contents "SSD-Single Shot MultiBox Detector" paper interpretation brief introduction SSD300 Architecture Detection...

[Paper notes] Arbitrary-Oriented Scene Text Detection via Rotation Proposals
Arbitrary-Oriented Scene Text Detection via Rotation Proposals Paper address:https://arxiv.org/abs/1703.01086 github address:https://github.com/mjq11302010044/RRPN This paper is based on the faster-rc...
[Interpretation of the paper] Pixel-Anchor: A Fast Oriented Scene Text Detector with Combined Networks
Perface Recently, I was curious about the detection problem of large and long text lines in the text detection of the scene. So I investigated the detection results of the ICDAR2017MLT data set and fo...
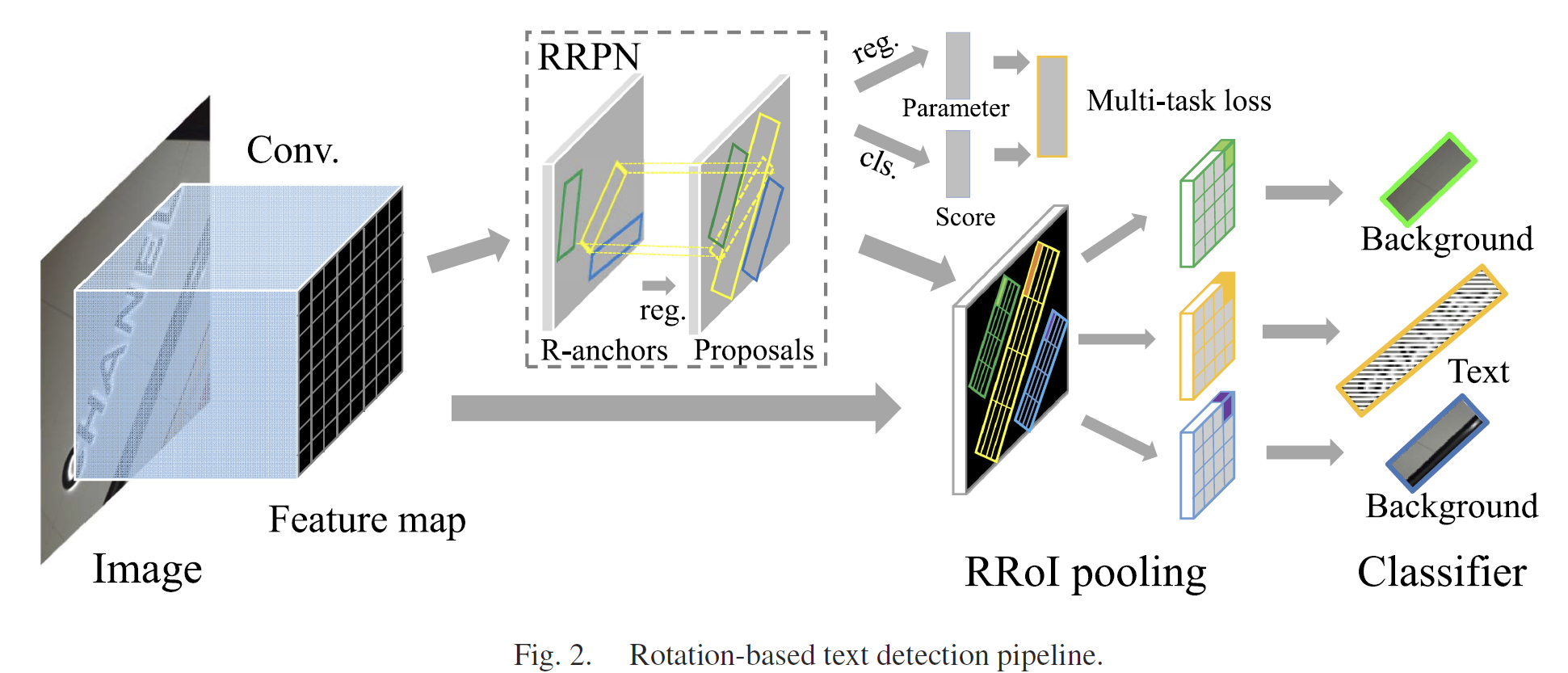
[Paper] RRPN: Arbitrary-Oriented Scene Text Detection
I. Introduction (1) Main content This paper introduces a rotation-based approach and an end-to-end arbitrary-orientation text detection system that can generate arbitrary-orientation candidate boxes d...
More Recommendation
Introduction to the text detector paper --- Scene Text Detector Overview
Introduction to the text detector paper --- Scene Text Detector Overview Overview Methods Summary Pixel based (segmentation) Anchor based Fusion I have recently begun to explore the algorithm of text ...

"SSD: Single Shot MultiBox Detector" study notes
SSD paper notes statement of problem: 1 (refer to the author's ppt), the network does not appear before the SSD, and similar Faster R-CNN YOLO are currently more popular algorithm. However, it still c...
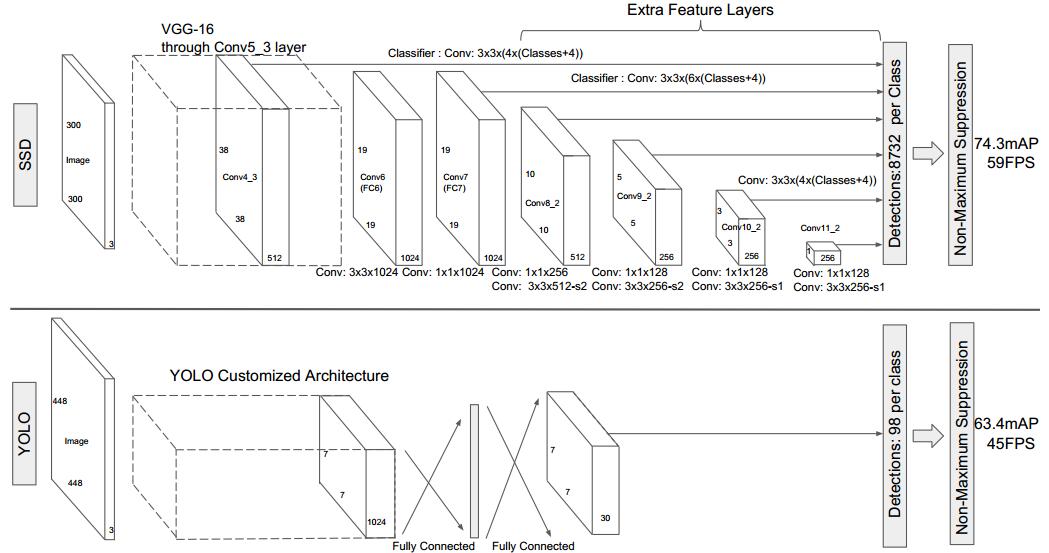
SSD (Single Shot MultiBox Detector) notes
This article is reprinted for the convenience of future reference. The original address http://blog.csdn.net/qq_14845119/article/details/53331581, thank you for sharing! This method comes from a 2016 ...

SSD_ Single Shot MultiBox Detector Papers Notes
background Task: Using a single depth neural network, accelerate prediction speed, maintain accuracy Keywords: The Single Shot Detector (SSD) Introduction Take FASTER-RCNN as an example, although th...

"SSD: Single Shot MultiBox Detector" reading notes
Target detection algorithm reading notes SSD: Single Shot MultiBox Detector WeChat public account: Deepthinkerr QQ: 2454409598 (WeChat official account does not respond in time, if you have any questi...