EAST Interpretation - An Efficient and Accurate Scene Text Detector
Article directory
Brief
EASTIt is a scene text detection algorithm of CVPR in 2017. Its features are: simple structure, fast speed, end-to-end, etc., there is a good complex modern code on Github, which is a kind ofVery practicalText detection algorithm.
- paper:https://arxiv.org/abs/1704.03155
- code(tesorflow):https://github.com/argman/EAST
- code(pytorch):https://github.com/songdejia/EAST
EASTThe name is taken from "Efficient and Accurate Scene Text", which can be used to detect text of any size, in any direction (horizontal and tilt). The main implementation ideas are:FCN Network + Locality-Aware NMS. The algorithm discards many unnecessary intermediate steps and implements end-to-end training and optimization: FCN directly performs prediction and regression, and there is no post-processing (except for candidate region aggregation and word segmentation) except for "Thresholding & NMS".
Existing work problem
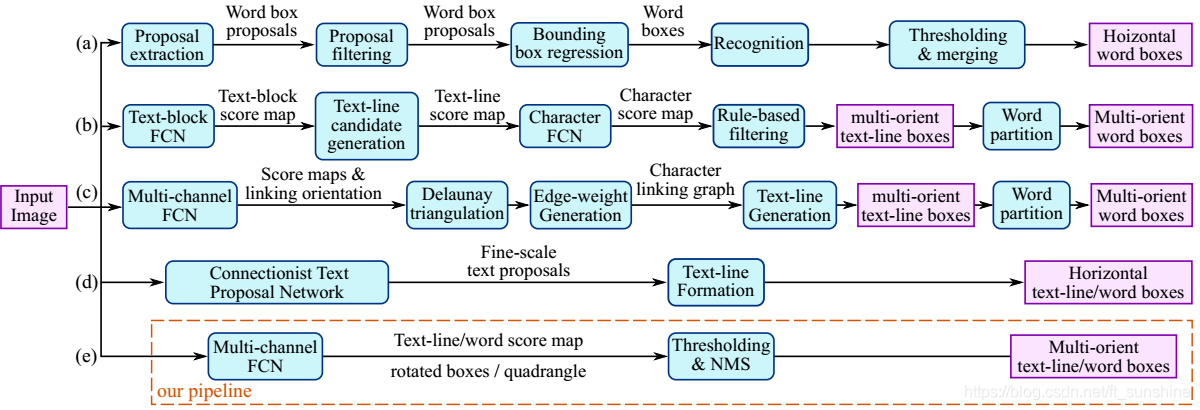
As shown above, this article summarizes the workflow (ad) of some existing methods, most of which consist of multiple stages, and some structures produce intermediate results, not end-to-end, so these Most of the existing methods are not fast and there is no way to achieve sub-optimal. This paper designs a two-stage scene text detection model.EAST(e) Its main contributions are:
- A model based on FCN is proposed. This model only needs two stages (full convolution network and NMS) to complete the task of scene text detection and the whole end-to-end structure.
- The framework is flexible enough to generate Axis-align Bounding Box (AABB) and Rotated Box (Rotated Box,RBOX) and any quadrilateral (Quadrangle,QUAD) Several predictions.
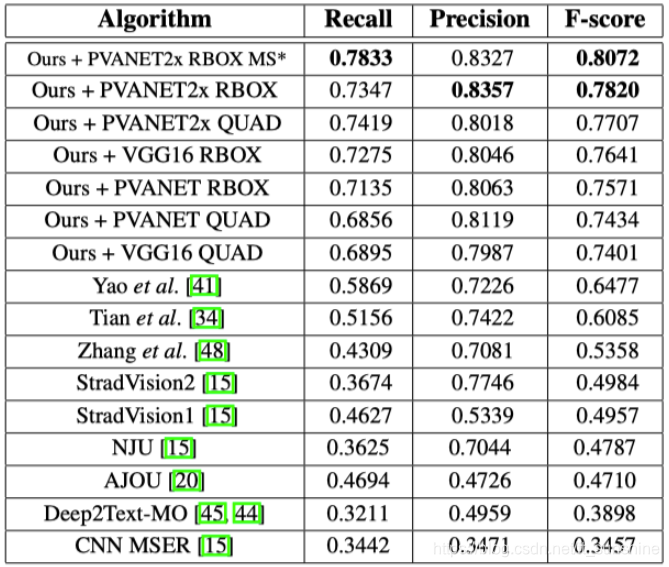
- The article was tested on ICDAR2015, COCO-Text, MSRA-TD500, and the effect reached State-of-the-art. The F-score value on ICDAR2015 reached 0.7820, which is much more than the existing methods.
data set
At present, the scene text detection has many data sets, different languages, scenes, shooting equipment, etc., and the famous data sets are as follows:
- ICDAR 2015
- COCO-Text
- MSRA-TD500
These data sets are more commonly used, using 1) rotating rectangles 2) any four-sided labeling, but there are also some datasets with more flexible annotations, such as curved shape text, which can be used for more elaborate algorithms:
- Total-Text
- SCUT-CTW1500
Network structure
The network structure of EAST is as follows:
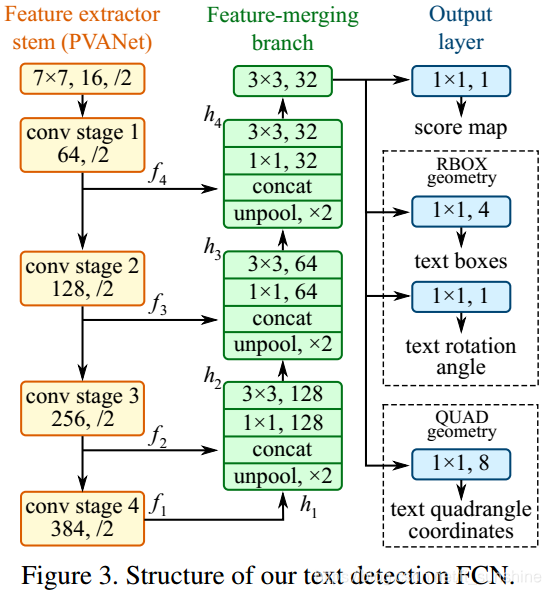
Here, the entire network structure of EAST is simply divided into three layers: feature extraction layer, feature merge layer, and result output layer.
Feature extraction layer
EAST is mainly basedU-Net, its backbone network Encoder uses PVANet or VGG, the main reason for using PVANet is to increaseFeel the wild(relative to VGG), making it useful for detecting long text. Regarding U-Net, you can search for it yourself.
Feature merge layer
U-shape is gradually combined with feature graphs of different scales to solve the problem of dramatic scale transformation of text lines. Please refer to EAST's network structure diagram or refer to U-Net for details.
In the feature merging part, the feature maps of different sizes obtained before step by step, in each merging stage, the feature map from the previous stage is first unpooling to increase the size of the feature map, and then concate with the current feature map (that is The number of channels is connected in series). Then, use one The convolution layer reduces the number of channels and reduces the amount of computation, followed by a The convolutional layer fuses the information and ultimately produces the results of this consolidation phase. After the last consolidation phase, use one The convolutional layer produces a feature map of the final merged portion and inputs it to the output layer. Its calculation formula is as follows:

Result output layer
Let's talk about the score map + geometry map, the rightmost blue part of the image above:
- For the detection shape RBOX, the output contains a score map and a text shape (AABB boundingbox and rotate angle), that is, there are 6 outputs together, where AABB indicates the relative to the top, right, bottom, left sides respectively. shift.
- For the detected shape is QUAD, the output contains the score map and the text shape (eight offsets from the corner vertices), that is, there are 9 outputs together, of which QUAD has 8 。
Note:Choose one of RBOX and QUADThe general RBOX effect will be slightly better.
The role of each channel is illustrated in the following table: (The AABB part is not drawn in the figure, in fact, AABB is RBOX
Case)

Tag generation
Next, we will explain the method of generating the label (GT) for each channel. Let us take RBOX as an example. The following is the learning target generation process of RBOX:
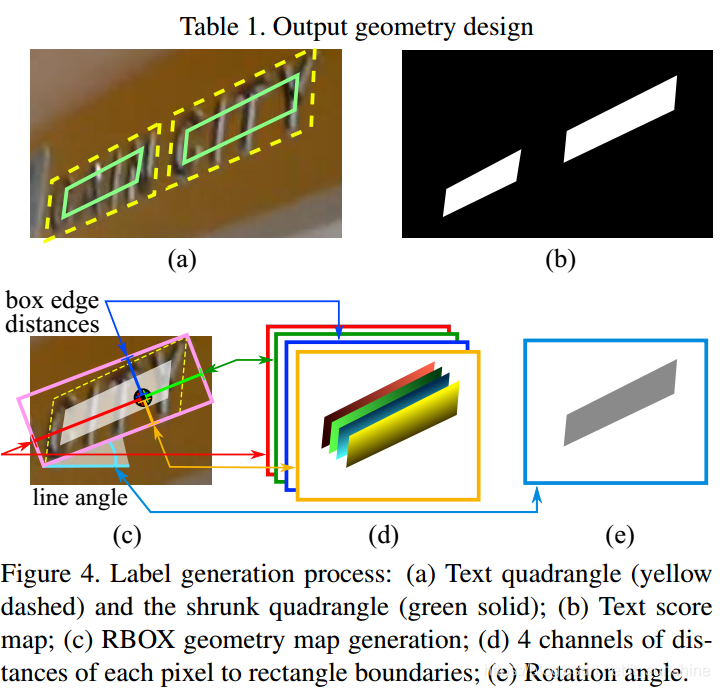
- For any quadrilateral labeling, reduce some inward (0.3 times used in the text) and generate a split Mask (Figure b).
- For each point in the Mask (note that only considerpositive pixel! ! ), generating four regression coordinates, which are the distance offsets (d1, d2, d3, d4) from the four sides of the axis-aligned bounding box.
- For each point in the Mask (still only considerpositive pixel! ! ), produces a rectangular box rotation angle 。
If it is an arbitrary quad target, the eight coordinates are the distance offsets of the four vertices of any quadrilateral to that point.
Note: The four-point labeling of the label is given in a clockwise direction, seeICDAR 2015The data can be labeled.
Loss function
The article uses different loss functions for different subtasks. For RBOX, the main tasks include text confidence regression (get score map), border offset regression (geometry map), and angular offset regression ( map)。
The total loss function of the network is:
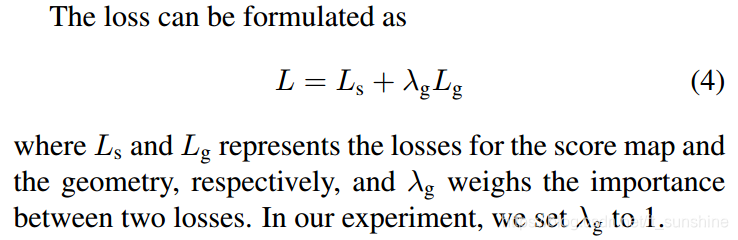
Text segmentation Loss
Different from the common target detection network to deal with sample imbalance, such as equalization sampling, OHEM and so on. EAST algorithm is adoptedClass balanced cross entropyTo solve the problem of category imbalance. (The article says that using OHEM will lead to some problems that are not guided by the stage and need to adjust more super parameters, which will make the model more complicated)
For text confidence regression (generating the loss of the score map), the article usesCategory Weighted Cross EntropyTo calculate, as follows:

where β weighting is used, the weight is determined by the ratio of positive and negative cases, and the smaller the ratio, the larger the weight. But in the actual combat, generally adopteddice lossBecause its convergence speed will be faster than the class balance cross entropy.
RBOX boundary offset Loss
For RBOX, the boundary offset Loss uses IoU loss: (The size of the text in the natural scene varies greatly, and directly using the L1 or L2 loss to return to the text area will result in a loss bias that is more likely to detect large text. In the RBOX regression (AABB part), the IoU loss is used, and the scaled normalized smoothed-L1 loss is used in the QUAD regression to ensure the geometric regression loss.Constant scaleof. )
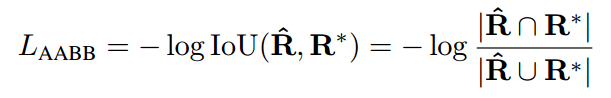
RBOX offset angle loss
RBOX also has an angle, here uses the cosine loss:
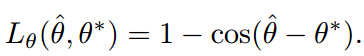
The hats in the above formula all indicate predictions, and "*" means GT. and so:
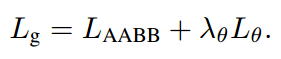
in the text
Set to 10 for.
QUAD offset Loss
For any quadrilateral QUAD, the boundary loss uses SmoothL1Loss as the loss function:
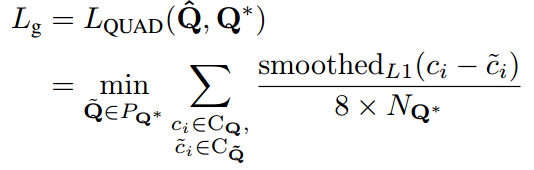
which is used
As a normalized parameter, the length of the shortest side of the quadrilateral is represented:
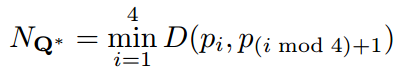
Locality-Aware NMS
Locally aware NMS, in order to reduce time complexity.
Based onHypothesis: Candidate boxes based on adjacent pixels are highly correlated. Therefore, these candidate boxes can be merged step by step, and then the conventional NMS.
After using the above training, for each point, if his score value is greater than a certain threshold, we can think that the point is inside a certain text, and then take the offset, angle, etc. to calculate the position of the box. Location, size, etc. With so many boxes, it is natural to do some heavy operations. The traditional NMS calculates the IoU for each Box and all the other boxes. The number of frames is very large, so the speed of O(n2) cannot be accepted. However, the frame predicted based on the above method (EAST) is actually quite characteristic: the frame overlap generated by the adjacent pixels is very high, but the detection frame generated by the same text is not very coincident, so this paper proposes First, merge the quads by line, and finally filter the remaining quads with the original NMS. This can greatly reduce the number of IoUs calculated during NMS, namely Locality-Aware NMS:(Locally aware NMS)

Experimental result
The text did some experiments on the ICDAR2015 dataset. Compared to other methods, this paper has improved a lot:
There is a problem welcome to communicate!
done~
References
Intelligent Recommendation
[Interpretation of the paper] Pixel-Anchor: A Fast Oriented Scene Text Detector with Combined Networks
Perface Recently, I was curious about the detection problem of large and long text lines in the text detection of the scene. So I investigated the detection results of the ICDAR2017MLT data set and fo...
Introduction to the text detector paper --- Scene Text Detector Overview
Introduction to the text detector paper --- Scene Text Detector Overview Overview Methods Summary Pixel based (segmentation) Anchor based Fusion I have recently begun to explore the algorithm of text ...
Text detection actual combat: use OpenCV to implement text detection (EAST text detector)
In this tutorial, you will learn how to use OpenCV to use the East text detector to detect the text in the image. East text detector requires us to run OpenCV 3.4.2 or OpenCV 4 on our system. Thesis o...
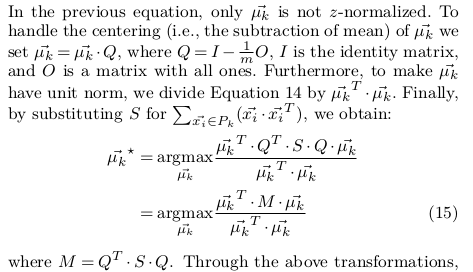
k-Shape: Efficient and Accurate Clustering of Time Series Interpretation
k-Shape: Efficient and Accurate Clustering of Time Series John Paparrizos Luis Gravano Columbia University ACM SIGMOD 2015 Main contribution Propose a new distance metric that is invariant to scale an...

Overview of natural scene text detection techniques (CTPN, SegLink, EAST)
The article is reproduced from: Foreword Text recognition is divided into two specific steps: the detection of text and the recognition of text, both of which are indispensable, especially text detect...
More Recommendation

Python+opencv+EAST to do natural scene text detection (transfer)
Mark, thank the author for sharing! English original link:https://www.pyimagesearch.com/2018/08/20/opencv-text-detection-east-text-detector/ Reminder: Author's implementation of Python's text detectio...

[Learning] paper Feature Pyramid Based Scene Text Detector
Feature Pyramid Based Scene Text Detector Publications: ICDAR 2017 Author: MengYi En, Beijing University of Technology Content: OCR, text detection in multi-scale scene Abstract Question: CNN network ...

"TextBoxes++: A Single-Shot Oriented Scene Text Detector" paper notes
1 Overview The method given in this article is to solve the problem of rotating text detection. Therefore, the method TextBoxes++ of the article can detect slanted text. The method of detecting text i...
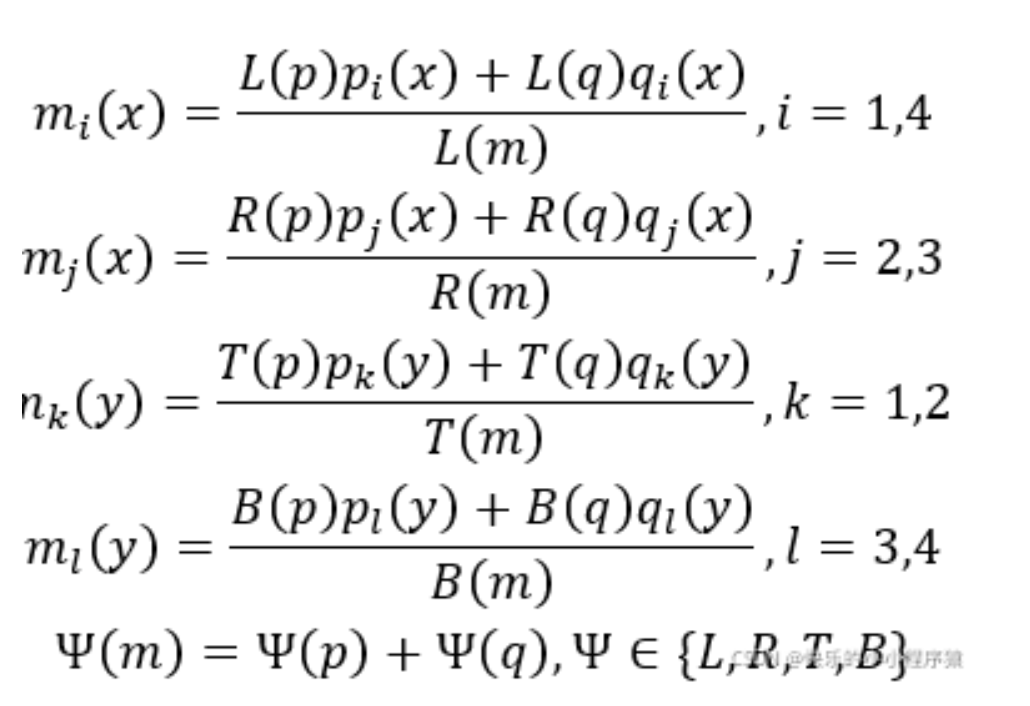
MOST: A Multi-Oriented Scene Text Detector with Localization Refinement
1 Introduction Modern text detectors are capable of capturing text in a variety of different challenging scenarios. However, they may still fail to detect text instances when dealing with extreme aspe...
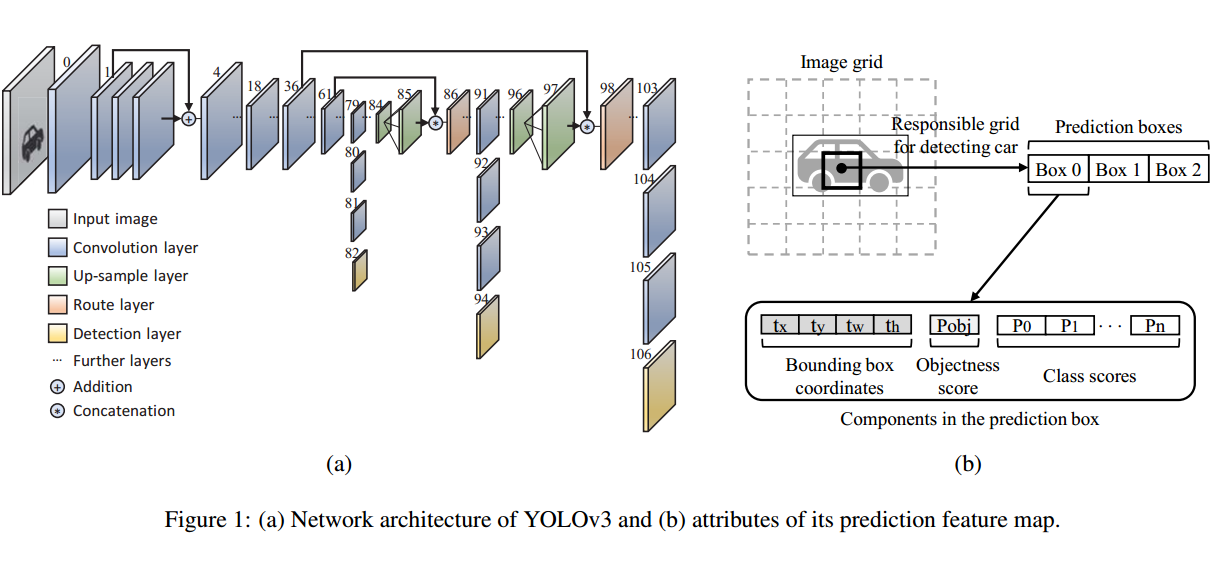
[Papers interpretation] Gaussian YOLOv3: An Accurate and Fast Object Detector Using Localization Uncertainty
Topic: Gaussian YOLOv3: An Accurate and Fast Object Detector Using Localization Uncertainty OF: Jiwoong Choi, Dayoung Chun, Hyun Kim, Hyuk-Jae Lee githud:https://github.com/jwchoi384/Gaussian_YOLOv3 I...