EAST algorithm (Efficient and Accuracy Scene Text))
tags: Text detection and recognition Deep learning
1. Introduction to EAST model
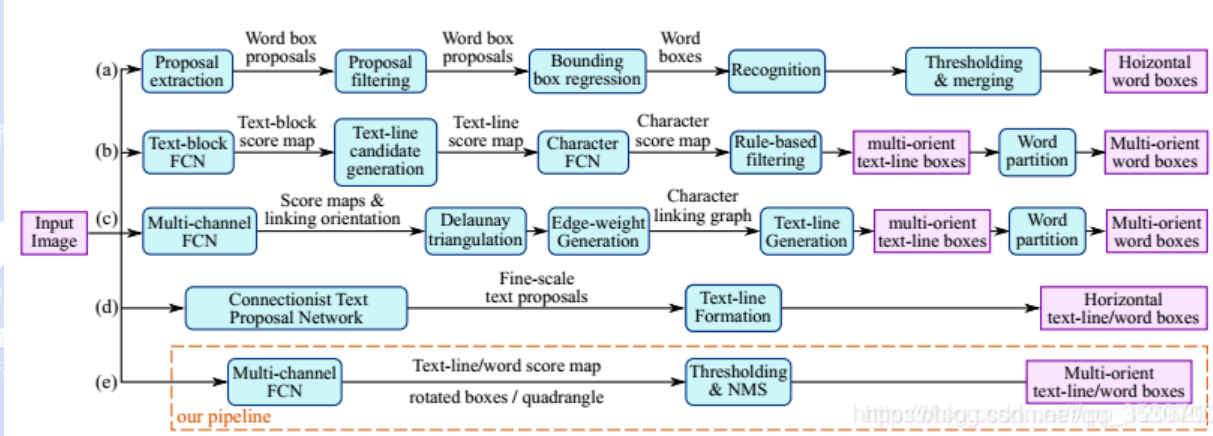
The text detection model EAST introduced in this article simplifies the intermediate process steps, directly realizes end-to-end text detection, elegant and concise, and the accuracy and speed of detection have been further improved. As shown below:
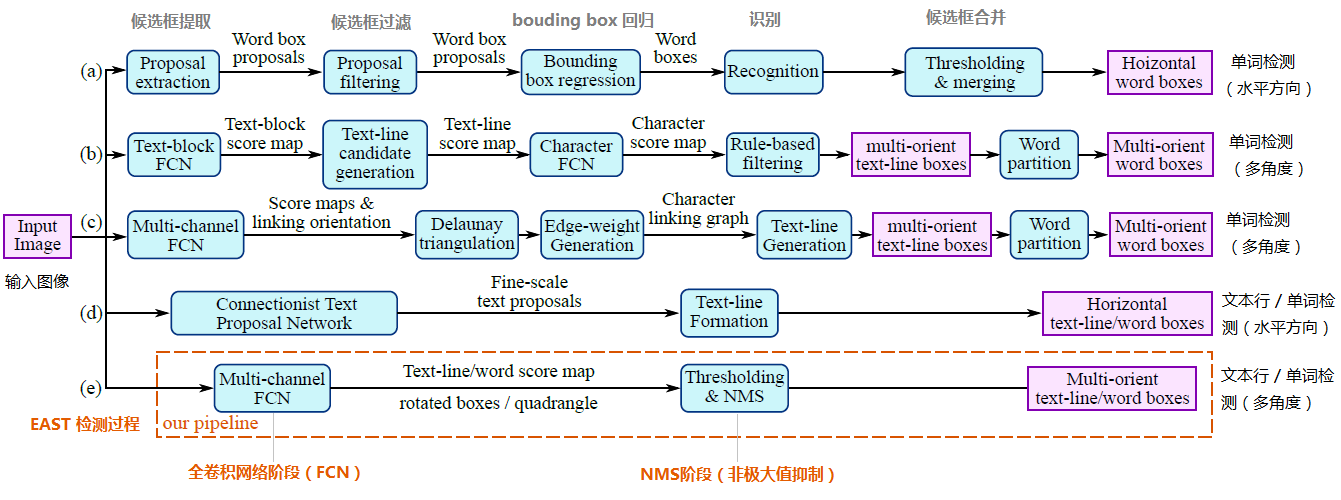
Among them, (a), (b), (c), (d) are several common text detection processes. The typical detection process includes candidate box extraction, candidate box filtering, bouding In the stages of box regression and candidate box merging, the intermediate process is relatively lengthy. And (e) is the EAST model detection process introduced in this article. As can be seen from the above figure, the process is simplified to only the FCN stage (full convolutional network), NMS stage (non-maximum suppression), the intermediate process is greatly reduced, and The output result supports multiple angle detection of text lines and words, which is not only efficient and accurate, but also adaptable to a variety of natural application scenarios. (D) is the CTPN model. Although the detection process is similar to the (e) EAST model, it only supports horizontal text detection, and the applicable scene is not as good as the EAST model. As shown below:

2. EAST model network structure
The network structure of the EAST model is as follows:
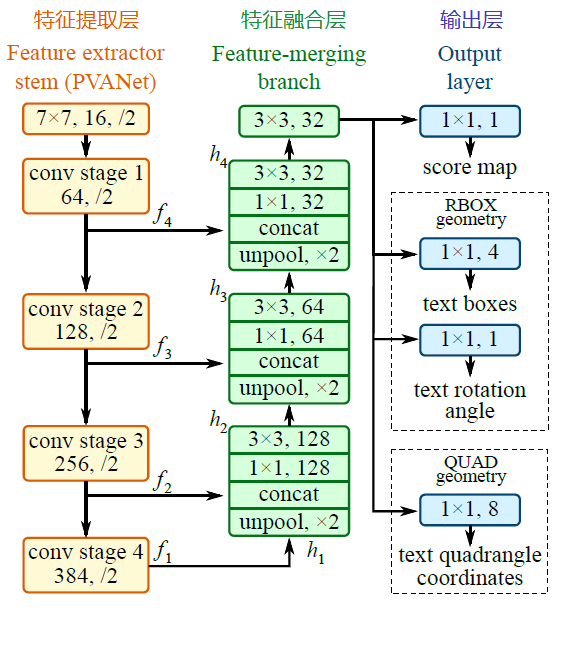
The network structure of EAST model is divided into three parts: feature extraction layer, feature fusion layer and output layer.
Expand below to introduce:
1. Feature extraction layer
Based on PVANet (a target detection model) as the backbone of the network structure, feature maps are extracted from the convolutional layers of stage1, stage2, stage3, and stage4 respectively. The size of the convolutional layer is halved in sequence, but the number of convolution kernels is in turn. Doubled, this is a kind of "pyramid feature network" (FPN, feature pyramid network) idea. In this way, feature maps of different scales can be extracted to achieve detection of text lines of different scales (large feature maps are good at detecting small objects, and small feature maps are good at detecting large objects). This idea is very similar to the SegLink model;
2. Feature fusion layer
The previously extracted feature maps are merged according to certain rules. The merge rule here uses the U-net method. The rules are as follows:
- The feature map (f1) of the last layer extracted from the feature extraction layer is sent to the unpooling layer first, and the image is enlarged by 1 times
- Then concatenate with the feature map (f2) of the previous layer (concatenate)
Then make convolutions with convolution kernel size of 1x1, 3x3 in turn - Repeat the above process for f3 and f4, and the number of convolution kernels decreases layer by layer, in order of 128, 64, 32
- Finally, after 32 cores and 3x3 convolution, the result is output to the "output layer"
3. Output layer
Finally output the following 5 parts of information, respectively
- score map: the confidence of the detection frame, 1 parameter;
- text boxes: the position of the detection box (x, y, w, h), 4 parameters;
- text rotation angle: the rotation angle of the detection frame, 1 parameter;
- text quadrangle coordinates: position coordinates of any quadrilateral detection frame, (x1, y1), (x2, y2), (x3, y3), (x4, y4), 8 parameters.
Among them, the position coordinates of the text boxes and the position coordinates of the text quadrangle coordinates seem to be a bit duplicate, but in fact they are not, this is to solve some distorted text lines, as shown below:
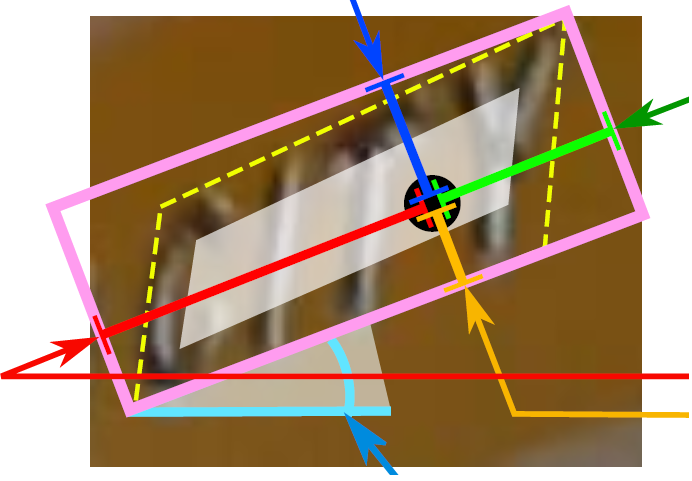
If only the position coordinates and rotation angle of text boxes (x, y, w, h, θ) are output, then the predicted detection box is the pink box in the above picture, and the real text There is an error in position. And at the end of the output layer, the position coordinates of any quadrilateral are output, then the position of the detection frame (yellow frame) can be predicted more accurately.
contains several conv1×1 operations to project the feature map of 32 channels to the score feature map Fs of 1 channel and the feature map Fg of one multi-channel geometry. The geometry output can be either RBOX or QUAD, as shown in the table:

4. Training label
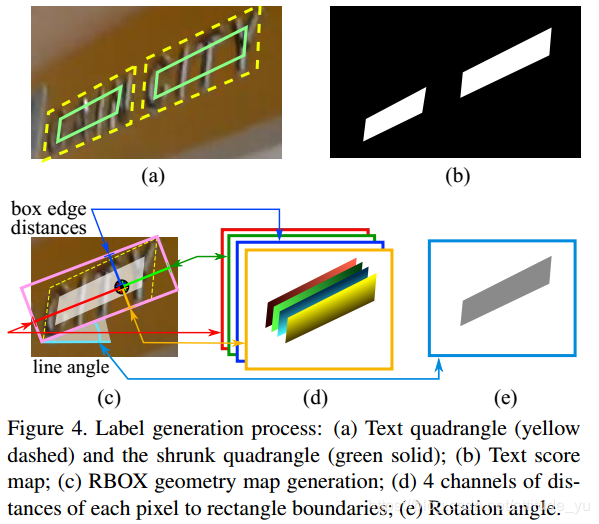
(a) Text rectangle (yellow dotted line) and reduced rectangle (solid green line); (b) Text score feature map; (c) RBOX frame geometry map; (d) Each The distance of 4 channels from pixels to the border of the rectangle; (e) Rotation angle.
Generally reduce the size of the labeling frame by 0.3 to train (reducing labeling error), as shown in (a); for the rectangle Q, where pi is the clockwise vertices of the rectangle. In order to reduce Q, the length between vertices needs to be calculated:
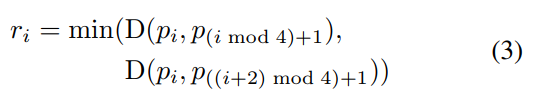
D(pi,pj) is the L2 distance between pi and pj. First shrink the two longer sides of a rectangle, then shrink the two shorter sides. For each pair of sides, the "longer" pair is determined by comparing the average length. For each edge, shrink by moving its two endpoints inward by 0.3ri and 0.3r (i mod 4)+1, respectively.
First, generate a rotating rectangle to cover the area with the smallest area; then, for the RBOX label box, calculate the distance between each pixel with a positive score and the 4 borders of the text box; for QUAD Annotate the box and calculate the coordinate offset between each pixel with a positive score and the four vertices of the text box.
5. Loss function
The loss function formula is:

Among them, Ls and Lg represent the loss of the score graph and the geometric graph, respectively, and λg represents the importance between the two losses (λg=1 in this experiment).
In the current method, most of the training images use balanced sampling and hard negative mining to solve the uneven distribution of targets. Doing so may improve network performance. However, using this technique will inevitably introduce a stage and more parameters to adjust the pipeline, which contradicts the design principles of this article. In order to simplify the training process, this article uses class-balanced cross-entropy (used to solve class imbalance training, β=counterexample sample number/total sample number), the formula is as follows:
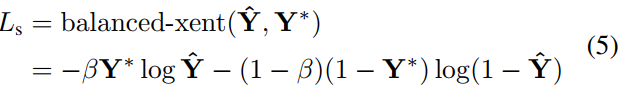 Among them, Y^= Fs is the prediction of the score graph, YIs the label value. The parameter β is the balance factor between positive and negative samples, the formula is as follows
Among them, Y^= Fs is the prediction of the score graph, YIs the label value. The parameter β is the balance factor between positive and negative samples, the formula is as follows
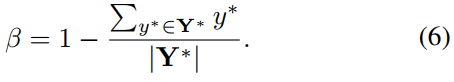
One challenge of text detection is that the size of text in natural scene images varies greatly, and the direct use of L1 or L2 loss for regression will cause the loss to be biased towards larger and longer text areas. Therefore, for RBOX regression, the AoBB part of the IoU loss is used. For QUAD regression, scale-normalized is used to smooth L1 loss.
RBOX loss:
RBOX uses IoU loss for the AABB part, because it is unchanged for objects of different sizes:
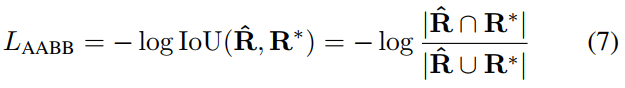 Where R^ represents the predicted AABB geometry, RIs its corresponding callout box. Calculate the width and height of the intersecting rectangle:
Where R^ represents the predicted AABB geometry, RIs its corresponding callout box. Calculate the width and height of the intersecting rectangle:
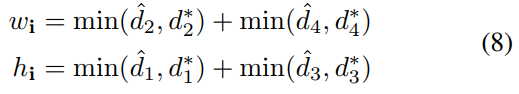
where d1, d2, d3, and d4 represent the distance from a pixel to the top, right, bottom, and left borders of its corresponding rectangle, respectively. The formula of the union area is as follows:
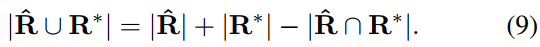
Therefore, the IoU area can be easily calculated. Next, calculate the loss of rotation angle:
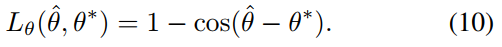
where θ^ is the prediction of the rotation angle, and θ* represents the label value. Finally, the overall geometric loss is the weighted sum of the AABB loss and the angle loss. The formula is as follows:
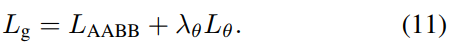
QUAD loss:
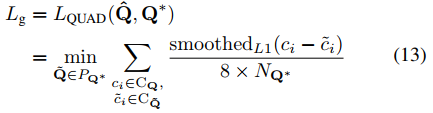
Because this article predicts tens of thousands of geometric boxes, the time complexity of a simple NMS algorithm is O(n^2), where n is the number of candidate boxes, which is complicated The degree is too high. Therefore, this article proposes to merge the geometric figures line by line, assuming that the geometric figures from nearby pixels tend to be highly correlated. When merging the geometric figures in the same line, iteratively merge the currently encountered geometric figure with the last merged figure. The improved time The complexity is O(n).

6.Locality-Aware NMS (Local Awareness NMS)
1. First combine all output box sets with corresponding thresholds (be larger than the threshold, they will be combined, and if they are less than the threshold, they will not be combined), and use the confidence score as the weighted combination to obtain the combined bbox set
2. Perform standard NMS operations on the merged bbox collection.
3. Effect of EAST model
The effect of EAST text detection is shown in the figure below, in which part of the text lines with affine transformation are detected (such as billboards)

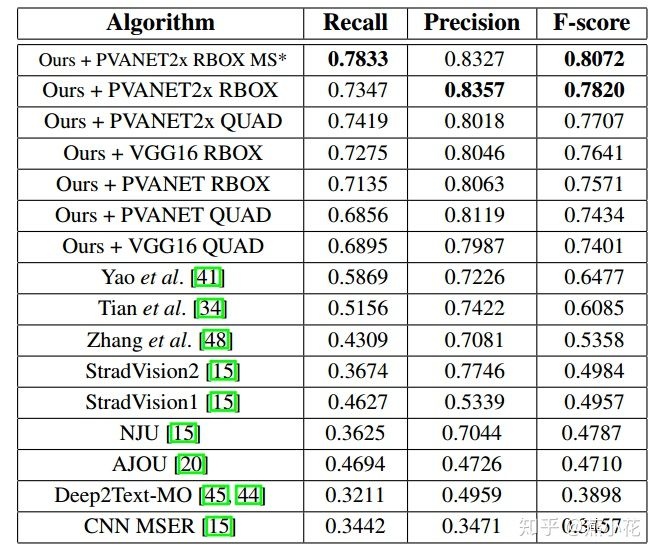
The advantage of the EAST model lies in the concise detection process, which is efficient and accurate, and can realize multi-angle text line detection. But there are also deficiencies, such as (1) the effect of detecting long text is relatively poor, mainly because the receptive field of the network is not large enough; (2) when detecting curvilinear text, the effect is not very ideal
4. Advanced EAST
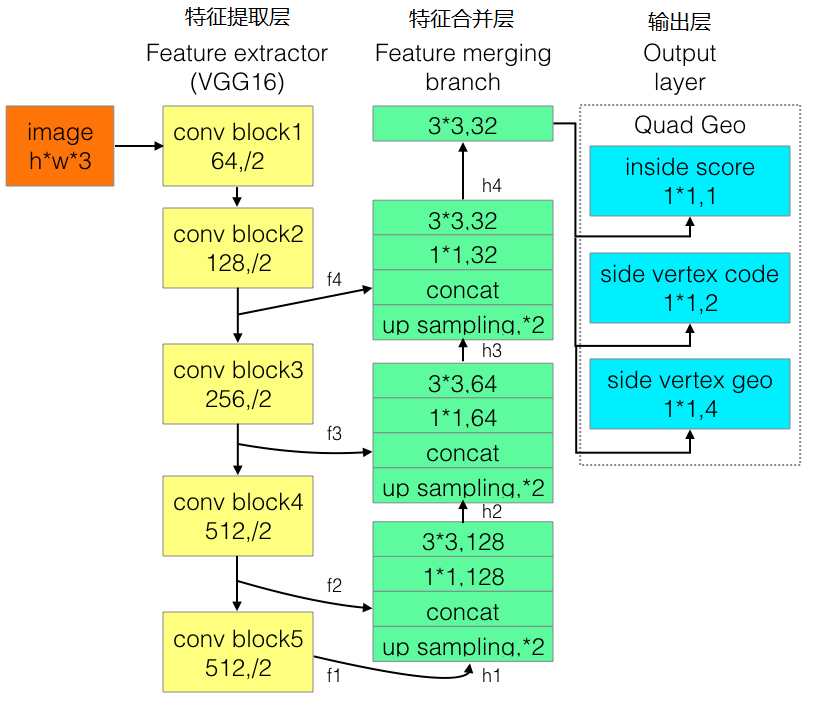
In order to improve the shortcomings of EAST's long text detection effect, Advanced EAST has been proposed, which uses VGG16 as the backbone of the network structure, and is also composed of a feature extraction layer, a feature merge layer, and an output layer. Through experiments, Advanced EAST has better detection accuracy than EAST, especially on long text.
The network structure is as follows:
to sum up
At the feature merging layer, feature maps of different scales are used, and the top-down merging method is carried out through corresponding rules to detect text lines of different scales
provides the direction information of the text and can detect the text in all directions
The method in this article performs poorly when detecting long text, which is mainly determined by the receptive field of the network (the feeling is not big enough)
When detecting curve text, the effect is not ideal
Intelligent Recommendation

Python+opencv+EAST to do natural scene text detection (transfer)
Mark, thank the author for sharing! English original link:https://www.pyimagesearch.com/2018/08/20/opencv-text-detection-east-text-detector/ Reminder: Author's implementation of Python's text detectio...
Text detection based on improving the EAST algorithm
During this time, I read the EAST algorithm and the improvement on the EAST algorithm and completed the reappearance and application into other scenarios. Today's society has entered the era of image ...

Scene text detection - CTPN algorithm
Scene text detection - CTPN algorithm What is OCR? OCR's full name is "Optical Character Recognition" Chinese translation for optical character recognition. It uses optical technology and co...

Opencv calls the EAST scene text detection model for text detection (with Python, C++ code)
Opencv3.4.2 began to support the EAST text detector, without installing complex dependencies, and running the trained detector in a few simple steps to test the effect. 1. Environment: python+opencv+i...

End-to-end text OCR for deep learning: use the EAST model to extract text from natural scene pictures
We live in an era: if any organization or company wants to scale up and remain relevant, it must change their perception of technology and quickly adapt to the changing environment. We already know ho...
More Recommendation

Run EAST text detection algorithm under Windows10 source code
Run EAST text detection algorithm under Windows10 source code Overview: EAST is an efficient scene text detection algorithm. Debugging and running the source code helps to understand the literature, b...

Scene text detection algorithm introduced -CTPN
SIGAI contributing author: Hudong-San Original Statement: This article SIGAI original article, for personal learning use, without permission, shall not be reproduced, can not be used for commercial pu...
Scene Text Detection-Introduction of CTPN Algorithm
What is OCR? The full name of OCR is "Optical Character Recognition" Chinese translation for optical character recognition. It is the process of using optical technology and computer technol...

Scene text detection-introduction to CTPN algorithm
What is OCR? The full name of OCR is "Optical Character Recognition", which translates to optical character recognition in Chinese. It is the process of using optical technology and computer...
Natural scene text detection algorithm - SWT
Series article catalog Chapter II Stroke Width Transform (SWT) Algorithm Principle and Source Code Analysis (1) Article catalog Chapter 1 Stroke Width Transform (SWT) Algorithm Principle...