EAST: An Efficient and Accurate Scene Text Dectector paper notes
tags: Text detection
I recently read a paper on text detection, EAST, whether it is in terms of detection accuracy or speed
Both achieved good results. The blogger is going to write a blog to share his thoughts. The blogger just picked up
In this direction, this is the first paper read by the blogger. There may be some errors in understanding and knowledge. I hope
The big guys are not hesitant to criticize and advise.
1. Summary:
Recently, various algorithms in text detection have achieved satisfactory results in different scenarios.
Achievement. But there are also many shortcomings. For example, the training of the network may be divided into several parts, and
And there may be some complicated and time-consuming operations (such as the extraction of candidate frames, etc.) in this process. On this side
In this article, a very concise single network is extracted, through which we can be very simple, fast and precise
Exactly extract the text information in the scene. The author did the test on ICDAR2015 and COCO-Text respectively, in
When this paper was published, it surpassed popular methods in the market in terms of accuracy and speed. among them
On the ICDAR2015 data set, F-score can reach 0.7820, and the speed can reach 13.2fps. To
The following is a comparison between the algorithm in this article and other algorithm steps:

2. Introduction
Recently, it has become very important and popular to extract and understand text information in natural scenes. The core of text recognition
It is a feature design that extracts text from the background. In the traditional method, these characteristics are set manually.
But in the deep learning method, we can use the deep network to obtain high efficiency and accuracy from the training data.
To extract the characteristics of the network.
However, in the current method, whether it is the traditional method or the deep neural network method, it is through a few steps.
Text extraction. In the author’s opinion, this may cause sub-optimal solutions (why
Will cause sub-optimal solutions, bloggers are not very clear now, I hope the big guys can enlighten me. The blogger thinks it might be because
Because if this process is divided into several parts, it is difficult to compare the previous steps
Some of the features extracted in the first step are optimized. ) And it's a waste of time. So the accuracy of text detection
And the speed will be less satisfactory.
In this paper, the author extracted a fast and accurate method, and our method is only divided into two
step. Our method uses a full convolutional network (FCN) to directly perform letter or text line level pre-processing.
Test, so as to avoid redundant and time-consuming operations (such as the extraction of candidate frames, the synthesis of the text area
Wait). The second step is to perform non-maximum suppression on the prediction produced in the first step to obtain the final prediction result. Read
Do you feel that this method is super concise and super awesome? In fact, when the blogger read this, he thought
The author is bragging here. . . Let me show you a picture in the paper, from this image
We can see the advantages of our method over existing methods.

Here the author lists the three major contributions of this paper:
1. We provide a two-step text detection method: a fully convolutional network and an NMS synthesis stage. The FCN network directly predicts the text area, avoiding some complicated and time-consuming operations.
2. Our method is to flexibly generate predictions at letter and text line level. And according to the needs of the application, our text box can be freely selected as RBOX (rotated rectangle) and QUAD (quadrilateral).
3. Our method surpasses the best text detection algorithm in terms of accuracy and speed.
Three, network introduction
The key component of our algorithm is a fully convolutional network (FCN). This network can be trained directly
Predict the existence of text instances and their geometric shapes. The following is the neural network structure of our algorithm:

The basic structure of this network is based on the network in DenseBox published in 2015. Be everyone
When reading this blog post and feel that some places are a bit unclear, the blogger recommends everyone to check it out
DenseBox articles are helpful for understanding.
First, let's take a look at the input of this network. What we output is the dense prediction of each pixel for the text
information. Let’s take RBOX as an example, the number of channels output by the network should be 5 (the first one is the score map, and the rest
Is the position information of the text box). The geometric shapes we predict are divided into RBOX and QUAD.
Different loss values are also designed accordingly. Among them, the meaning of score is the predicted goal at the pixel position.
The credibility of the target, its value is [0,1]. At the end, we will set the score value greater than the threshold value we designed.
The test frame is left, and NMS is performed to obtain the final result.
Now let's talk about the design of the network. We must consider many factors when designing the network
Vegetarian. First, because of the different sizes of text information, this requires us to extract features at different stages. Such as
Speaking of some large text information, you need to compare the features extracted at a later stage, and some relatively small text information
They like the more advanced feature information. Therefore, the network we design must integrate the characteristics of different stages, and the hypernet network meets this requirement. Let me show you the network structure of the hypernet:

It is found that the structure of this network is very similar to the network structure of this article that we have shown above, both from different levels.
The segments are feature extracted and then synthesized to produce so-called hyper feasure maps. but
Yes! Although our network structure and hypernet are the same in thought, the specific implementation method is different.
Go to something else. From the above figure, we can see that hypernet uses deconvolution and most
The final size of the large pooling is consistent with the size of Conv3. Since the process of reconvolution and pooling will produce
Part of the computational cost. So our network uses the U-shape method to unify the size and combine
In this way, we can not only obtain feature information at different stages but also reduce calculations. Network specific calculation and synthesis
The process will not be introduced in detail here, here is the formula for everyone, I believe you can understand it at a glance!

Four, label generation
The next thing I want to share with you is the label generation process. If we want to train our network, then
So we must have another label, let us compare the predicted result with the label, and then through continuous optimization
The parameters are changed to finally get the network we want.

First, let's look at the generation of Score map tags. According to the description of the paper, the correctness of our Score map
The scope of this book is actually an indentation box of the label box in the picture, as shown in (a) (b) above.
Show.
Before introducing how to indent the label box, let's make a definition, for a quadrilateral Q=
{pi|i∈(1,2,3,4)}, where pi={Xi,Yi} is a vertex of a quadrilateral, from 1 to 4
Hour hand. In order to indent Q, we define a reference length ri:

Where D represents the L2 distance between the two. In fact, ri is the shorter of the two straight lines related to pi. Of course
After that, our indentation is to indent each vertex of the quadrilateral <pi,p(i mod 4)+1>.
0.3ri and 0.3r(i mod 4)+1. Perhaps reading this place, we will have two questions, one
One is why we need to indent, and the other is why we need to indent 0.3ri. Here I feel like going
The reason for the indentation is that there will be some non-target information in our standard box. Indentation can reduce this information
Both have the ultimate goal of improving network performance. As for why the indentation ratio of 0.3 is, I think it is a
A hyperparameter, the author obtained 0.3 through experiments. In this case, the network performance may be the best.
As for the generation of the quadrilateral label, it is relatively simple. The reader can read the paper by himself.
Want to say.
Five, the design of Loss
1. Loss of score map
The first is the loss design of Score map. In our target detection task, there will generally be positive
The negative sample is seriously unbalanced. In this case, most of the current methods use balanced sampling
Or hard negative (that is, choose some negative samples that are close to positive, that is, hard to distinguish
As a negative sample) for training. But this will increase some parameters that need to be fine-tuned and increase calculations
the amount. The author here uses a class-balanced cross-entropy loss function to solve this problem:

Where Y^ represents our predicted Score value, and Y* is ground truth, with a value of 0 or 1.
The parameter β is a balance parameter related to positive and negative samples. The definition given in the paper is as follows:

But the blogger did not understand this formula. . . It feels a bit fascinating. But according to the blogger’s understanding, β is actually
Is the weight of the positive sample in the total sample. Here we introduce the definition of the loss function of the score map
ended. However, in the process of studying the loss function, the blogger found a better loss function definition.
Here is an introduction:

What I want to introduce to you is focal loss. When we used to define the loss function, we mainly considered
What is considered is the imbalance in the number of positive and negative samples. However, we ignore that the difficulty of identifying positive and negative samples has an impact on network performance.
The influence of energy, ignoring this factor, will also lead to the poor effect of our network. For an example, in
The blue line in the above figure is the cross entropy function we usually use. We find that when probability
When the of ground truth is very high, we still have a high loss value, maybe that's it
We don’t think there is much, but in our recognition tasks, negative samples are often easier to identify
, Which means that the probability of ground truth of negative samples is very high, so when the network
When the recognition of negative samples has been done very well, the negative samples will still contribute a lot of loss value, which
To a certain extent, the loss value contribution of our positive samples is suppressed, which causes our network to correct the positive samples
The recognition accuracy decreases. Therefore, we can consider using focal loss as our loss function.
The number can improve the quality of our network to a certain extent.
2. Definition of loss of RBOX
The loss definition of RBOX is mainly divided into two parts, of which we use IOU loss for the AABB part, which
Suitable for detection targets of any scale, defined as follows:

Where R^ is our predicted AABB, and R* is our ground truth. I think everyone is very
It's easy to understand, we won't talk about it here. Then the remaining part is our rotation angle θ
loss, the definition given in the paper is:

Where θ^ represents the rotation angle we predicted, and θ* is our ground truth. Next i
We are the loss function that synthesizes AABB and θ:

In the paper, λθ uses 10 because we pay more attention to the rotation angle, which will achieve the best results. To
Here we have finished introducing the loss of RBOX. I won’t introduce the QUAD here. I will have time later.
We continue to introduce.
Six, effect display


In all the renderings included in the paper, the blogger himself also tested the effect of the network, but the picture is not
Some will be added later. Finally, let's take a look at the comparison between our method and other methods:

It can be seen that in ICDAR2015, our method still has a relatively large advantage. This is me and everyone
If there is something wrong with the shared paper, I hope you don’t mind and point it out to the blogger.
Will humbly accept, thank you for reading.
Intelligent Recommendation
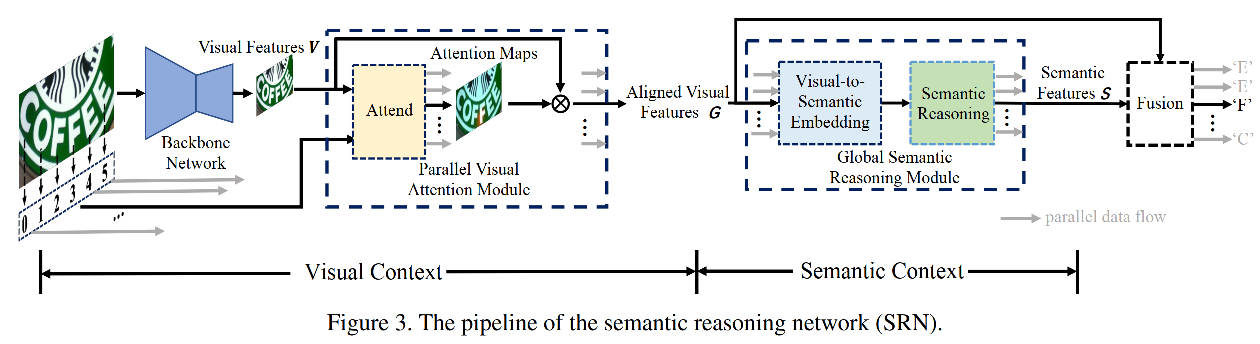
【Paper Notes】Towards Accurate Scene Text Recognition with Semantic Resoning Networks(SRN)
Article directory Towards Accurate Scene Text Recognition with Semantic Resoning Networks Basic Information Summary model structure Backbone Network Parallel Visual Attention Module(PVAM) Global Seman...

[Notes] paper Bag of Tricks for Efficient Text Classification
This article is written by Facebook launched FastText, to quickly categorize tasks and learns on the massive text data, you can use an ordinary multi-threaded CPU training one million corpus in ten mi...

【Paper Notes】 Accurate Text-Enhanced Knowledge Graph Representation Learning
Chinese title: Precise text-enhanced knowledge graph representation learning Publish the meeting:NAACL 2018 Article link:Accurate Text-Enhanced Knowledge Graph Representation Learning Source code: non...

Read the paper notes: MobileFaceNets: Efficient CNNs for Accurate RealTime Face Verification on Mobile Devices
Read the paper notes: MobileFaceNets: Efficient CNNs for Accurate RealTime Face Verification on Mobile Devices Tags: Deep_Learning_ base paper This article contains the following: Papers a...

"TextBoxes++: A Single-Shot Oriented Scene Text Detector" paper notes
1 Overview The method given in this article is to solve the problem of rotating text detection. Therefore, the method TextBoxes++ of the article can detect slanted text. The method of detecting text i...
More Recommendation

[Paper notes] Arbitrary-Oriented Scene Text Detection via Rotation Proposals
Arbitrary-Oriented Scene Text Detection via Rotation Proposals Paper address:https://arxiv.org/abs/1703.01086 github address:https://github.com/mjq11302010044/RRPN This paper is based on the faster-rc...
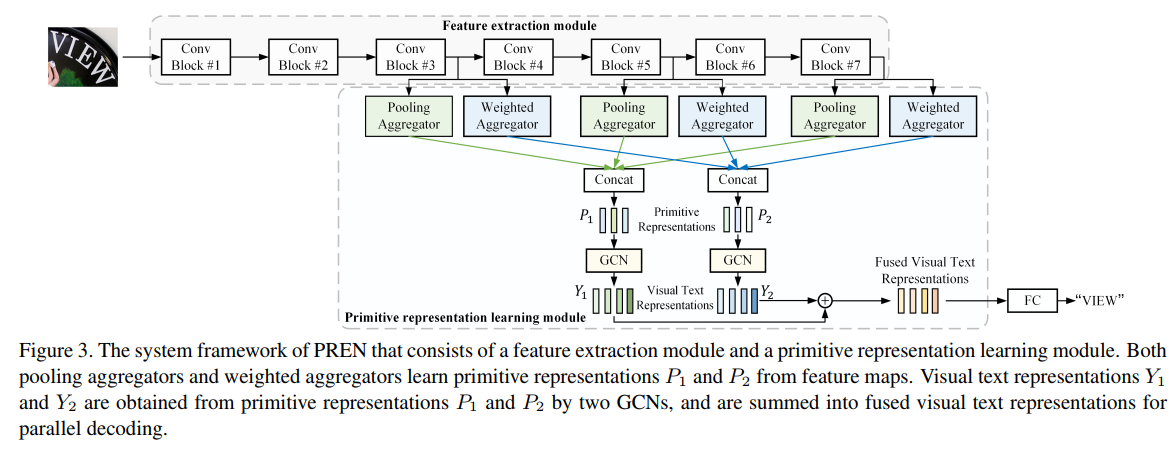
【Paper notes】Primitive Representation Learning for Scene Text Recognition (PREN)
Article directory Primitive Representation Learning for Scene Text Recognition(PREN) Basic Information Summary model structure Primitive representation learning Pooling aggregator Weighted aggregator ...
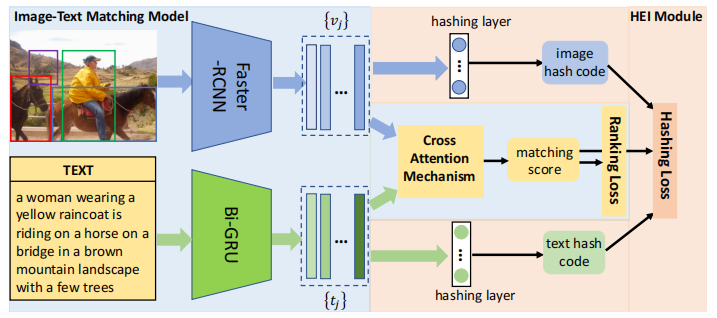
Hashing based Efficient Inference for Image-Text Matching paper notes
Hashing based Efficient Inference for Image-Text Matching motivation This paper believes that although the image-text matching method proposed this year has achieved good results, it will consume a la...
PHP7 extended development hello word
This article is based on PHP7 and explains how to create a PHP extension from scratch. This article focuses on the basic steps of creating an extension. In the example, we will implement the following...
Python the automated analysis rabbitmq rpc client-side code (original)
RPC call client side parsing...