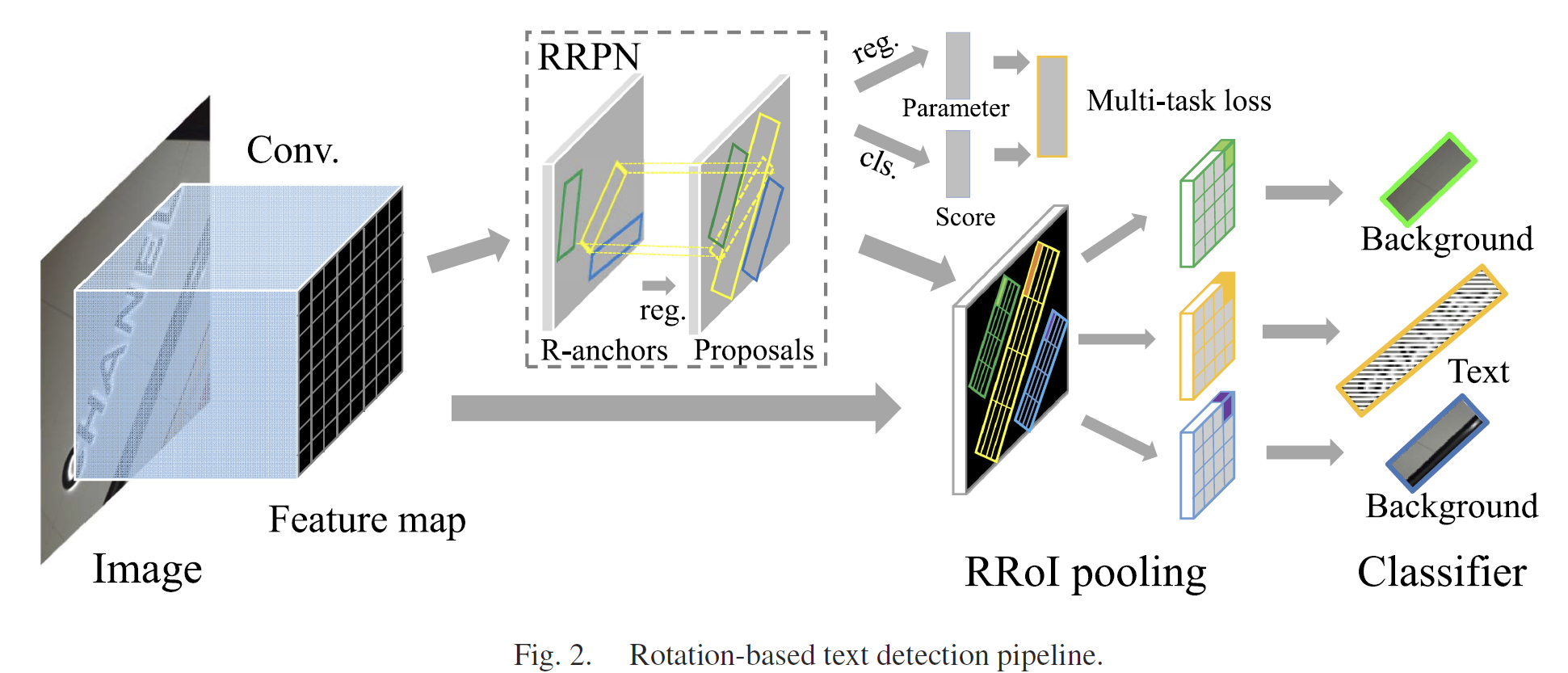
1. Introduction:
TextSnake and PSENet are text instances designed to detect curves and are also widely seen in natural scenes. However, complex pipelines and a large number of convolutional operations, which usually slow down their inference
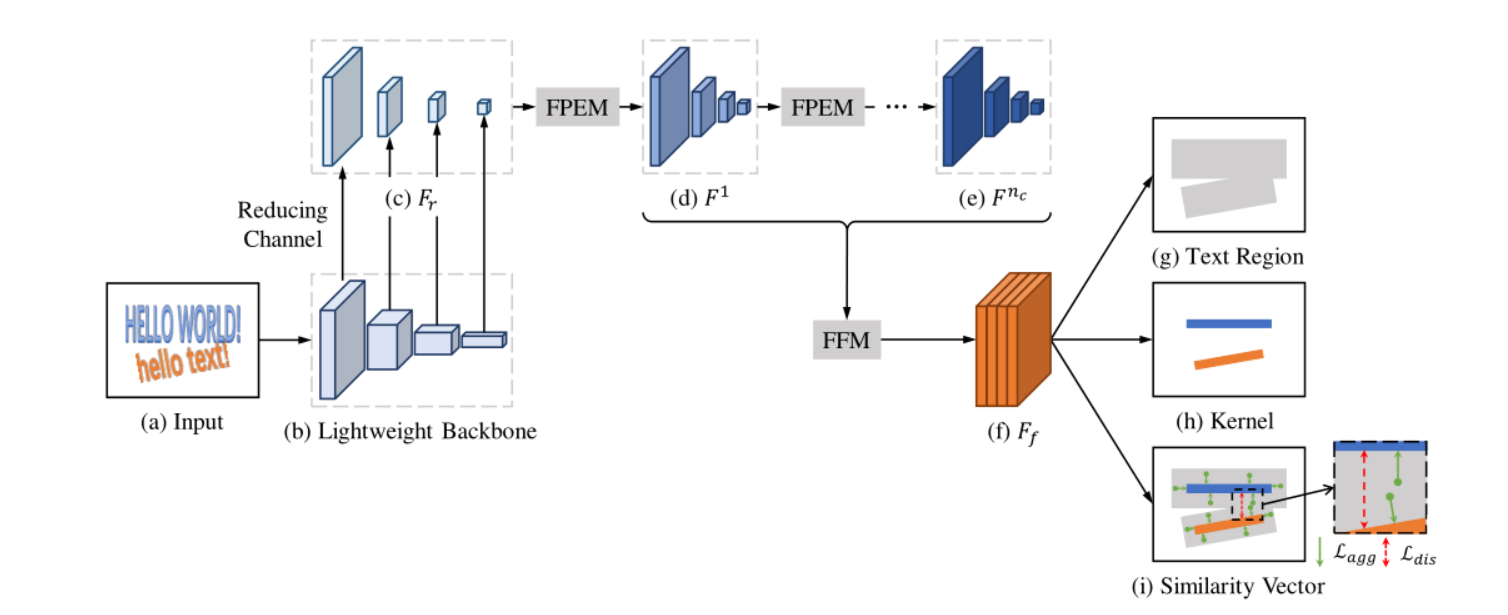
Pixel Aggregation Network (PAN), which is equipped with a low-computing cost segmentation head and a learnable post-processing. More specifically, the split head consists of a feature pyramid enhancement module (FPEM) and a feature fusion module (FFM). FPEM is a cascading U-shaped module that introduces multi-level information to guide better segmentation. FPEM can enhance features at different scales by fusing low-level and high-level information with minimal computational overhead. FFM can collect the features given by FPEMs of different depths into a final feature for segmentation. Learnable post-processing is achieved through pixel aggregation (PA), which can accurately aggregate text pixels through predicted similarity vectors.
To improve efficiency, the backbone of the segmented network must be lightweight. However, lightweight backbones usually have a smaller receptive field and weaker representational ability.Segmentation head proposed, Functional Pyramid Enhancement Module (FPEM) and Feature Fusion Module (FFM). Using the Feature Fusion Module (FFM)FPEMs at different depthsThe generated features are fused into the final features for segmentation, and the network also predicts the similarity vector for each text pixel, so in the same text instancePixels and coresThe distance between similarity vectors is very small
2. Graphic process
backbone: ResNet-18
use 1×1 convolution to reduce the channel number of each feature map to 128,and get a thin feature pyramid Fr
nc enhanced feature pyramids F1 , F2 ,..., Fnc
FFM fuses the nc enhanced feature pyramids into a feature map Ff, whose stride is 4 pixels and the channel number is 512
Ff is used to predict text regions, kernels and similarity vectors
PA post-processing
3. Feature Pyramid Enhancement Module (FPEM)
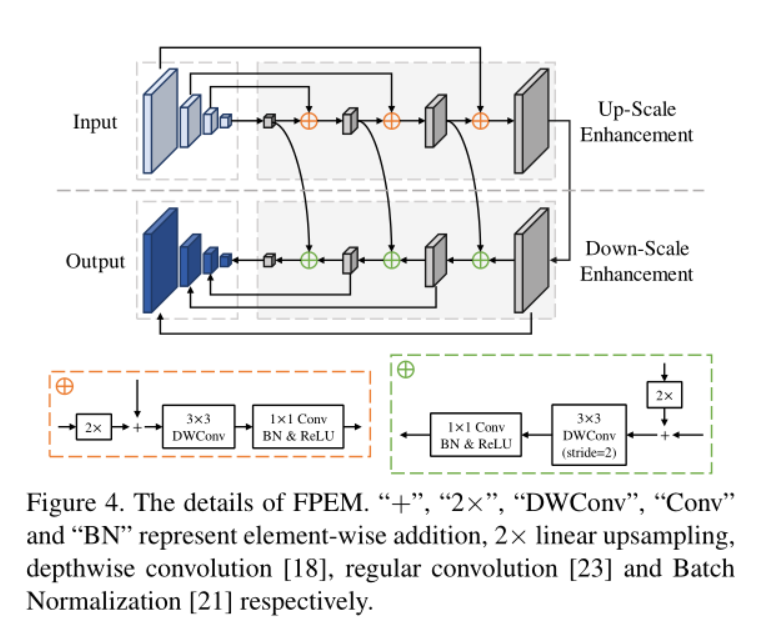
up-scale enhancement and down-scale enhancement
strides of 32, 16, 8, 4 pixels and strides of 4, 8, 16, 32 pixels
FPEM is capable of enlarging the receptive field (3×3 depthwise convolution) and deepening the network (1×1 convolution) with a small computing overhead.(3x3 expands the receptive field, 1x1 deepens the network with small computing volume)
The FLOPS of FPEM is about 1/5 of FPN
4. Feature Fusion Module (FFM)
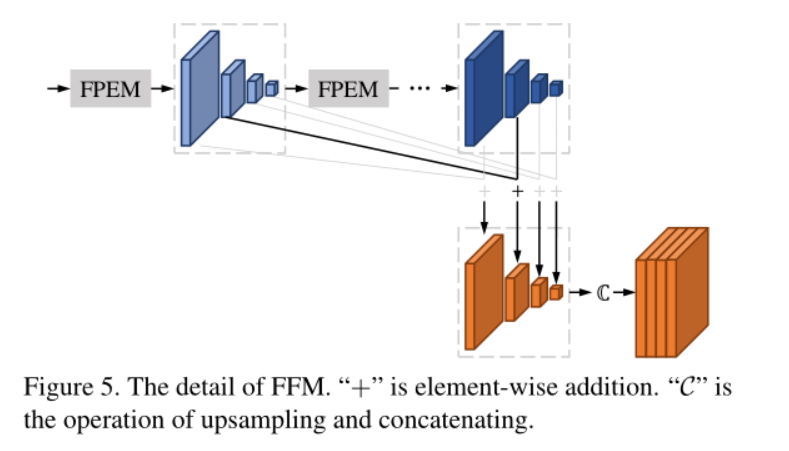
F1, F2,...Fn has different depths. The semantic information of the lower and higher layers is equally important for semantic segmentation. Abandon concatenate after upward rounding (channel number 4x128xnc), slows down the final prediction speed, and takesFirst, combine the corresponding proportional feature maps through element addition. ThenUpsampling the added feature mapand connect it into one (number of channels 4×128)
5. Pixel Aggregation
Borrowing the idea of clustering, reconstructing complete text instances from the kernel. The kernel of the text instance is the cluster center. Text pixels are samples to be clustered. The distance between the text pixel and the kernel of the same text instance is small
1. Adopt aggregation loss (L_agg)
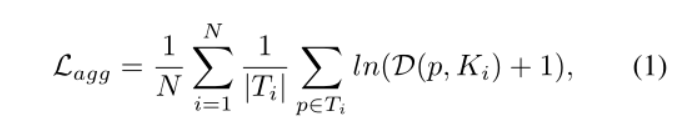
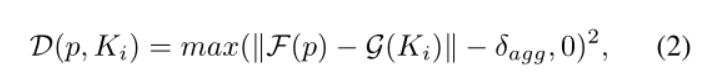
In the second equation, one represents the similarity vector of pixel p and the other represents the similarity vector of kernel ki. The calculation method is
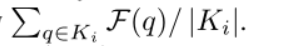
2. The kernels of different text instances should maintain sufficient distance (L_dis)
There should be sufficient distance between different cores, so the calculation formula is
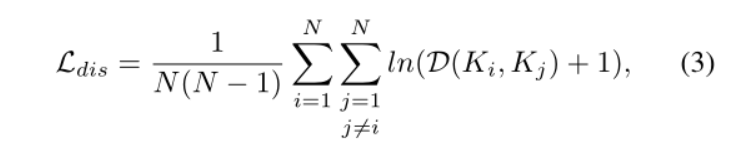
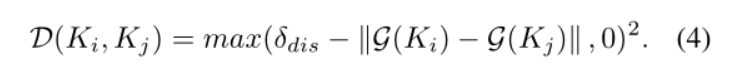
Ldis controls that the diss between each core is not less than 3
During the testing phase, we directed pixels in the text area to the corresponding kernel using the predicted similarity vector. The PA post-processing steps are as follows:
i) Find the connected components in the kernel segmentation result, each connected component is a core.
ii) For each kernel Ki, the Euclidean distance of its similar vector is conditionally merged with adjacent text pixels (4 directions) in its predicted text area less than d
iii) Repeat step ii) until no qualified neighbor text pixels
6. Loss
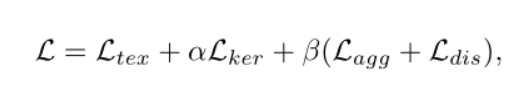

Dice Loss
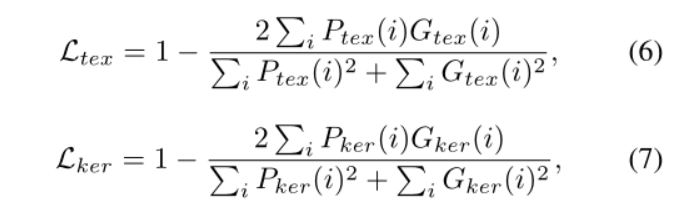
- [psenet] The ground truth of the kernels is generated by shrinking original ground truth polygon, to shrink the original polygon by ratio r
-
Using online hard example mining (OHEM) ignores the use of simple non-text pixels when calculating L tex, only text pixels in gt