[Interpretation of the paper] Facebook He Kaiming Mask R-CNN target instance segmentation
Guide:Since the introduction of convolutional neural networks into the field of target detection, from rcnn to fast-rcnn, and then to end-to-end faster-rcnn, in addition to yolo's unique show, the basic monopoly of the entire target detection field; and He Kaiming's resnet basic It became the pinnacle of the entire image classification algorithm. This time, they joined forces to prepare for sniping instance segmentation.
What is an instance segmentation:Simply put, a group of people are in the picture, I hope to separate everyone from me. Classification can only identify that this picture is a person; target detection can only detect someone in this picture, box out the person's place, and it is not judged for each individual. It is considered to be a person; The main thing is to separate the person and the background, and the instance segmentation is to separate each person clearly.
Source: Global Artificial Intelligence aicapital
Facebook MaskR-CNN paper interpretation
The Facebook Artificial Intelligence Research Group proposes a simpler, more flexible and versatile target instance segmentation framework, MaskR-CNN. The article proposes a conceptually simpler, more flexible and versatile framework for object instance segmentation. Mask R- CNN, this method can effectively detect simultaneous targets in each instance and generate a high-quality segmentation mask for each instance.
Mask R-CNN is an extension on the Faster R-CNN - a parallel branch for predicting the target mask is added to its existing branch for the bounding box recognition. The training of Mask R-CNN is very simple, except that a small amount of computation is added on the basis of R-CNN, which is about 5fps. In addition, the R-CNN mask can be better applied to other tasks, such as estimating the pose of a person in the same picture. The three tasks in this COCO challenge (including instance segmentation, bounding box target detection, and mission critical point detection) Have achieved the best results. Without any other techniques, Mask R-CNN outperformed existing single models, including the winning model of the COCO 2016 Challenge. This report will be briefly introduced from the background, key concepts, introduction to Mask R-CNN and related experimental results.
Presenting background
Research in the field of vision has rapidly improved the performance of target detection and semantic segmentation in recent years. This framework proposed by Facebook will have a major impact on the underlying framework of target detection and semantic segmentation, such as Fast/Faster R-CNN and Full Roller Network (FCN).

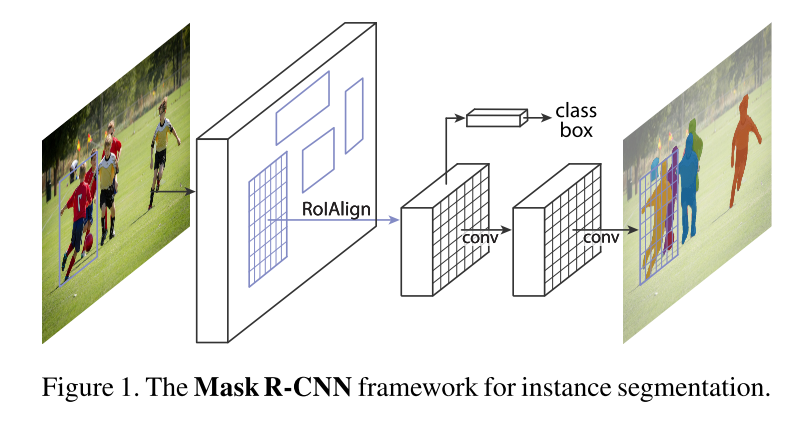
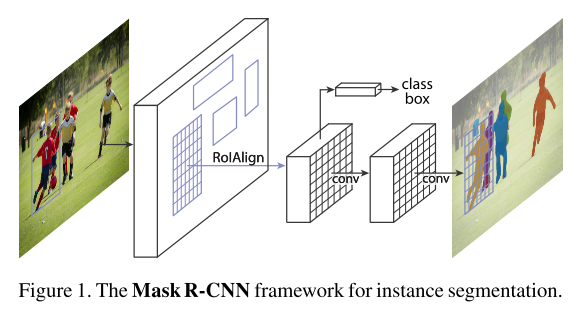
Figure 1 Mask R-CNN framework for instance segmentation
The example segmentation work is difficult because it requires precise detection and segmentation of multiple objects in the same image. This work requires multiple tasks in the task of object detection combined with classical computer vision. Element, target detection task needs to classify each individual instance, locate it in the bounding box, and finally perform semantic segmentation (the work of classifying each pixel). Based on the above description, you may feel that the instance segmentation work requires a complex model to achieve good results, but the Mask R-CNN model proposed by Facebook is unexpectedly simple, flexible and fast, and has the present The best performance.
In general, Mask R-CNN is based on Faster R-CNN based on evolution improvement. FasterR-CNN is not designed for pixel alignment between input and output. To make up for this deficiency, we propose A simple non-quantitative layer called RoIAlign, RoIAlign can retain the approximate spatial position. In addition to this improvement, RoIAlign has a major impact: it can improve the mask accuracy by 10% to 50% ( Mask Accuracy), this improvement can get better measurement results under stricter positioning metrics. Second, we found that segmentation masking and class prediction are important: for this we have predicted a binary mask for each category. Based on the above improvements, our final model Mask R-CNN outperformed all previous COCO instance splitting tasks. This model can run at 200ms on the GPU framework and train on COCO 8-GPU machines. It takes 1 to 2 days, and we believe that training and testing speed, frame flexibility, and accuracy improvements will benefit future instance segmentation.

Figure 2 shows the results of Mask R-CNN in the COCO test set. These results are based on ResNet101, which implements a 35.7 mask AP at 5 fps. Different masks are represented by different colors in the figure, and the confidence of the bounding box and category is also shown in the figure.
Related concept explanation
R-CNN: Region-based CNN (Region-based CNN), referred to as the R-CNN method, handles the principle of target detection in the bounding box by understanding the region as a number of manageable potential instance regions and evaluating each RoI's convolutional network. R-CNN has since been extended to RoIool for feature maps, which greatly increases the speed and accuracy of the framework. By using the Region Proposal Network (RPN) to learn the attentional working mechanism, the researchers have obtained a more advanced FasterR-CNN framework. The Faster R-CNN has become the leading framework for centralized benchmarking with its flexibility and robustness.
Instance Segmentation: Based on the validity of the R-CNN method, many examples of segmentation research are based on the recommendation of the segmentation method. The latest progress is Li (2016) et al. in his paper "Fully convolutional instance-aware" The "complete convolution instance segmentation" method proposed in semantic segmentation. For a more detailed discussion of the segmentation method, please see the original text.
Introduction to Mask R-CNN
Mask R-CNN has a clear and concise idea: For Faster R-CNN, for each target object, it has two outputs, one is the classlabel and the other is the bounding box's offset value (bounding-box offset) On this basis, the Mask R-CNN method adds the output of the third branch: the target mask. The difference between the target mask and the existing class and box output is that it requires a finer extraction of the target's spatial layout. Next, we detail the main elements of Mask R-CNN, including the pixel-to-pixel alignment of Fast/Faster R-CNN.
The working mechanism of Mask R-CNN
Mask R-CNN uses a two-stage process that communicates with Faster R-CNN. The first phase is called RPN (Region Proposal Network). This step proposes the candidate object bounding box. The second phase is essentially FastR-CNN, which uses RoIPool from the candidate framework to extract features and perform classification and bounding box regression, but Mask R-CNN further generates a binary mask for each RoI. We recommend readers to further read the "Speed/accuracy trade-offs for modern convolutional object detectors" paper published by Huang (2016) and others to compare the differences between Faster R-CNN and other frameworks.
The mask encodes the spatial layout of an object. Unlike a class label or framework, Mast R-CNN can use a mask to extract the spatial structure through convolutional pixel alignment.
ROIAlign: ROIPool is a standard operation for extracting feature maps (eg 7*7) from each ROI.
Network Architecture: In order to prove the universality of Mast R-CNN, we instantiate multiple frameworks of Mask R-CNN. In order to distinguish different architectures, the convolution backbone architecture is shown. The architecture is used to extract the features of the entire image; the headarchitecture is used for frame recognition (classification and regression) and mask prediction for each RoI.

Figure 3 Head frame introduction: We have extended two existing Faster R-CNN header frameworks. The left/right graphs show the backbone of the FPN proposed by ResNetC4/Lin et al. (2016) proposed by He et al. (2016), in which masked branches are added. The numbers in the figure represent spatial pixels and channels, and the arrows indicate convolution (conv), deconvolution (deconv) or fully connected layers (fc). The actual case can be inferred (convolution will maintain the spatial dimension, deconvolution will Increase the spatial dimension). The output convolution is 1x1, the others are 3x3, the deconvolution is 2x2, and the stride is 2. We use the ReLU modified linear cell technique proposed by Nair and Hinton (2010) in the hidden layer. In the left picture, rest5 represents the fifth stage of ResNet. For the sake of simplicity, we have modified the architecture to place the first layer of convolution on a 7x7 RoI with a stride of 1 (instead of He etc. The 14x14/step used by humans in the "Deep Residual Learning in Picture Cognition" study is 2); the 'x4' in the right figure represents a stack of 4 consecutive convolutions.
Related experimental results
Instance segmentation
We compared the Mask R-CNN method with the existing method and used the COCO data set in all experiments.

Figure 4 shows the other results of using Mask R-CNN on the COCO test picture, using a 35.7 mask AP, ResNet-101-FPN, running at 5fps.
Our experiments were conducted on the COCO dataset. The standard COCO measures include AP (average of IoU threshold), AP50, AP75 and APs, APM, APL (APs of different sizes). If not specified, AP is passed. The mask IoU is estimated. Table 1 is the result of comparing the Mask R-CNN with the existing example segmentation method. Figure 2 and Figure 4 are the visualization results of the Mask R-CNN output. Figure 5 is the comparison of the Mask R-CNN benchmark with the FCIS+++, FCIS+++ display. It will be affected by the basic artifacts of the instance segmentation, and this is not the case with Mask R-CNN.
Table 1 Example Segmentation Results: The results of comparing Mask R-CNN with other instance segmentation methods are recorded in the table. Our model performs better than all similar models. MNC and FCIS are the champions of the COCO 2015 and 2016 Split Challenges respectively. Mask R-CNN performs better than the more complex FCIS+++, which includes multi-scale training/testing, horizontal flip testing and OHEM. All are single model results.


Figure 5 FCIS+++ (top) vs. Mask R-CNN (lower, ResNet-101-FPN), FCIS will have systematic artifacts on the complex body problem.
The researchers conducted several tests on Mask R-CNN, and the results are shown in Table 2 below:
Table 2 Mask R-CNN Ablations results, the model was tested on trainval35k, minival, and reported based on mask AP results.

Table 2 (a) Backbone architecture: A better backbone can bring the desired benefits: deeper network performance is better, FPN performance exceeds C4 characteristics, and ResNeXt is improved on the basis of ResNet.
Table 2 (b) Polynomial Contrast Independent Mask (ResNet-50-C4) Results: The Decoupling comparison polynomial mask (softmax) performed by the binary mask (sigmoid) of each class has a better performance.
Table 2(c) shows the results of RoIAlign (ResNet-50-C4): masking results using different RoI layers. Our RoIAlign layer improves AP ~3 points and improves AP75 ~5 points. One of the reasons for improvement using a suitable alignment method.
Table 2(d) RoIAlign (ResNet-50-C5, stride 32) shows the AP based on the mask level and box level of the large-stride feature. Compared to the stride-16 feature (as shown in Table 2c), the alignment errors that occur here are more severe, resulting in a large number of precision errors.
Table 2 (e) Mask Branch (ResNet-50-FPN): Full Convolutional Networks (FCN) vs. Multilayer Perceptron (MLP, Full Attach) for mask prediction. FCNs use code space layout to improve the results.
Table 3 Target Detection: The results of a single model (boundary box AP) on test-dev versus other models. The Mask R-CNN results using ResNet-101-FPN performed better than other similar models (these models ignored the mask output problem), and the good results of Mask R-CNN benefited from the use of RoIAlign (+1.1 APbb), multitasking. Training (+0.9 APbb) and ResNeXt-101 (+1.6 APbb).


Figure 6 uses the key point test results of Mask R-CNN (ResNet-50-FPN) on the COCO test, and uses the same model to predict the person segmentation mask. This model has a keypoint mask of 63.1 and runs at 5 fps.
The use of Mask R-CNN can also be extended to the estimation of character poses, the author conducted relevant experiments, and Table 4 is the experimental results.
Table 4 detects the AP at the key point on the COCO test-dev. The model we use is ResNet-50-FPN, a single model running at 5fps. CMU-Pose+++ is the 2016 champion model, using multi-layer testing. And post-processing CPM, using target detection filtering, and cumulative ~5 points: G-RMI training with COCO plus MPII, using two models (Inception-ResNet-v2 + ResNet-101), this model uses more More data, so it can't be directly compared with Mask R-CNN.

Considering the effectiveness of the Mask-CNN model for extracting bounding boxes, masks, and key points, we expect it to be a more efficient framework for instance-level tasks. Mask-CNN can be generalized to more instance layers (instance) Level) identification work and can be extended to more complex tasks.
Thesis address: https://arxiv.org/pdf/1703.06870.pdf
Paper references: