Detailed interpretation of Mask R-CNN principle

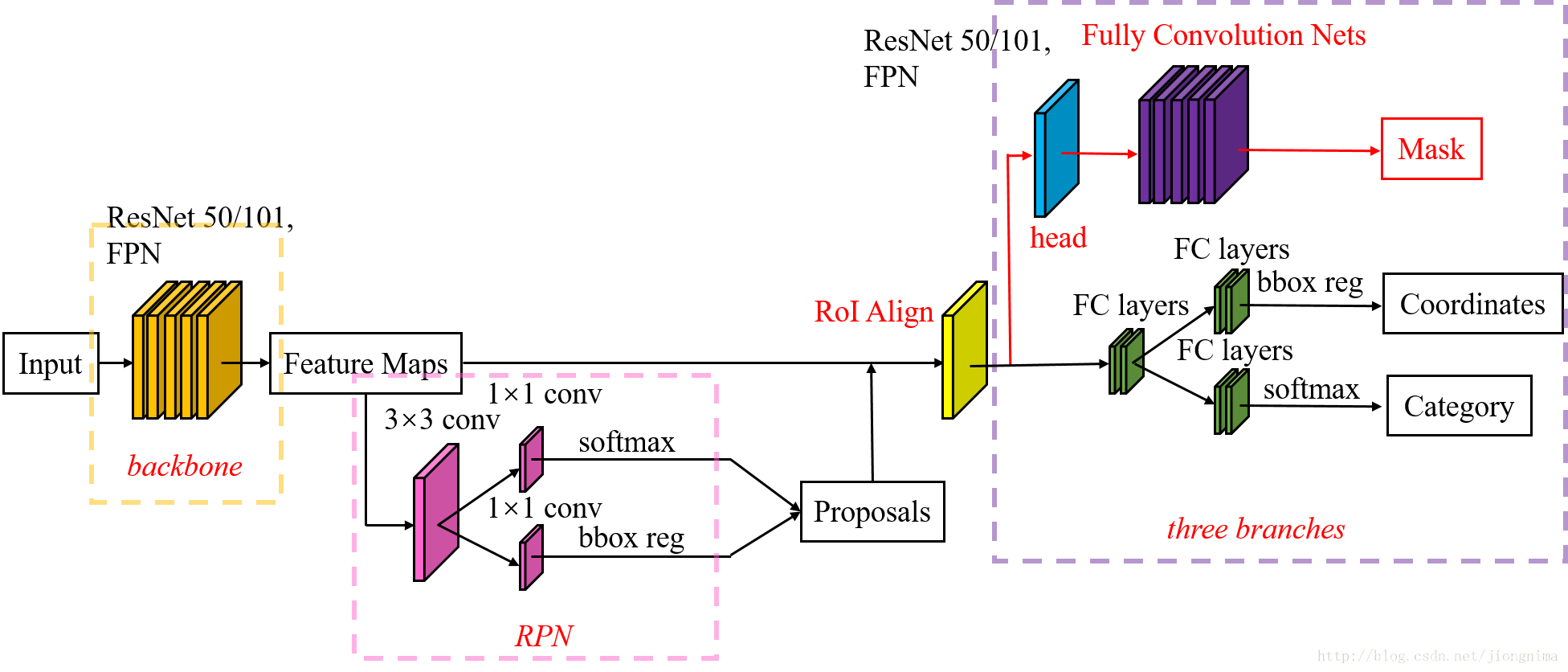
Mask R-CNN adds a branch to predict the split mask based on Faster R-CNN, as shown in the figure above. The black part is the original Faster-RCNN and the red part is the modification on the Faster-RCNN network. It will be replaced with RoIAlign layer RoI Pooling layer; FCN added layer (mask layer) side by side.
One,RoIAlign
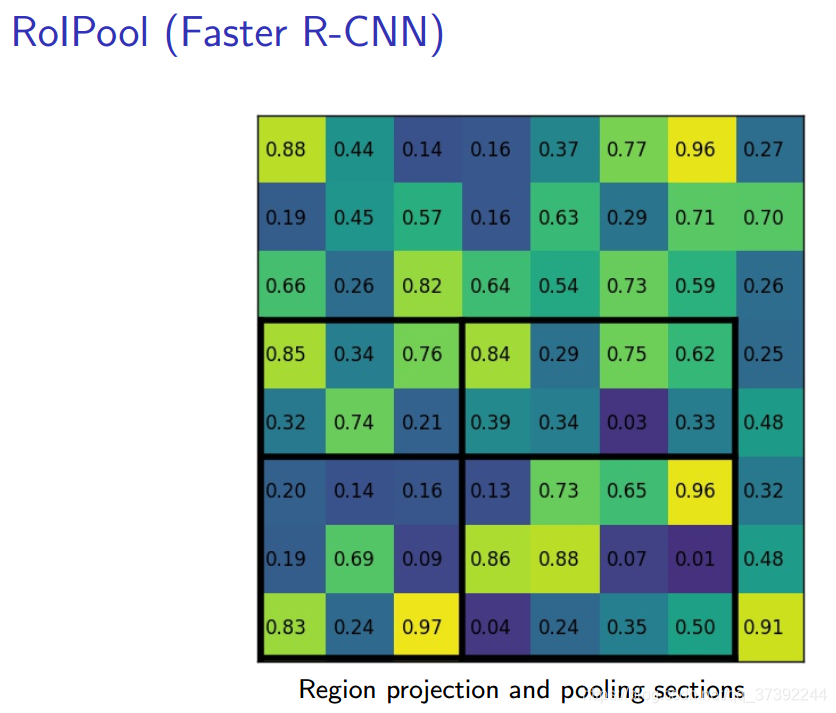
First, some RoIPooling, its purpose is to derive FIG smaller features (a small feature map, eg 7x7) determined from the ROI RPN network, the size of each ROI is not the same, but have become the RoIPool 7x7 size. The RPN network will propose a number of RoI coordinates expressed as [x, y, w, h], then input RoI Pooling, and output a 7x7 size map for classification and positioning. The problem is that the output size of RoI Pooling is 7x7. If the ROI output of the ROI network is 8*8, there is no guarantee that the input pixel and the output pixel are one-to-one. First, they contain different amounts of information (some are 1 pair). 1, some are 1 to 2), and secondly their coordinates can not be associated with the input (1 to 2 of which RoI output pixel corresponding to which input pixel coordinates?). This has no effect on the classification, but it has a great impact on the segmentation. The output coordinates of RoIAlign are obtained using an interpolation algorithm, which is no longer quantized; the value in each grid is no longer using max, and the difference algorithm is also used.

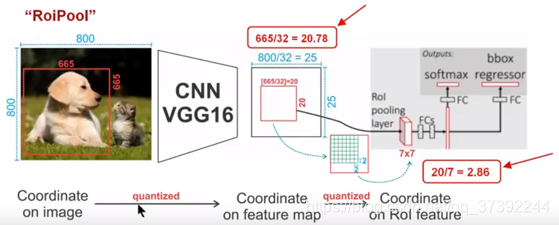
As shown above: In order to get a fixed size (7X7) feature map, we need to do two quantization operations: 1) image coordinates - feature map coordinates, 2) feature map coordinates - ROI feature coordinates. Let's take a look at the specific details. As shown in the figure, we input an image of 800x800. There are two targets (cats and dogs) in the image. The size of the dog's BB is 665x665. After the VGG16 network, we can get the corresponding image. feature map, if we Padding convolution operation layer, our image after convolution layer maintains its original size, but because of pooling layer, we end up feature map will shrink more than a certain percentage of the original image, and this The number of pooling layers is related to the size. In the VGG16, we used 5 pooling operations, each pooling operation is 2Pooling, so we finally get the feature map size of 800/32 x 800/32 = 25x25 (is an integer), but will be dog BB corresponds to the feature map above, we get the result is 665,/32 x 665/32 = 20.78 x 20.78, the result is a floating point number, with decimals, but our pixel value can be no decimal, then the author quantifies it (i.e., a rounding operation), i.e., the result becomes 20 x 20, where the introduction of the first quantization error; however, our feature map have different sizes of ROI, but we are asking our network behind a fixed Input, therefore, we need to convert different sizes of ROI into a fixed ROI feature, here using the 7x7 ROI feature, then we need to map the 20 x 20 ROI to the 7 x 7 ROI feature, the result is 20 /7 x 20/7 = 2.86 x 2.86, also a floating point number with a decimal point, we take the same operation to round it up, and introduce a second quantization error here. In fact, the error introduced here will lead to the deviation of the pixels in the image and the pixels in the feature. The ROI of the feature space will have a large deviation corresponding to the original image. The reason is as follows: For example, using the error we introduced the second time, it is 2,86, we quantize it to 2, which introduces an error of 0.86, which seems to be a small error, but you have to remember this is the feature space, our feature space and image space is proportional relationship, here is 1:32, then the corresponding original gap to the top is 0.86 x 32 = 27.52. This gap is not small, it is only considering the second quantization error. This can greatly affect the performance of the entire detection algorithm and is therefore a serious problem.
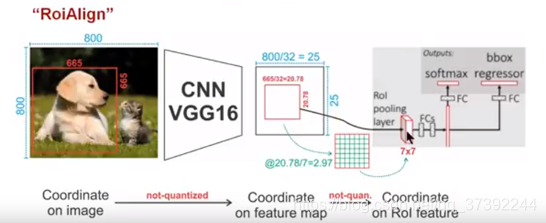
As shown in the figure above, in order to get a fixed size (7X7) feature map, ROIAlign technology does not use quantization operation, that is, we do not want to introduce quantization error, such as 665 / 32 = 20.78, we use 20.78, no need to replace 20 it is, for example, 20.78 / 2.97 = 7, we will use 2.97 instead of 2 to replace it. This is the original intention of ROIAlign. So how do we deal with these floating point numbers? Our solution is to use the "bilinear interpolation" algorithm.Bilinear interpolation is a better image scaling algorithm, which makes full use of the virtual points in the original image (such as20.56This floating point number, the pixel position is an integer value, there is no floating point value) four surrounding real pixel values to jointly determine a pixel value in the target image, that is,20.56The pixel value corresponding to this virtual position point is estimated。
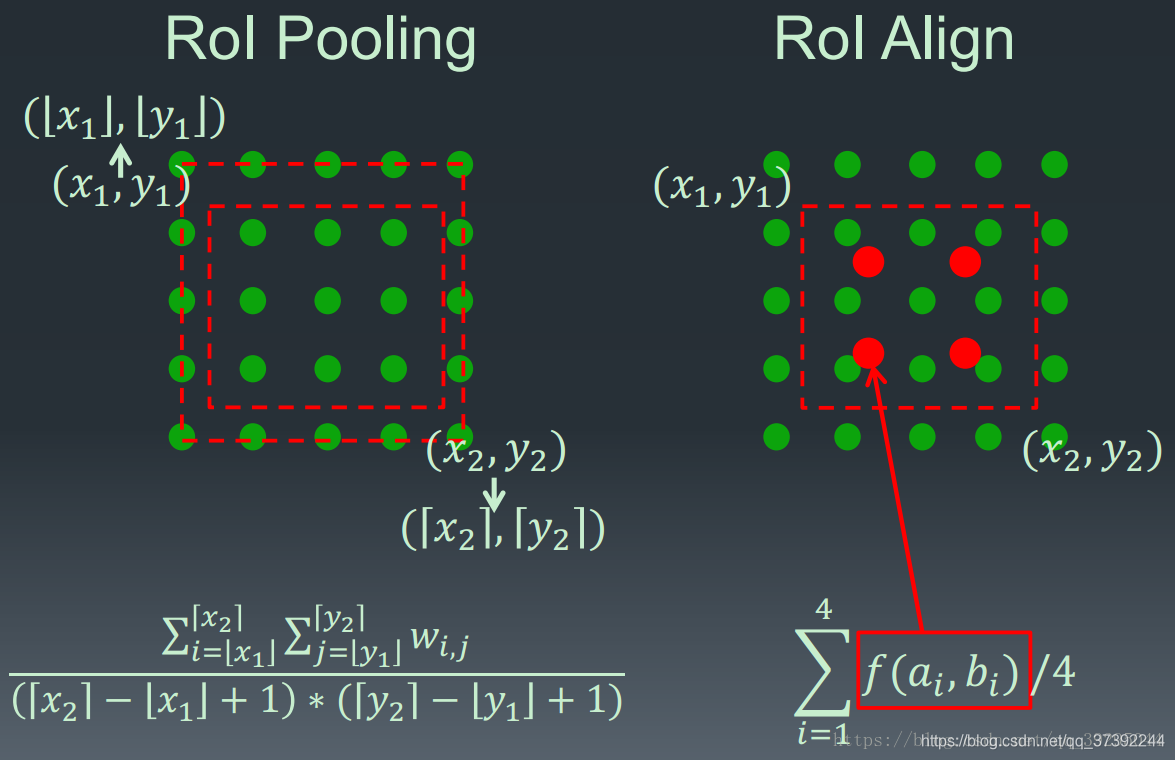
As shown in the figure below, the blue dotted box indicates the feature map obtained after convolution, the black solid line box indicates the ROI feature, and the final output size is 2x2, then we use bilinear interpolation to estimate these blue points (virtual coordinate point, also known bilinear interpolation grid point) corresponding to the pixel values of the premises, to give the corresponding final output. These blue dots are common points for random sampling in 2x2Cell. The authors point out that the number and location of these sampling points does not have a large impact on performance, and you can use other methods. Then perform max pooling or average pooling operations in each orange-red area to get the final 2x2 output. Our process does not use the entire quantization operation, no error is introduced, i.e., the original pixel and the pixel in the feature map are completely aligned, there is no deviation, which will not only improve the accuracy of detection, but also split in favor example .

ROIPooling and Comparative ROIAlign process is as follows:







two,Network Architecture
The overall network architecture consists of two parts, one part is used to extract features backbone, the other head part is used to classify each ROI, regression and mask frame prediction.
In order to generate the corresponding Mask, two architectures are proposed, namely Faster R-CNN/ResNet on the left and Faster R-CNN/FPN on the right, as shown in the following figure.
For the architecture on the left, our backbone uses pre-trained ResNet, which uses ResNet's fourth-tier network. The input ROI first obtains the 7x7x1024 ROI feature, then upgrades it to 2048 channels (here modified the original ResNet network architecture), then has two branches, the above branches are responsible for classification and regression, and the following branches are responsible for generating corresponding the mask. Since the previous convolution and pooling are performed, the corresponding resolution is reduced, and the mask branch starts to use the deconvolution to improve the resolution, and at the same time, the number of channels is reduced to 14x14x256, and finally the 14x14x80 mask is output. template.
The backbone used on the right is the FPN network. This is a new network. By inputting a single-scale image, you can finally correspond to the feature pyramid. If you want to know the details, please refer to the link. It has been confirmed that the network can improve the accuracy of detection to a certain extent, and many current methods use it. Since the FPN network already includes res5, features can be used more efficiently, so fewer filters are used here. The architecture is also divided into two branches, the same as the former, but the classification branch and the mask branch are quite different from the former. Probably because the FPN network can get a lot of useful information on features of different scales, so fewer filters are used for classification. The convolution operation is performed in the mask branch. First, the ROI is changed to the feature of 14x14x256, and then the same operation is performed 5 times (the principle is not clear, expecting your explanation), and then the deconvolution operation is performed. Finally, the 28x28x80 mask is output. That is, a larger mask is output, and a more detailed mask can be obtained than the former.

three,Loss function
The Loss function for each ROI is as follows:
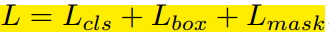
Each ROIAlign corresponds to the output of the K * m^2 dimension. K corresponds to the number of categories, that is, outputs K masks, and m corresponds to the pool resolution (7*7). Loss function definition: Lmask(Cls_k) = Sigmoid (Cls_k), average binary cross-entropy Loss, calculated by pixel-by-pixel Sigmoid. Corresponding to an ROI belonging to the kth class in the GT, Lmask is only defined on the kth mask (other k-1 mask outputs do not contribute to the entire Loss). Why K mask? Inter-class competition can be effectively avoided by assigning a Mask to each Class (other Classes do not contribute to Loss).
Fourth, the experimental results


Intelligent Recommendation
Faster R-CNN article detailed interpretation
article《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》It was proposed to improve Fast R-CNN. Because the test time in the Fast R-CNN article does not include the searc...
Mask R-CNN --Mask R-CNN
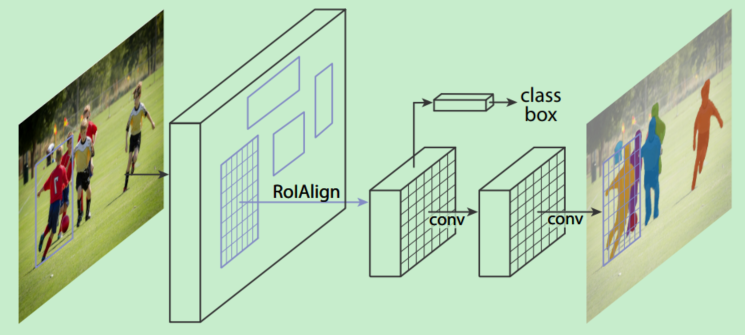
According to a number of articles, only for reference to learn from each other. Mask R-CNN Effectively detects targets in the image while also generating a high-quality segmentation mask for eac...
Mask R-CNN detailed (very detailed !!! Xiaobai must watch !!!)
Mask R-CNN Mask R-CNN is an instance segmentation algorithm, mainly to split on the basis of target detection. The Mask R-CNN algorithm is mainly FASTER R-CNN + FCN, more specific to ResNext + RPN + R...

Mask R-CNN
Link to the paper: https://arxiv.org/abs/1703.06870 First, the introduction Mask R-CNN is a masterpiece of He Kaiming in 2017. It performs segmentation while performing target detection and achieves e...

Mask R-CNN translation
Mask R-CNN translation Summary We propose a conceptually simple, flexible and versatile object instance segmentation framework. Our method efficiently detects targets in an image while generating a hi...
More Recommendation

Introduction to Mask R-CNN
I. Overview Mske r-cnn is a network architecture based on the fast rcnn, which mainly completes the semantic segmentation of the target individual. The main idea of the paper is to expand the origin...

Mask R-CNN parse
Mask R-CNN parse Paper ideas Mask -RCNNFirst pictures do testing, to identify the ROI in the image, pixel correction using ROIAlign each ROI, a...

Mask R-CNN Intensive
1. Introduction In principle Mask R-CNN is an intuitive extension ofFaster R-CNN, yet constructing the mask branch properlyis critical for good results. Most importantly, Faster RCNNwas not designed f...
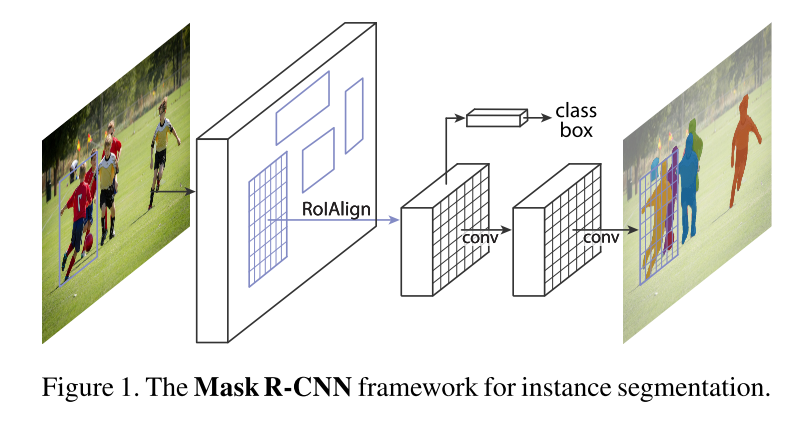
Mask R-CNN summary
Papers Address:https://arxiv.org/abs/1712.00726 Content of the article: Paper Overview Algorithms points Bilinear interpolation Paper Summary: Mask R-CNN is adding a branch in Faster R-CNN basis to pr...

Mask R-CNN notes
Mask R-CNN is an instance segmentation algorithm that can be used for target detection, target instance segmentation, and target key point detection. The difficulty of instance segmentation is that al...