Mask R-CNN notes
Mask R-CNN is an instance segmentation algorithm that can be used for target detection, target instance segmentation, and target key point detection.
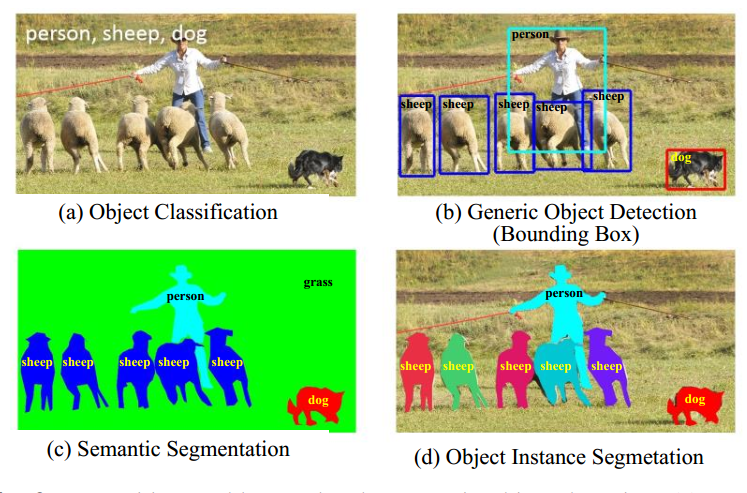
The difficulty of instance segmentation is that all the targets in a picture must be correctly detected and each instance must be segmented.
The purpose of detection is to classify each single target and then mark it with a bounding box, and the purpose of instance segmentation is to distinguish each pixel into a different classification.

Mask R-CNN introduction
The idea of the entire Mask R-CNN algorithm is very simple, which is to add the corresponding MASK branch (complete the image segmentation task) on the basis of the original Faster-rcnn algorithm.Faster-rcnnnotes
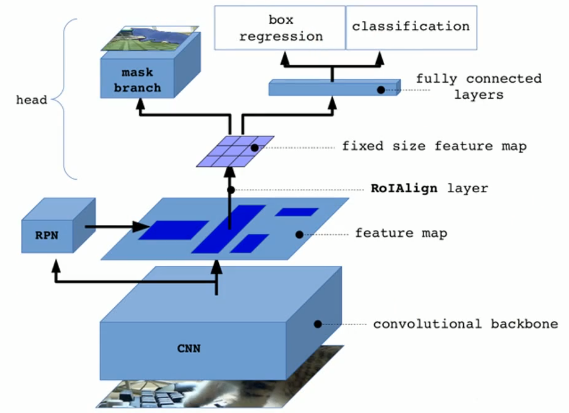
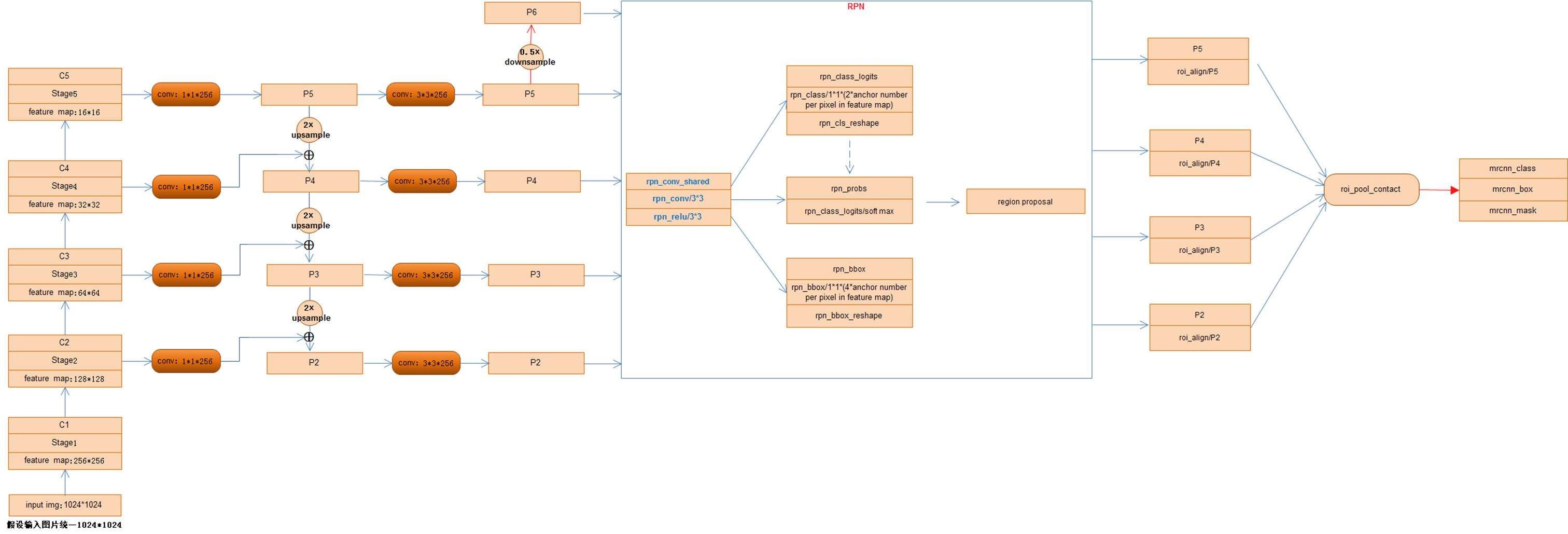
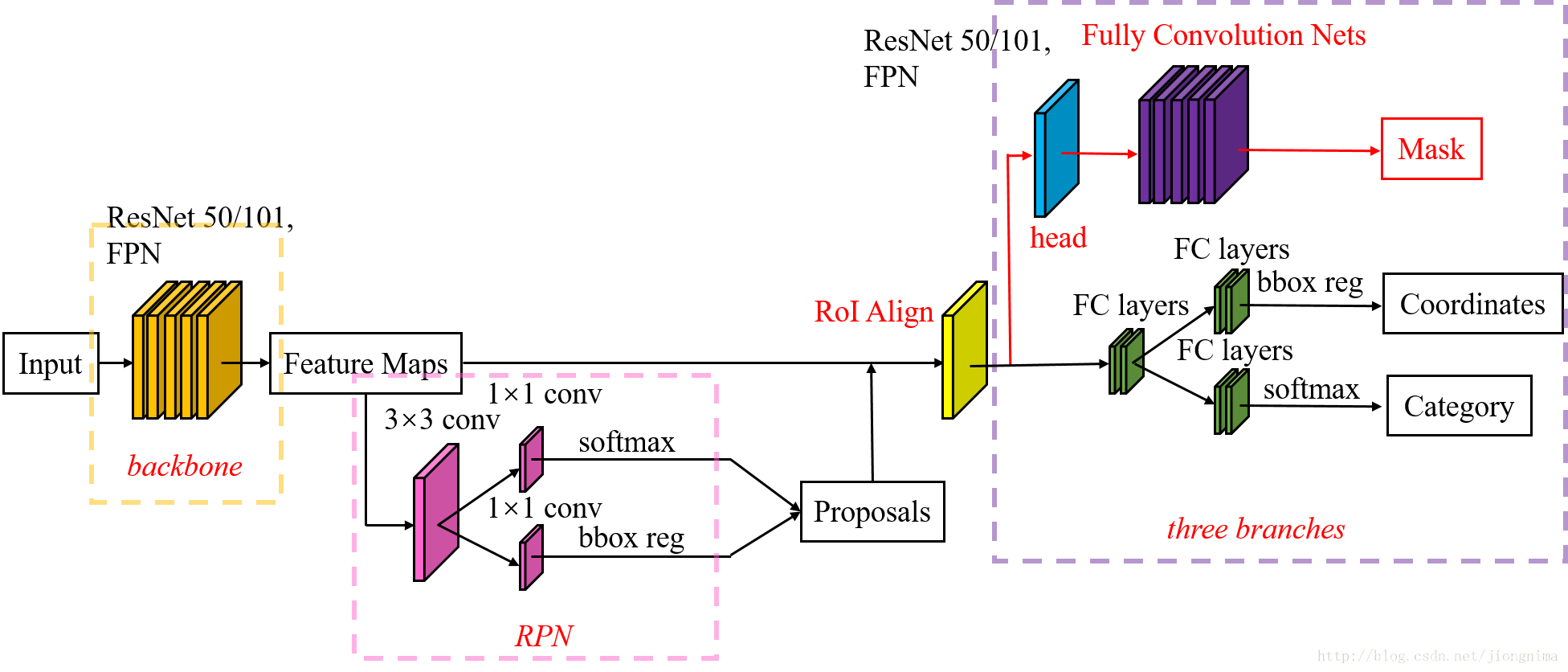
Mask R-CNN structure
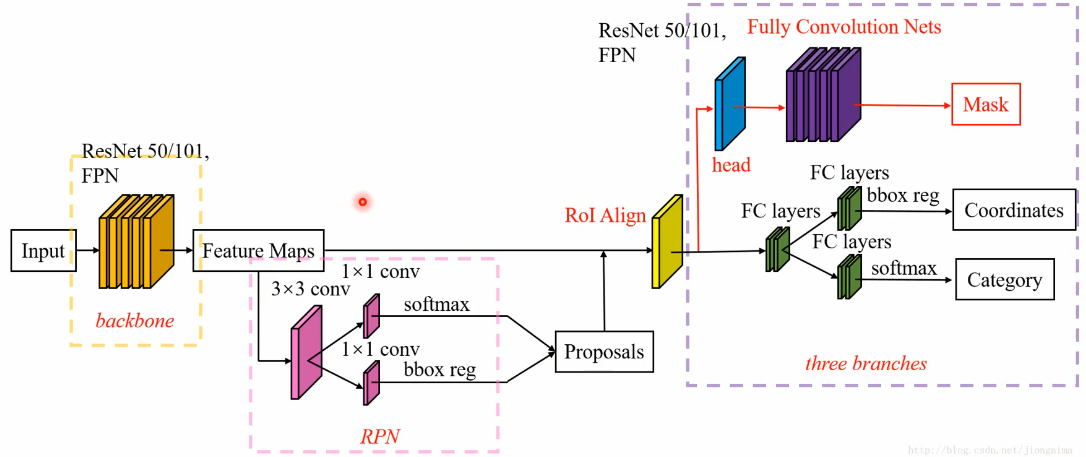
The image passes through the backbone network to extract the feature map; after RPN, the candidate area is generated; after RoI Align, the candidate area is changed to the same size; it is passed to the head layer for classification, regression, Mask task
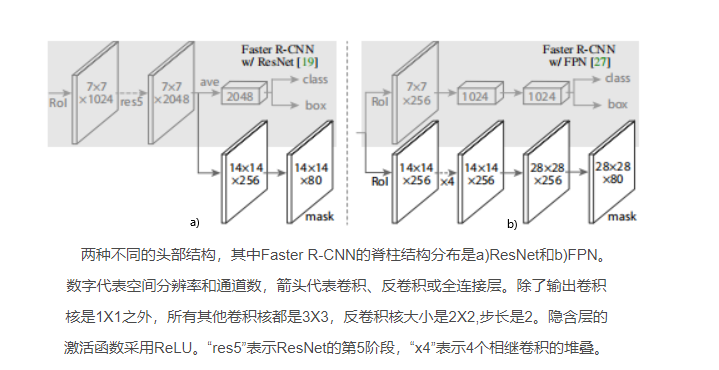
head structure
There is a "head" part after Align, the main function is to use transposed convolution to expand the output feature map of Roll Align, so that it will be more accurate when predicting Mask.
(1) There are three branches: classification, regression, and mask. For the mask branch
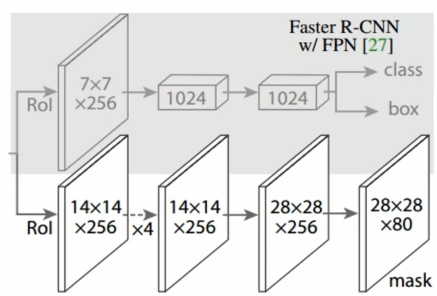
14x14x256 after 4 convolutions, still 14x14x256; 28x28x256 is obtained by transposed convolution upsampling; then 28x28x80 is obtained by convolution (80 corresponds to 80 categories of Coco dataset, each (1 category has 1 Mask corresponding to it)
(2) Bilinear interpolation transforms the 28 × 28mask to the size of the box in the original picture. The mask has a deformation when it is transformed here
(3) Each class outputs a mask, the activation function is sigmoid, and takes a threshold of 0.5 to obtain a binary mask.
Note: Bilinear interpolation is a commonly used resize algorithm, which is equivalent to resize a 28 × 28 small picture into a large picture
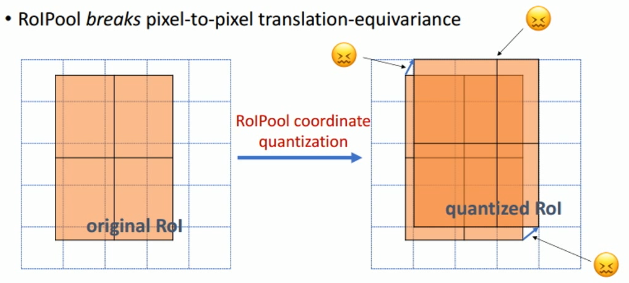
Limitation analysis of ROI Pooling
In Faster-RCNN, the role of ROI Pooling is to pool the corresponding area into a fixed-size feature map in the feature map according to the position coordinates of the pre-selected frame, so as to perform subsequent classification and candidate frame regression operations.
Because the position of the candidate box is usually obtained by model regression, generally speaking, it is a floating point number, and the pooled feature map requires a fixed size.
Therefore, the operation of ROI Pooling has two quantization processes:
1. Quantify the boundary of the candidate frame into integer point coordinate values.
2. Divide the quantized boundary area into kxk units (bin) on average, (For a chestnut, suppose k = 5, 5x5 to divide the boundary area with length and width of 9 equally , The length and width of the divided cells are not integers), and the boundary of each cell must be quantified.
In fact, after the above two quantizations, the candidate box at this time has a certain deviation from the initial regression position. This deviation will affect the accuracy of detection or segmentation. In the paper, the author summarizes it as "misalignment".
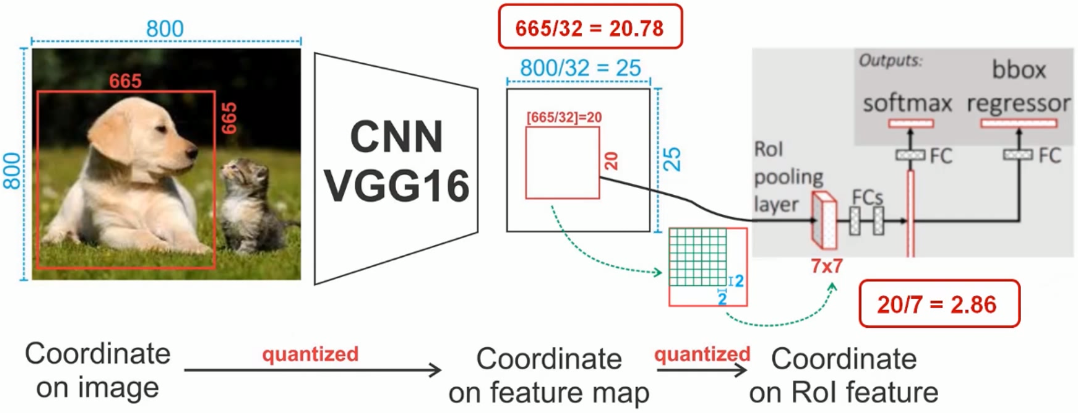 800x800 original picture, there is a 665x665 prediction box;
800x800 original picture, there is a 665x665 prediction box;
The original image is convolved with Vgg6, and the final result is reduced by 32 times. The prediction box is reduced by 32 times and the size is 20.78, which needs to be converted to an integer of 20
RoI pooling, 20/7 = 2.86, again quantized and rounded down to 2.
An error of 1 pixel on the final feature map will produce an error of 32 pixels on the original image
If the difference between the above is 0.86 pixels, the difference between the original image and the original image is 0.86x32 which is approximately equal to 27 pixels. For image segmentation tasks, this deviation is quite large.
ROIAlign
Although misalignment has little effect on the classification problem, there will be a large error on the Pixel level Mask.
ROI Align is a regional feature aggregation method (used to optimize ROI pooling) proposed in the theory of Mask-RCNN, which solves the problem caused by two quantizations in the ROI Pooling operation. Problem of misalignment. Experiments show that replacing ROI Pooling with ROI Align in the detection task can improve the accuracy of the detection model.
ROIAlign main ideas and methods
In order to solve the above shortcomings of ROI Pooling, the author proposes an improved method of ROl Align. The idea of ROI Align is very simple: cancel the quantization operation, and use the method of bilinear interpolation to obtain the image value on the pixel point whose coordinates are floating point numbers, thus transforming the entire feature aggregation process into a continuous operation. It is worth noting that in the specific algorithm operation, ROIAlign does not simply supplement the coordinate points on the boundary of the candidate area, and then pool these coordinate points, but redesigns a set of processes:
1. Traverse each candidate area and keep the floating-point boundary not quantized. (The first round of quantization is not useful)
2. The candidate region is divided into kxk units, and the boundary of each unit is not quantized. (The second round of quantization is not useful)
3. Calculate the fixed four coordinate positions in each unit (divide this unit into four small squares and then take their respective center points), use bilinear interpolation The method calculates the values of these four positions, and then performs the maximum pooling operation.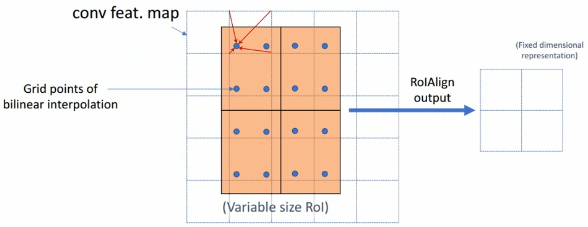
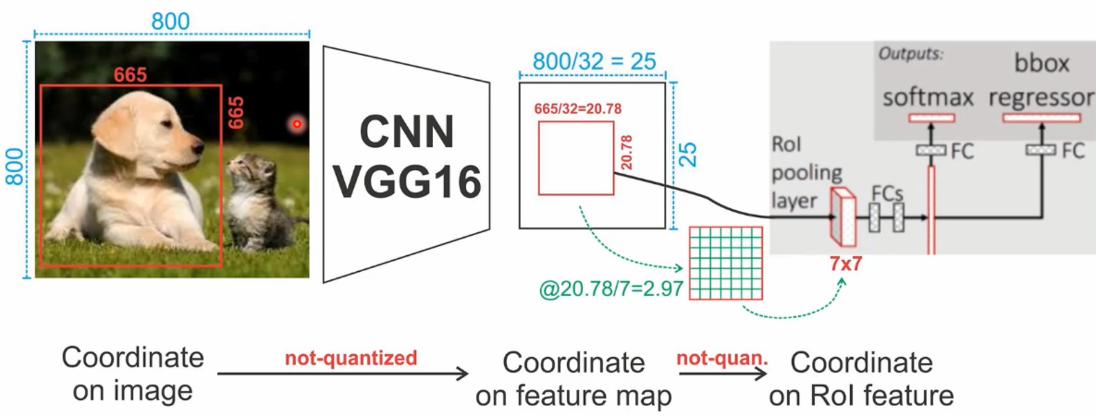
1. 800x800 original picture with a 665x665 prediction box;
The original image is convolved with Vgg6, and the final result is reduced by 32 times. The prediction frame is reduced by 32 times and the size is 20.78;
2. RoI pooling, divided into 7x7 = 49 parts, each part is 20.78 / 7 = 2.97;
3. Assuming that for the first unit, take 4 points and calculate the coordinate position (divide this unit into four small squares and then take their respective center points), use double The method of linear interpolation calculates the values of these four positions, and then performs the maximum pooling operation. In this way, the first unit value is obtained;
4. By analogy, 49 cell values were obtained
Mask R-CNN cost function definition
with
Only the positive samples will work. And in Mask R-CNN, there are some slight adjustments compared to Faster R-CNN. For example, the positive sample is defined to be greater than 0.5 with the ground truth loU (0.7 in Faster R-CNN).
The output for each Rol in the mask branch is
, Indicating that the K dimensions are
The binary mask, K is the number of object categories.
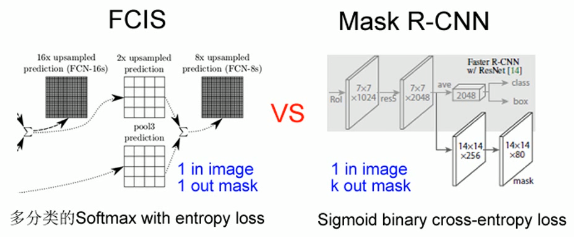
Instead of using FCN-style Softmax Loss, the author outputs K Mask prediction maps (each class outputs a mask), which is calculated pixel by pixel using the activation function Sigmoid. All The cost function is the cross entropy corresponding to sigmoid, also known as aver age binary cross-entropy.
Intelligent Recommendation

Mask R-CNN-Paper Notes-Understanding
paper:Mask R-CNN Thesis translation: Understanding reference: Core Technology: To a certain extent, Mask R-CNN can be understood as an upgraded Faster R-CNN. On the basis of Faster R-CNN, a branch net...
Mask R-CNN paper reading notes
table of Contents 1. Introduction to Literature Abstract 2. Introduction to the network framework 3. Experimental analysis Four, conclusion This article is a bit long, please read it patiently, there ...
Mask R-CNN introduction and paper notes
This article is for beginners of Mask R-CNN, aiming to sort out the general ideas and understand the basic concepts of the framework. Since I am now a senior and have just entered the field of deep le...
[Detectron2] Mask R-CNN code notes
The main code file path: General architecture file:detectron2/detectron2/modeling/meta_arch/rcnn.py default allocation:detectron2/detectron2/config/defaults.py RPN_head:detectron2/detectron2/modeling/...
Mask-R-CNN Study Notes | Deep Learning
Mask R-CNN for Object Detection and Segmentation Based on deep neural networksMask R-CNN, implement it using TensorFlow. Thanks to He Kaiming and others for their amazing achievements, thesis portal:M...
More Recommendation
Mask R-CNN --Mask R-CNN
According to a number of articles, only for reference to learn from each other. Mask R-CNN Effectively detects targets in the image while also generating a high-quality segmentation mask for eac...

Mask R-CNN
Link to the paper: https://arxiv.org/abs/1703.06870 First, the introduction Mask R-CNN is a masterpiece of He Kaiming in 2017. It performs segmentation while performing target detection and achieves e...

Mask R-CNN translation
Mask R-CNN translation Summary We propose a conceptually simple, flexible and versatile object instance segmentation framework. Our method efficiently detects targets in an image while generating a hi...

Introduction to Mask R-CNN
I. Overview Mske r-cnn is a network architecture based on the fast rcnn, which mainly completes the semantic segmentation of the target individual. The main idea of the paper is to expand the origin...

Mask R-CNN parse
Mask R-CNN parse Paper ideas Mask -RCNNFirst pictures do testing, to identify the ROI in the image, pixel correction using ROIAlign each ROI, a...