Mask R-CNN Intensive
tags: maskrcnn
1. Introduction
In principle Mask R-CNN is an intuitive extension ofFaster R-CNN, yet constructing the mask branch properlyis critical for good results. Most importantly, Faster RCNNwas not designed for pixel-to-pixel alignment betweennetwork inputs and outputs. This is most evident inhow RoIPool [18, 12], the de facto core operation for attendingto instances, performs coarse spatial quantizationfor feature extraction. To fix the misalignment, we proposea simple, quantization-free layer, called RoIAlign, thatfaithfully preserves exact spatial locations. Despite being a seemingly minor change, RoIAlign has a large impact: itimproves mask accuracy by relative 10% to 50%, showingbigger gains under stricter localization metrics. Second, wefound it essential to decouple mask and class prediction: wepredict a binary mask for each class independently, withoutcompetition among classes, and rely on the network’s RoIclassification branch to predict the category. In contrast,FCNs usually perform per-pixel multi-class categorization,which couples segmentation and classification, and basedon our experiments works poorly for instance segmentation.
- Mask R-CNN is increased on the basis of a branch on a Faster R-CNN.
- Faster R-CNN not to pixel - to - pixel prediction, using the R-CNN RoIPool Faster extracted feature space is very rough. In order to (fix the mislignment, the article proposes RoIAlign reservations precise spatial location information.
RoIAlign effects:
(1) improve the mask accuracy 10% -50%.
(2) separation of the prediction mask and categories, the article with a "binary mask", to predict whether this fall into this category (category does not need to compete) in the same class, then, according to the branch prediction RoI classification category.
(3) In contrast, FCNs multi-class prediction is usually performed at the level of each pixel (multi-class categorization), the joint segmentation and classfication up. But this is not good for instance segmentation of predictions.
Without bells and whistles, Mask R-CNN surpasses allprevious state-of-the-art single-model results on the COCOinstance segmentation task [28], including the heavilyengineeredentries from the 2016 competition winner. Asa by-product, our method also excels on the COCO objectdetection task. In ablation experiments, we evaluate multiplebasic instantiations, which allows us to demonstrate itsrobustness and analyze the effects of core factors.Our models can run at about 200ms per frame on a GPU,and training on COCO takes one to two days on a single8-GPU machine. We believe the fast train and test speeds,together with the framework’s flexibility and accuracy, willbenefit and ease future research on instance segmentation.Finally, we showcase the generality of our frameworkvia the task of human pose estimation on the COCO keypointdataset [28]. By viewing each key point as a one-hotbinary mask, with minimal modification Mask R-CNN canbe applied to detect instance-specific poses. Mask R-CNN surpasses the winner of the 2016 COCO keypoint competition,and at the same time runs at 5 fps. Mask R-CNN,therefore, can be seen more broadly as a flexible frameworkfor instance-level recognition and can be readily extended to more complex tasks.We have released code to facilitate future research.
2. Related Work
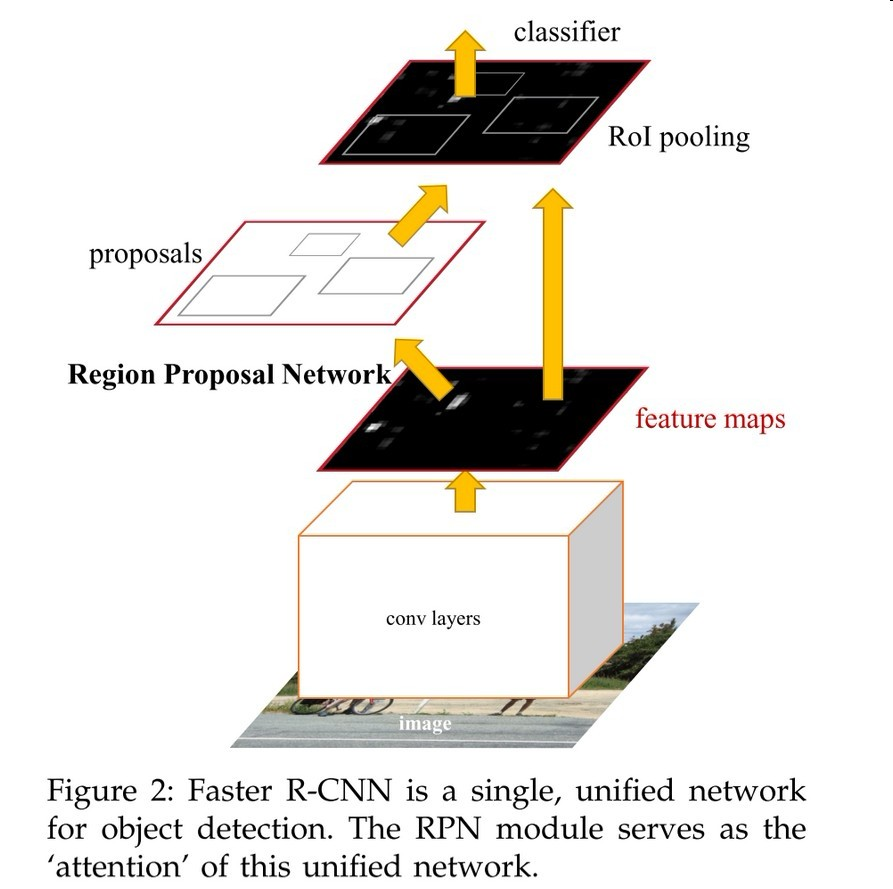
R-CNN: The Region-based CNN (R-CNN) approach [13]to bounding-box object detection is to attend to a manageablenumber of candidate object regions [42, 20] and evaluateconvolutional networks [25, 24] independently on eachRoI. R-CNN was extended [18, 12] to allow attending toRoIs on feature maps using RoIPool, leading to fast speedand better accuracy. Faster R-CNN [36] advanced thisstream by learning the attention mechanism with a RegionProposal Network (RPN). Faster R-CNN is flexible and robustto many follow-up improvements (e.g., [38, 27, 21]),and is the current leading framework in several benchmarks.
1. R-CNN
R-CNN (the region-based cnn), evaluated in a separate bounding-box with the RoI detection target candidate region. Fast, Faster RCNN is to transform the RCNN basis.
2. Instance Segmentation
3. MASK RCNN
Faster RCNN each candidate object has two outputs, one of the classification label, the other of the bounding-box is offset. MASK RCNN added a third branch, the output target mask, much more refined than the Faster RCNN
Faster RCNN:
stage1: RPN proposed candidate target bounding-box,
stage2: From each candidate bounding-box, the extraction features with RoIPool, and classification and regression bounding-box. Configuration as shown in FIG. [21] The article compares https://arxiv.org/pdf/1611.10012.pdf about Faster RCNN and other frameworks


Mask RCNN
stage1,2 RCNN consistent with faster, but at the same time stage2 (class prediction and box offset) is, Mask RCNN Mask RoI each binary output. The majority of the system and now are not the same, most of the systems, a classification is given of the received mask [33,10,26].
Each sample RoI of malti-task loss: L = L (cls) + L (box) + L (mask). Definition of L (cls) and L (box) and consistent of fast RCNN. mask dimensions of each output branch is RoI Km ^ 2, K two Masks (categories) resolution of m × m. Used here per-pixel sigmoid, define L (mask) is the average binary cross-entropy loss. When a true value RoI and comparing k-class, Lmask only affected by the k-thmask, do not affect each other between the k masks.
This shows that, Lmask definition allows network masks generated for each class,Competition between these categories are not mutually. Article predict category classification based on dedicated branch and select the mask output.This allows separation of the mask and the class predicted it. FCNs and compared with a much different, FCNs in each pixel softmax classification, such as a K classes, it will be divided into the pixel values 0,1,2,3 ... K, and calculated by the loss multinominal (multiple) cross-entropy loss. FCNs in masks cross classes compete. In this article, each pixel sigmoid calculated using binary loss.
MASK Rrepresatation
MASK the object space frame inputted outputs (encodes). Therefore, unlike the class labels or box offsets as the target output into a vector, mask structures can be extracted spatial pixel to pixel level.
From each of the RoI, m × m mask prediction with FCN. This makes mask branches each layer can get a clear frame m × m objective space, need not be folded into Vector (I guess the vector is two-dimensional, there is no spatial information), to the lack of spatial dimension of the vector.
Such pixel-to-pixel behavioral characteristics required RoI (RoI wherein a very small graphs) and capable of corresponding to each corresponding pixel space. So with RoIAlign.
RoIAlign:
RoIPool is extracted from each of small features RoI FIG standard procedures. RoIPool RoI a first floating-point number into discrete values characteristic of FIG using maxpool feature extraction. Analogy: In a continuous coordinates x, calculating [x / 16], 16 is a characteristic diagram of the stride, rounding [.]. Quantization is this: it is subdivided into bins (such as 7 * 7). Specific RoI principle: https: //blog.csdn.net/lanran2/article/details/60143861. Why divide stride see here: https: //www.cnblogs.com/soulmate1023/p/5557161.html. This quantization method in RoI and extracted features, will produce misalignments.
The entire period of someone else's description: https: //blog.csdn.net/diligent_321/article/details/78397693
(1) regression RPN network branch predicted coordinates of the candidate region, RPN loss function can be seen from the network, the value of the predicted coordinate is relative to the size of the input image, and the predicted coordinate is a floating point value, so rounding operations to obtain a candidate region, it is used in the article "quantize", actually rounding operation;
(2) The RoI partitioned into containers (bins), and each container for each pixel max pooling operation, but when dividing the container, such as dividing into macroreticular RoI of 7 × 7, if RoI length and width is not a multiple of 7, it would to rounding operation, so there are also quantization operation.
So the question is, above two models to quantify what impact it? For classification and regression tasks, nature is no effect, but for segmentation task, since the output pixels in the image is the result of the input image segmentation, so there is one mapping between pixels, can not have the top the rounding operation. We imagine hypotheses rounding operation before the output mask map, then some of the pixel output figure does not necessarily correspond to the real groundtruth, it will certainly affect the accuracy of image segmentation。
So proposed RoIAlign layer. Removing the link RoI edge or quantization bins (using x / 16 instead of [x / 16]), the article is calculated using bilinear interpolation bilinear interpolation in FIG. 4 wherein a fixed sampling points in each bin all RoI value, and the integration of four sampling points is worth the results (max or average). As shown below: wherein the broken line represents a grid, a solid line is a RoI (2 * 2bin), a black dot represents four sampling points. RoIAlign is the use of four values on the grid in the vicinity of the characteristic diagram is calculated using bilinear interpolation for each sampling point. No quantified.

Network Architecture
In (i) convolutional backbone used to extract the whole structure of the sub-network of FIG feature and (ii) head is used to identify the network structure of the bounding-box were used in the prediction of the mask.
On ResNet and ResNeXt have done a test. Backbone structures named network-depth-feature. ResNet layer 50. Faster-R-CNN is the 4th stage extraction features in the final layer with convolutional ResNets, herein named C4. Well, this backbone is called ResNet-50-C4
head network, before we follow Faster RCNN structure, adds a parallel mask operation.
3.1 Implementation details
Article set hyperparametric
training: IoU> 0.5 is positive then the RoI of. Lmask is defined only on the positive RoI. mask target is a real mask and RoI intersection. Articles with central training images (image-centric) training. Picture resized to 800 pixels, each mini-batch have two maps, a GPU. Each figure has N samples RoIs, positive and negative amount ratio is 1: 3 (Release not know how this came). In the C4 backbone, N = 64, FPN of N = 512. 8 GPUs us on training (mini-batch size = 16) 160k iterations, learning = rate = 0.02, dropped to 10 when 120k iteration. weight decay = 0.0001, momentum = 0.9.
RPN anchors 5 scales, 3 aspect ratio, the RPN training alone, and no Mask RCNN sharing feature,Unless otherwise specified. In this paper, they are shared.
First wrote this, follow-up will analyze the code
Intelligent Recommendation
Mask R-CNN understanding
Introduction to the MASK RCNN algorithm: Mask-RCNN is another masterpiece of He Kaiming after Faster-RCNN. It integrates two functions of object detection and instance segmentation, and surpasses Fast...

Mask R-CNN model
data preparation To train the Mask R-CNN instance division model, we must first prepare the image mask (MASK), use the annotation toollabelme(Support for Windows and Ubuntu, use (SUDO) PIP Install Lab...
Mask R CNN stepping on
The Mask RCNN recovery process is too painful to record each deep pit. 1.Apex installation failed CUDA version 10.0 Pytorch1.0.0 Input according to official install.md Report: Query N websites and fin...

From R-CNN to Mask R-CNN
From R-CNN to Mask R-CNN Article directory: First, R-CNN Second, Fast R-CNN Third, Faster R-CNN Fourth, Mask R-CNN Fifth, expand 1、FCN Since the CNN-based approach in the 2012 ILSVRC competition has b...

Mask R-CNN paper notes
Essay topic:Mask R-CNN Paper link:Paper link Paper code:FacebookCode link;Tensorflow versionCode link;Keras and TensorFlow versionCode link;MxNet versionCode link 1. What is Mask R-CNN and what can be...
More Recommendation
A small program acquires the data on the previous page
A small program acquires the data on the previous page...
53. The maximum and subsequence
Dynamic Programming CurSum rightmost position of the maximum recording sequence, res record the actual maximum. After a partition to do, first of all about the array is divided into three parts, to fi...

13 non-overlap intervals (Leecode 435)
1 problem A collection of a range, find the minimum number of intervals to remove, so that the remaining intervals do not overlap. note: It can be considered that the end point of the interval is alwa...
Java-commodity project
Create an Articleset class, open a commodity warehouse, used to store product elements Create an ArticleManage class, call the Article class and Articles, And achieve a rendezvous change...
MP3 soft solution
1. Download the MAD package. libmad-0.15.1b Check all the information to compile OK on the PC. 2. Download MADLD-1.1P1. All information can be found on Github. MAD_STREAM_BUFFER combined data MAD_FRAM...