Interpretation of Mask R-CNN paper based on instance segmentation algorithm
tags: Semantic segmentation
Foreword
We have talked more about the target detection algorithm of Anchor-Based. In addition, we have briefly interpreted the target detection of Anchor-Free. DenseBox has started, and today we will talk about another direction, that is, instance segmentation. The first example of instance segmentation that needs to be introduced is the 2017 masterpiece of He Kaiming God, Mask-RCNN, which performs instance segmentation while performing target detection, and has achieved excellent results, and won the 2016 COCO instance segmentation competition champion.
Overview
Mask-RCNN is an instance segmentation (Instance segmentation) framework. By adding different branches, it can complete various tasks such as target classification, target detection, semantic segmentation, instance segmentation, and human pose estimation. For instance segmentation, a branch is added for semantic segmentation on the basis of Faster-RCNN (classification + regression branch), and its abstract structure is shown in Figure 1:
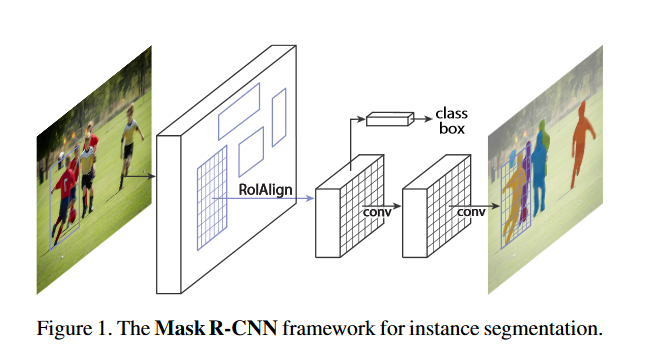
Describe this structure a bit:
- Enter the original image after preprocessing.
- The input picture is sent to the feature extraction network to obtain the feature map.
- Then set a fixed number of ROI (also called Anchor) for each pixel position of the feature map, and then send the ROI area to the RPN network for binary classification (foreground and background) and coordinate regression to obtain the refined ROI area .
- Perform the ROIAlign operation proposed in the paper on the ROI area obtained in the previous step, that is, first match the original image with the pixel of the feature map, and then map the feature map to the fixed feature.
- Finally, perform multi-category classification on these ROI regions, candidate box regression and the introduction of FCN to generate Mask to complete the segmentation task.
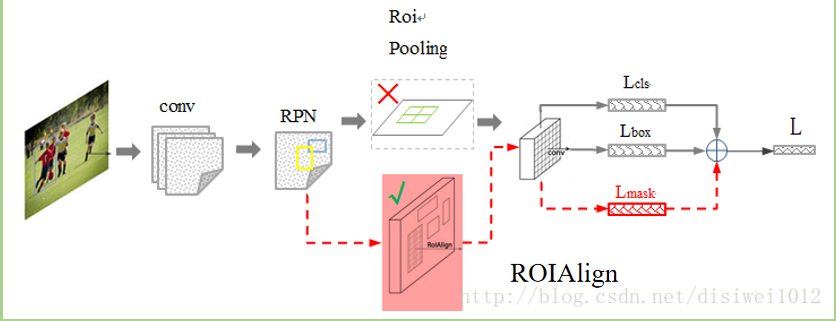
The following figure shows the overall framework of Mask-RCNN more clearly, from knowing usersvision:
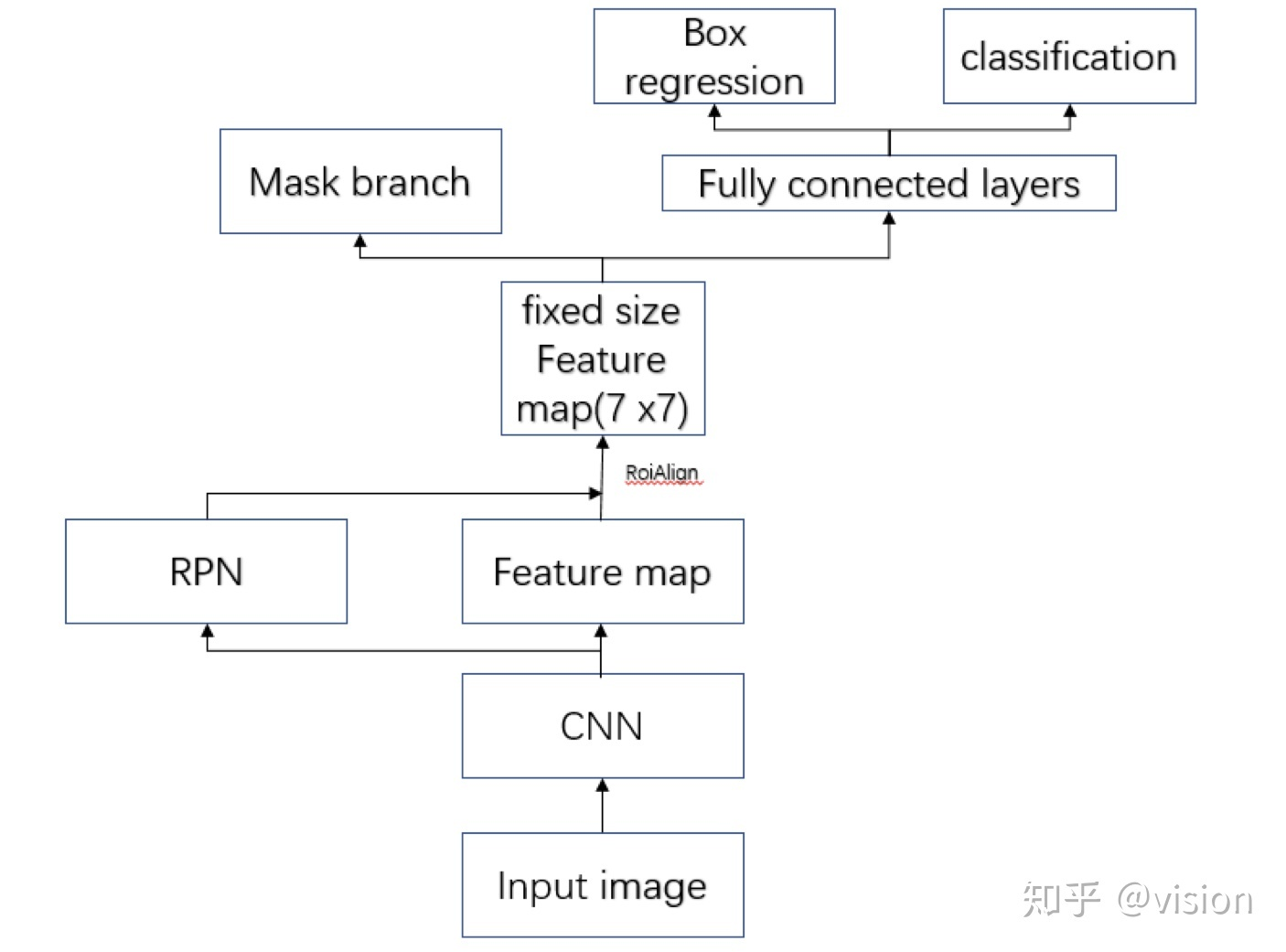
method
Problems with original ROI Pooling
The process of ROIPooling in Faster-RCNN is shown below:
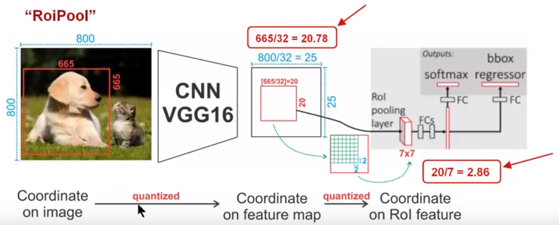
The size of the input picture is
, Where the size of the target box for the dog is
The size of the feature map obtained after passing through the VGG16 network is
,among them
On behalf of VGG16
Second downsampling (step size 2) operation. Similarly, for the goal of dogs, we map it to the feature map and the result is
Because the coordinates need to retain integers, the first quantization error is introduced here, which discards the floating-point part of the target frame corresponding to the length and width on the feature map.
Then we need to convert this The ROI area is mapped as ROI feature map, according to the calculation method of ROI Pooling, the result is , The size of the ROI feature area after performing the rounding operation is also Here, the second quantization error is introduced.
It can be seen from the above analysis that these two quantization errors will cause deviations between the pixels in the original image and the pixels in the feature map. For example, the above will Quantified as Was introduced when Deviation, this deviation is mapped back to the original image is It can be seen that this pixel deviation is very large.
ROIAlign
In order to alleviate the shortcomings of ROI Pooling quantization error is too large, this paper proposes ROIAlign, ROALIgin does not use quantization operation, but uses bilinear interpolation. It makes full use of the virtual pixel values in the original image as Four real pixel values around to determine a pixel value in the target image The output pixel values corresponding to similar non-integer coordinate value pixels are estimated. This process is shown below:

where feat. map is the feature map obtained by VGG16 or other Backbone network, the solid black line indicates the ROI division method, and the size of the final output feature map is
, And then use bilinear interpolation to estimate the pixel values of these blue points, and finally get the output, and then perform the Pooling operation in the orange-red area and finally get
Output characteristic map. It can be seen that this process does not introduce any quantization operation compared to ROI Pooling, that is, the pixels in the original image and the pixels in the feature map are completely aligned, and there is no deviation, which will not only improve the detection accuracy, but also benefit Instance segmentation.
Network structure
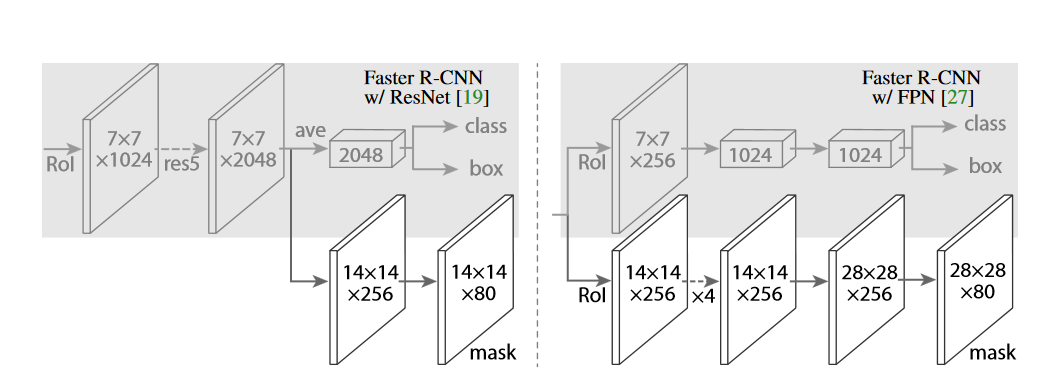
In order to prove the versatility of the sub-network, the paper constructed Mask R-CNN with a variety of different structures, specifically using the Backbone network andwhetherWill be used for frame recognition and Mask predictionupper layerThe network is applied to each ROI separately. For the Backbone network, Mask R-CNN basically uses the previously proposed architecture, while adding a fully convolution Mask (mask) prediction branch. Figure 3 shows two typical Mask R-CNN network structures, the one on the left uses or Use the backbone of the network to extract features. The network on the right uses the FPN network as the backbone to extract features. The introduction of these two networks can be found in the previous article of the public account. The final author foundThe backbone using ResNet-FPN as feature extraction has higher accuracy and faster running speed, So most of the actual work uses the fully parallel mask/classification regression on the right.
Loss function
Mask branch generates one for each ROI area
Output characteristic map of
Pc
Of binary mask images, where
Represents the number of target categories. Mask-RCNN has an additional ROIAligin and Mask prediction branch based on Faster-RCNN, so the loss of Mask R-CNN is also a multi-task loss, which can be expressed as the following formula:
where
Represents the classification loss of the prediction box,
Represents the regression loss of the prediction box,
Represents the loss of the Mask part.
For the predicted binary mask output, the paper applies to each pixelsigmoidFunction, the overall loss is defined as the average binary cross loss entropy. Introduce a mechanism to predict K outputs, allowing each class to generate an independent mask to avoid competition between classes. This decouples the mask and type prediction. Unlike the FCN approach, it is applied on every pixelsoftmaxFunction, the overall multi-task cross-entropy, which will lead to competition between classes and ultimately result in poor segmentation.
The following figure more clearly shows the calculation of the loss of the Mask prediction part of Mask-RCNN, which comes from knowing the uservision:
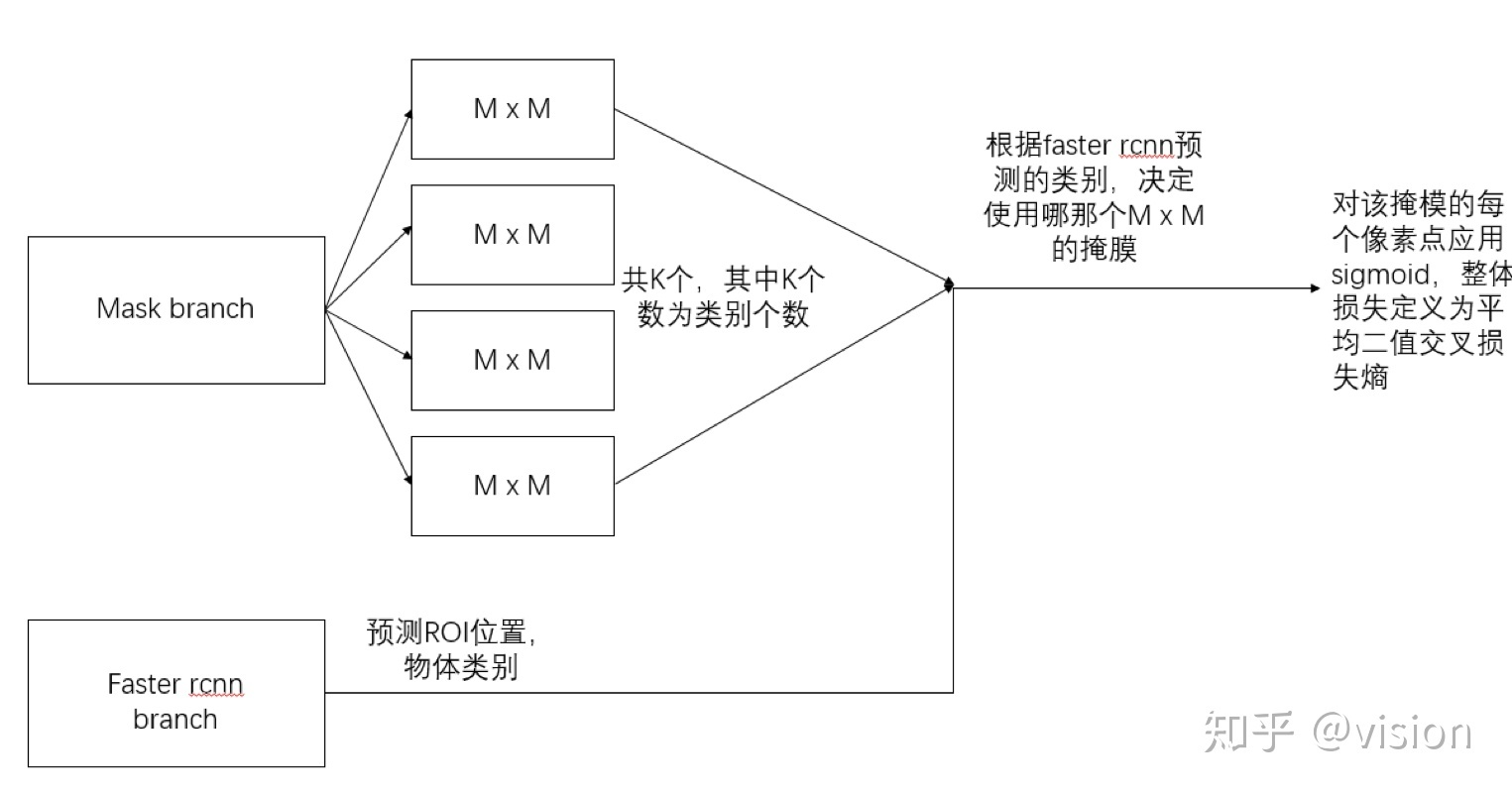
training
In Faster-RCNN, if the ROI area and GT boxIOU>0.5, Then the ROI is a positive sample, otherwise it is a negative sample.
Only defined on positive samples, and Mask's label is the intersection of ROI and its corresponding Ground Truth Mask. Some other training details are as follows:
- Image-centric training is used to scale the smaller side of the picture to 800 pixels.
- Per GPU
mini-batch=2, Each picture has Sampling ROIs, where the proportion of positive and negative samples is1:3。 - Training on 8 GPUs,
batch_size=2, Iteration160kTimes, initial learning rate0.02, In section120kDecrease by 10 times at each iteration,weight_decay=0.0001,momentum=0.9。
test
During the test phase, theproposalsThe numbers are
(Faster-RCNN) and 1000 (FPN). In theseproposalsOn, usebboxPredictive branch post-processingnmsTo predictbox. Then use Mask to predict the highest branch pairscore100 detection frames are processed. It can be seen that this method is different from the Mask prediction parallel processing during training. This is mainly to accelerate the inference efficiency. Then, the Mask network branch predicts each ROI
Mask images, but here we only need to use the mask image with the highest category probability, and then use this mask imageresizeBack to the ROI size, and to0.5The threshold value is binarized.
experiment
Overview
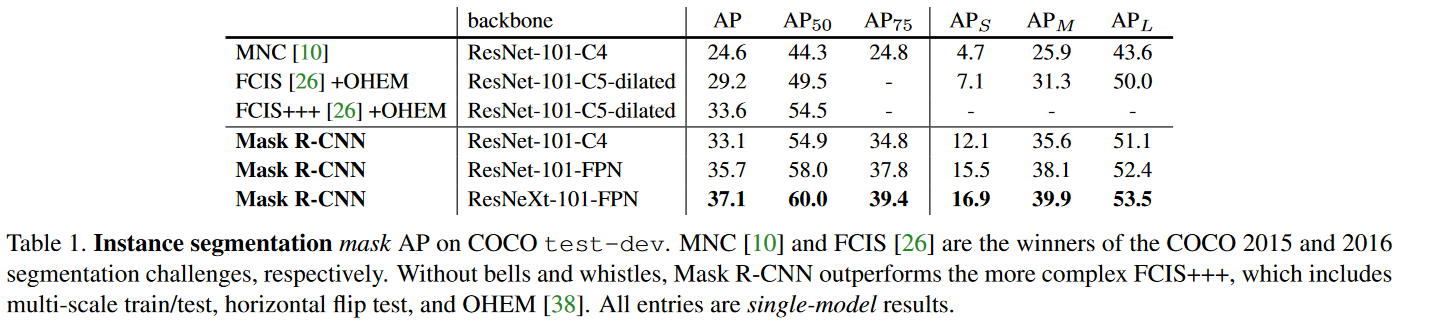
Very SOTA, Mask R-CNN defeated the upper champion FCIS (which used multi-scale training, horizontal flip test, OHEM, etc.), the specific results are shown in Table 1:
 Let's take a look at some visualization results, as shown in Figure 5.
Let's take a look at some visualization results, as shown in Figure 5.

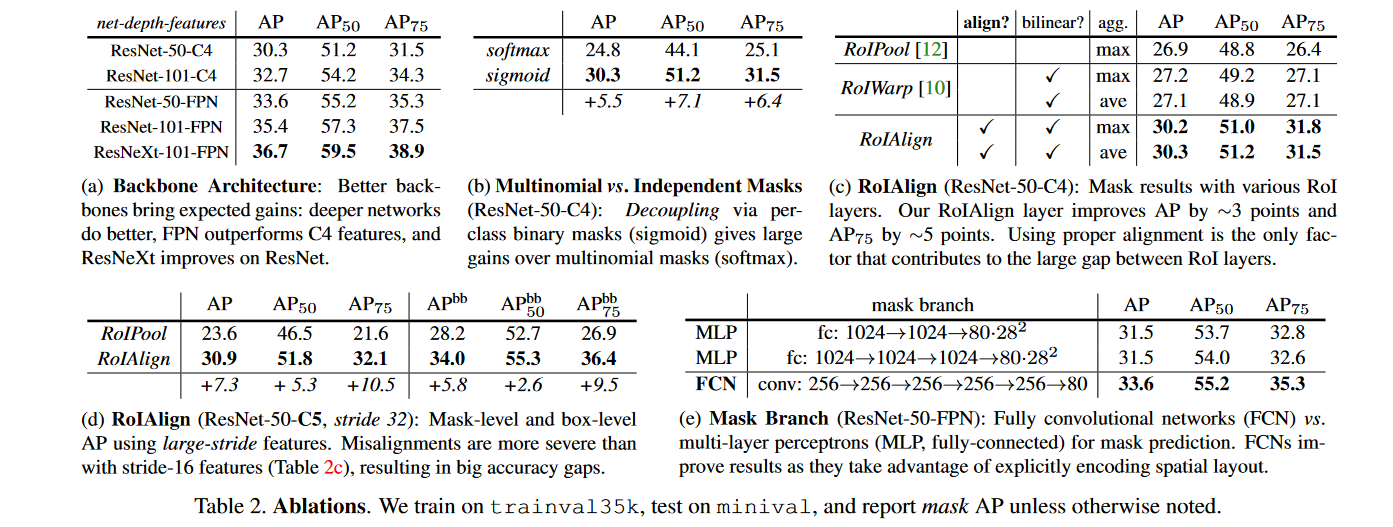
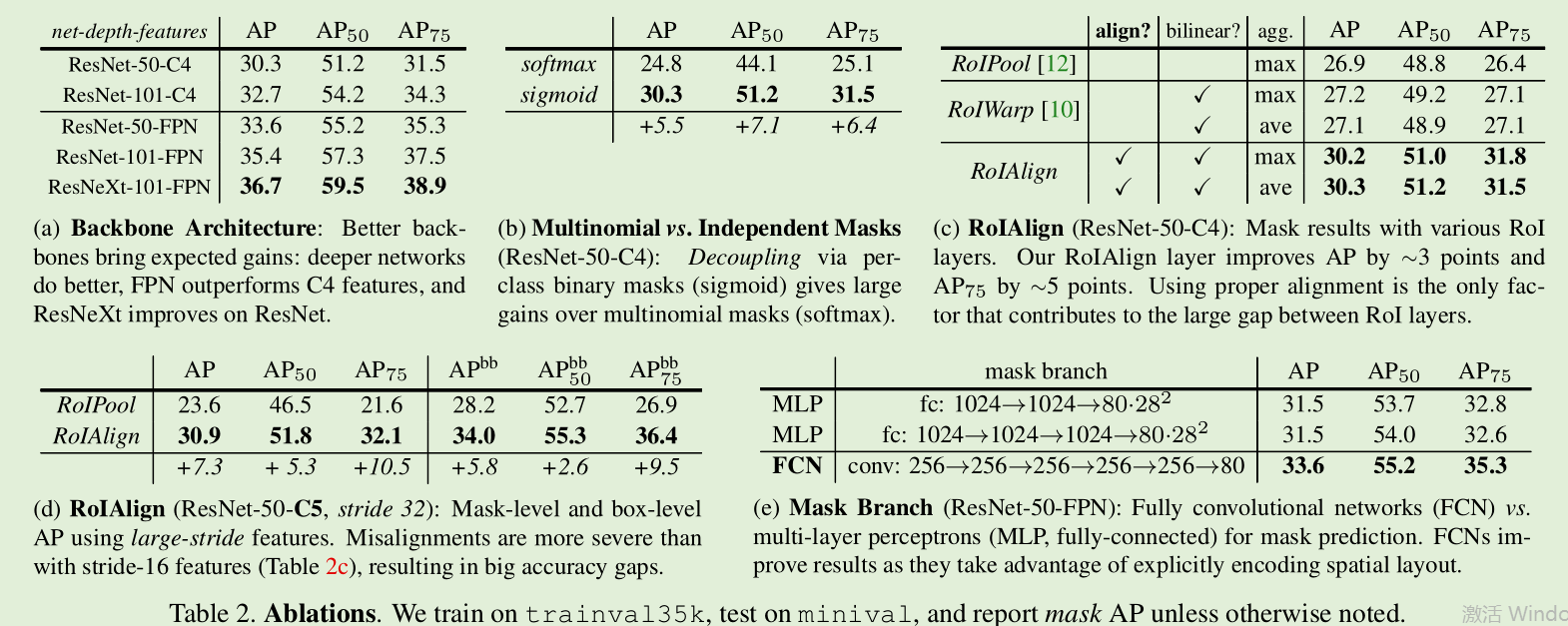
Ablation experiment
Table 2 shows the ablation experiment of Mask-RCNN,(a)The deeper the display network, the better the effect. And the FPN effect is better. and(b)displaysigmoidComparesoftmaxThe effect is better.(c)with(d)It shows that the ROIAligin effect has improved, especially the AP75 improvement is the most obvious, indicating that it is very useful for accuracy improvement.(e)It shows that mask banch uses FCN better (because FCN does not destroy the spatial relationship).
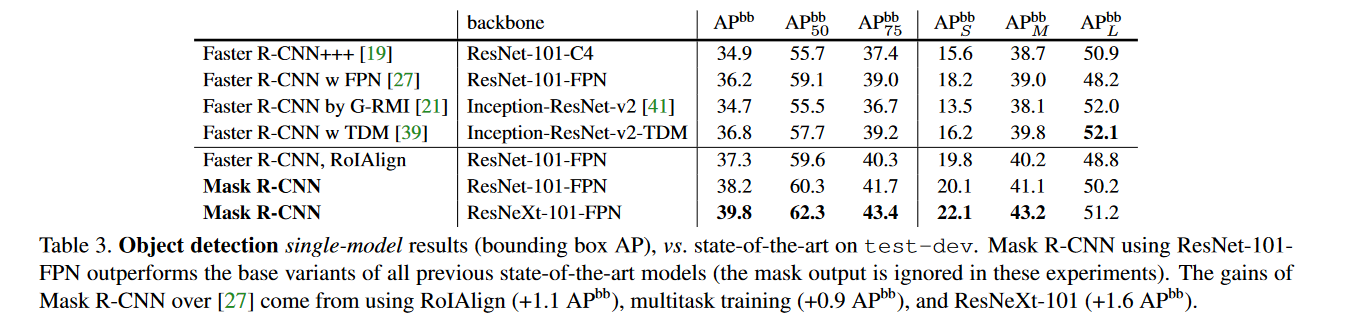
Comparison of target detection results
As can be seen from Table 3, even if the Mask branch is not used during prediction, the result accuracy is very high. It can be seen that ROIAligin is directly used on Faster-RCNN, which is 0.9 points higher than ROI Pooling, but 0.9 points lower than Mask-RCNN.The author attributed it to the improvement of multi-task training. Due to the addition of the mask branch, the loss change brought indirectly affected the effect of the backbone network.
Key point detection
Compared with Mask-RCNN, the key point detection is to change the Mask branch intoheatmapRegression branch, it should be noted that the final output is
Formsoftmax, Is no longersigmoid, The paper mentioned that this is conducive to the detection of a single point, and the final Mask resolution is
,Is no longer
。

postscript
Later I will update the detailed analysis of the Mask R-CNN code, and analyze the details of the Mask R-CNN from the code perspective. The paper analysis will be here for the time being.
appendix
- Original paper: https://arxiv.org/pdf/1703.06870.pdf
- Reference materials: https://blog.csdn.net/chunfengyanyulove/article/details/83545784
Welcome to GiantPandaCV, where you will see exclusive deep learning sharing, stick to originality, and share the fresh knowledge we learn every day. (• ̀ω• ́ )✧
If you have questions about the article, or want to join the communication group, welcome to add BBuf WeChat:

Intelligent Recommendation

Keras build Mask R-CNN instance segmentation platform
Articles directory Mask R-Cnn Introduction Engineering source code Mask R-CNN realize ideas 1. Prediction part 1. The main network introduction 2. Construction of characteristic pyramid FPN 3. Get the...

Examples of segmentation: Mask R-CNN
《Mask R-CNN》 Original link:https://arxiv.org/abs/1703.06870 The main point of this paper is Faster R-CNN has a predicted increase in predicted object mask (mask) a bounding box parallel branch based o...

Examples of the segmentation Mask R-CNN
Papers Address:Mask R-CNN Code Address:facebookresearch/Detectron Mask R-CNN is improved based on Faster R-CNN. Faster R-CNN is mainly used for object recognition, for example can be divided, Mask R-C...

[Thesis Interpretation] Mask R-CNN
[Interpretation of the paper] Facebook He Kaiming Mask R-CNN target instance segmentation Guide:Since the introduction of convolutional neural networks into the field of target detection, from rcnn to...

Mask R-CNN paper notes
Essay topic:Mask R-CNN Paper link:Paper link Paper code:FacebookCode link;Tensorflow versionCode link;Keras and TensorFlow versionCode link;MxNet versionCode link 1. What is Mask R-CNN and what can be...
More Recommendation

"Mask R-CNN" paper notes
1 Overview The paper proposes a simple and flexible example partitioning framework Mask R-CNN. This method can effectively detect the target in the image and generate a high quality segmentation mask ...

Paper notes -Mask R-CNN
In this paper, co-authored by Kaiming He FAIR and so on. 1 Introduction Mask R-CNN object detection may be performed simultaneously and segmentation task instance, the figure is its architecture: Mask...
Mask R-CNN paper analysis
Reference article:The link is here! Preface Tip: Mask R-CNN is improved on the basis of Faster R-CNN. (Roi pooling is replaced by roi align layer) One, Mask R-CNN structure Mask rcnn is an instance se...
Mask R-CNN paper learning
Basic information Title: Mask R-CNN Author: Kaiming He Georgia Gkioxari Piotr Dollár Ross Girshick Institution: Facebook AI Research (FAIR) Source: ICCV Time: 2017 Thesis address:https://arxiv....

KERAS framework: instance division Mask R-CNN algorithm implementation and implementation
Instance segmentation The difficulty of instance segmentation is: The location of the target is required and the target is divided, so this requires fusion target detection (position of the frame out)...