Day 3: MLP-Mixer: An all-MLP Architecture for Vision
tags: Thesis studies mlp artificial intelligence Machine learning Computer vision
This article is about the latest multi-level perception machine, the main contribution of the article is as follows
- The author said domineering: "Although convolutional and attention mechanisms have achieved a good performance, they are all unnecessary", "that is," all the spaces are XX ". Original: "in this paper we show what While Convolutions and Attention Arene Both Sufficles for Good Performance, Neither of Them Are Necessary."
- MLP-Mixer is primarily based on ancient multi-layer perception machine (MLP), which contains two Layer: an independently uses the MLP on the picture block to mix the characteristics based on each location (" Mixing "The pre-location features); a use of mlp between the picture block, used to mix spatial information (" MIXING "spatial information.)
- When used in a large data set and the MODERN Regularization Schemes, the result of approaching the SOTA can be obtained on the classification task.
- The author hopes that these results can inspire more people to dry down the video world LOL led by CNN and Transformer.
Method and implementation
Because I haven't been there yet, I will come back to write after I have seen it. Interestingly, the code is placed under the same reop of VIT.
- Mixer's structure is completely based on multi-layer perceptual machine MLP, and multi-layer perceived machine is repeatedly applied between spatial position, or between Mixer's Architecture is based EntireLy ON Multi-Layer Perceptrons (MLPS) That Are ReateDly Applied Across Either Spatial Locations Or Feature Channels.
- Mixer is purely based on basic matrix multiplication, transform of data layout (reshape or transposition), and nonlinear operation of the scalar.
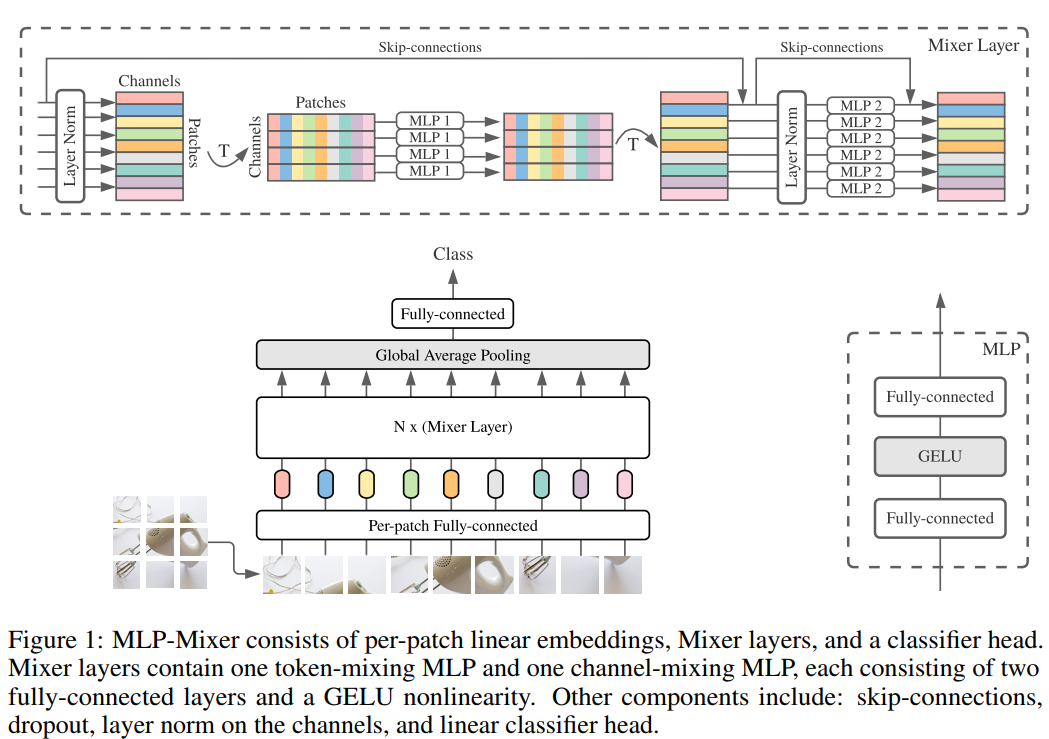
Structural map and rough introduction
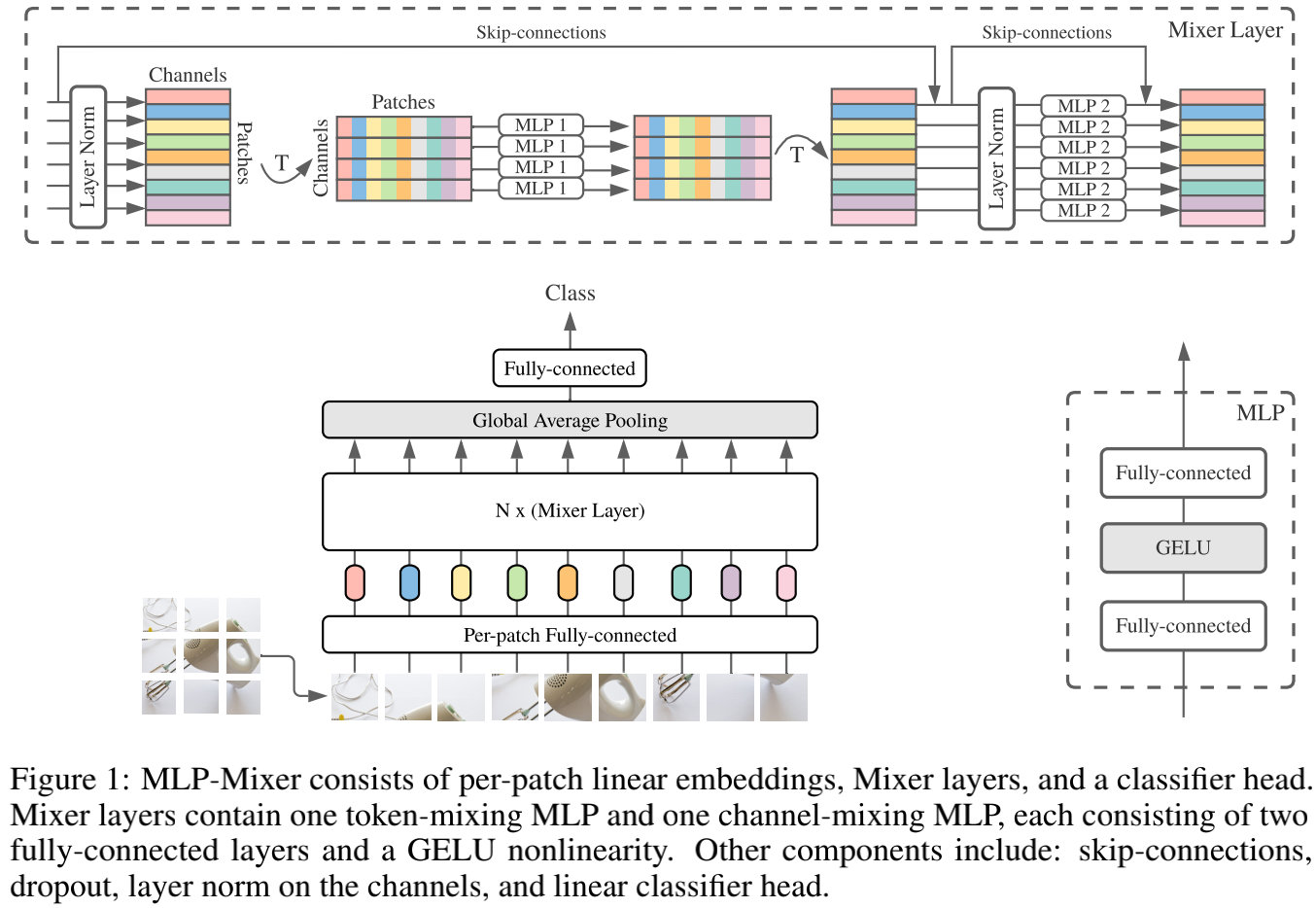
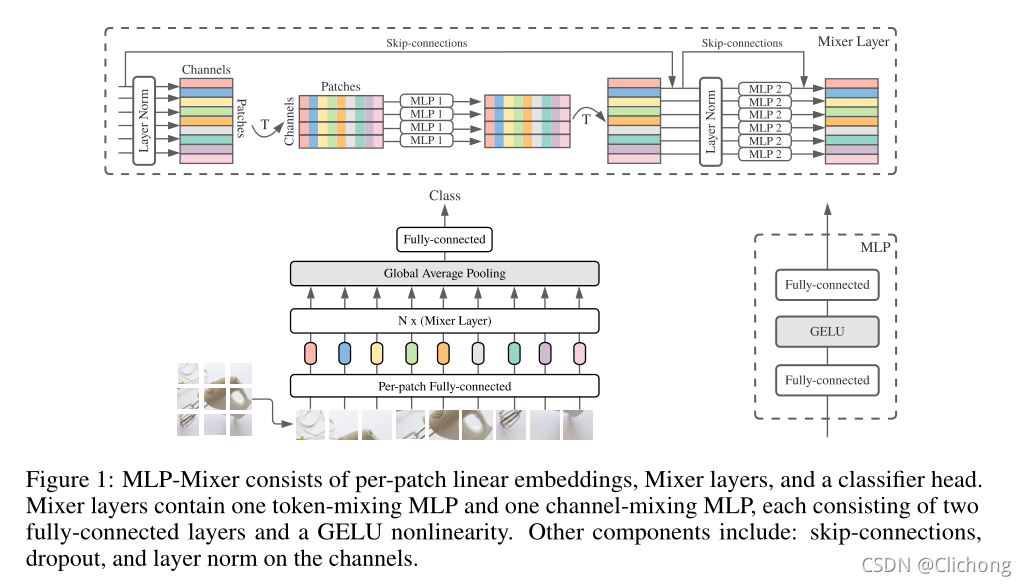
- First, the input picture is removed into a picture block (PATCH), and the linearly project is a token sequence, and arranged as a " p a t c h e s × c h a n n e l s patches \times channels patches×channels"The table is input and maintains this dimension.
- As mentioned above, Mixer has two MLP layers, a "Channel-Mixing MLPS), and another name is" token-mlp ".
- The Channel-Mixing MLP allows information between different channels, which operates independently on each TOKEN, as inputs each line of the above list. The Token-Mixing MLP allows information to be communicated (noug a different token) in different spatial locations, which is independently applied to each channel, and each column of the above list is input.
- These two MLPs are interlaced together, so that information between different dimensions interacts.
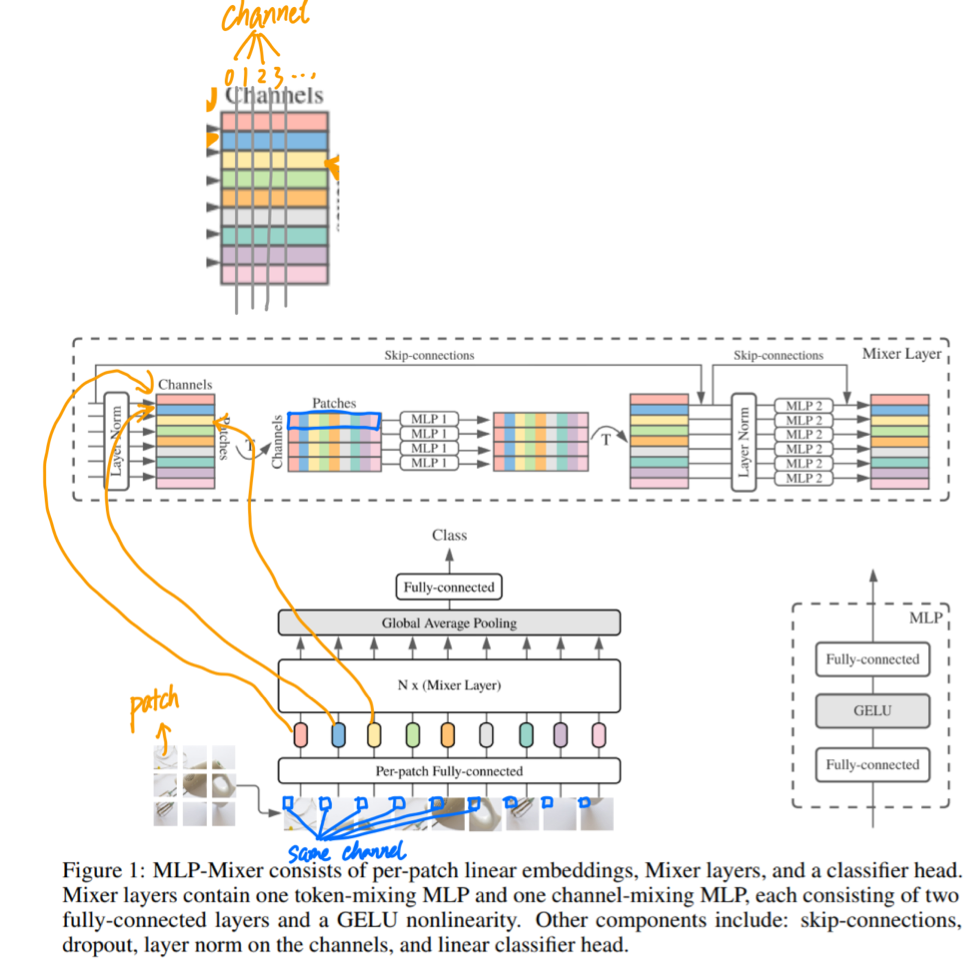
Insert a little personal understanding,
- In extreme cases, this model can be seen as a very special CNN, which is used 1 × 1 1 \times 1 1×1Convolutions are mixed on the channel, and symbolize symbols with single-channel Depth-Wise convolution and parameter sharing over the entire field of view.
- It should be noted that this is not the case (ie, CNN that is not able to meet the above conditions is the special case of the Mixer model), as a typical CNN is not the special situation of our Mixer model.
Mixer model detailed architecture
- The Mixer model is the most important IDEA, which explicitly separates the calculation between the arithmetic of each position (token-mixing)
- As shown in the configuration drawings above, Mixer consists of a sequence that does not overlap the picture block as an input (sequence length S), each picture block is mapped into a predetermined size (Hidden Dimension C), resulting It is a S × C S \times C S×C Size X X X, X ∈ R S × C \mathbf{X} \in \mathbb{R}^{S \times C} X∈RS×CIf the size of the original input picture is ( H , W ) (H,W) (H,W), The size of each picture block is ( P , P ) (P,P) (P,P)So the total of all picture blocks is S = H W / P 2 S = HW / P^2 S=HW/P2
- All picture blocks are
**the same one**Mapping matrix for mapping. - Layer in Mixer is equally sized, and each Layer consists of two MLP modules. The first module is the Token-Mixing MLP module, which is in X X XEvery column (in fact, first X X XTransposition X T X^T XT). The second module is the Channel-Mixing MLP module, which works X X XEach line.
- Each MLP module contains two full-connection layers, while a nonlinear layer is independently added to each line of the input. The overall structure is as follows:
U ∗ , i = X ∗ , i + W 2 σ ( W 1 LayerNorm ( X ) ∗ , i ) , for i = 1 … C , Y j , ∗ = U j , ∗ + W 4 σ ( W 3 LayerNorm ( U ) j , ∗ ) , for j = 1 … S . \begin{array}{ll}\mathbf{U}_{*, i}=\mathbf{X}_{*, i}+\mathbf{W}_{2} \sigma\left(\mathbf{W}_{1} \text { LayerNorm }(\mathbf{X})_{*, i}\right), & \text { for } i=1 \ldots C, \\\mathbf{Y}_{j, *}=\mathbf{U}_{j, *}+\mathbf{W}_{4} \sigma\left(\mathbf{W}_{3} \text { LayerNorm }(\mathbf{U})_{j, *}\right), & \text { for } j=1 \ldots S .\end{array} U∗,i=X∗,i+W2σ(W1 LayerNorm (X)∗,i),Yj,∗=Uj,∗+W4σ(W3 LayerNorm (U)j,∗), for i=1…C, for j=1…S.
- D S D_S DSwith D C D_C DCThey are the length of the hidden layer adjustable hidden layer in Token-Mixing and Channel-Mixing. D S D_S DSwith D C D_C DCThey are independently with the number of input picture blocks, so its computational complexity is related to the input image block.
- Although it may be seen on each channel in other places, each channel is used in separate convolution, and each channel is used; when Mixer's Token-Mixing, all channels The same volume is used in the convolution. Do this effectively prevent it from increasing S S Sor C C CThe rapid growth of the model caused.
- Surprisingly, this is still good
- The inputs of each layer in Mixer are fixed size, and transformer, RNN is a bit image.
- Mixer does not use location coding because token-mlp is very sensitive to the order of the input, so you can finalize how to represent location information.
Intelligent Recommendation

MLP-MIXER Detailed
MLP-MIXER Detailed paper《MLP-Mixer: An all-MLP Architecture for Vision》 1 main ideas As a CV framework that the Google VIT team recently raised, MLP-Mixer uses a multi-layer perceived machine (MLP) in...

Personal understanding of MLP-Mixer
main idea: to CHAfter Patch embedding is performed on the image of W, the spatial (global/local) information fusion part and the channel information fusion part are separated. In MLP-Mixer: Assuming t...

Paper reading notes | MLP series - MLP-Mixer
If there is any error, please point it out. paper:MLP-Mixer: An all-MLP Architecture for Vision code:https://github.com/google-research/vision_transformer summary: Researchers show that although both ...
ASMLP: An Axial Shifted MLP Architecture for Vision
This article is also an offset operation to improve local information extraction capabilities, and the offset is specifically implemented by each Feature Map along the H and W directions. also,Deep st...
MLP-Mixer: A full mlp network architecture for visual tasks [code implementation (based on mnist)]
This article is based on the MLP-Mixer-Pytorch on Github on GitHub to implement MLP-Mixer Demo on Mnist data. MLP-Mixer: An all-MLP Architecture for Vision[PDF] MLP-Mixer introduction and some ideas [...
More Recommendation
Thesis reading notes | MLP series-MLP part summary (MLP-MIXER, S2-MLP, AS-MLP, VIP, S2-MLPV2)
If there are mistakes, please point out. This blog is a summary of a summary of the summary of the MLP structure articles. Articles directory 1. MLP-Mixer 2. S2-MLP 3. AS-MLP 4. ViP 5. S2-MLPv2 1. MLP...
MLP-Mixer introduction and some ideas
Recently, Google Research's Brain Team also published a heavy article, pure MLP architecture ------MLP-MixerThis team is the original VIT team with strong strength. The authors have been compared with...
MLP-Mixer,External Attention,RepMLP
MLP-Mixer,External Attention,RepMLP Article catalog MLP-Mixer,External Attention,RepMLP MLP-Mixer:An all-MLP Architecture for Vision (Google) Beyond Self-Attention: External Attention Using Two Linear...
MLP-Mixer Introduction and PyToch Code
MLP-Mixer Introduction and PyToch Code Mlp-Mixer Network structure TIPS to sum up reference Mlp-Mixer Paper:MLP-Mixer: An all-MLP Architecture for Vision. Pytorch code:An unofficial implementation of ...
DL-PAPER Entities: MLP-Mixer
MLP-Mixer: An all-MLP Architecture for Vision Paper (Grand Factory is always do not go to the common road, this summary does not follow the past reading mode) Recently, Google has released a papers &q...