Personal understanding of MLP-Mixer
tags: computer vision

main idea:
to CHAfter Patch embedding is performed on the image of W, the spatial (global/local) information fusion part and the channel information fusion part are separated.
In MLP-Mixer:
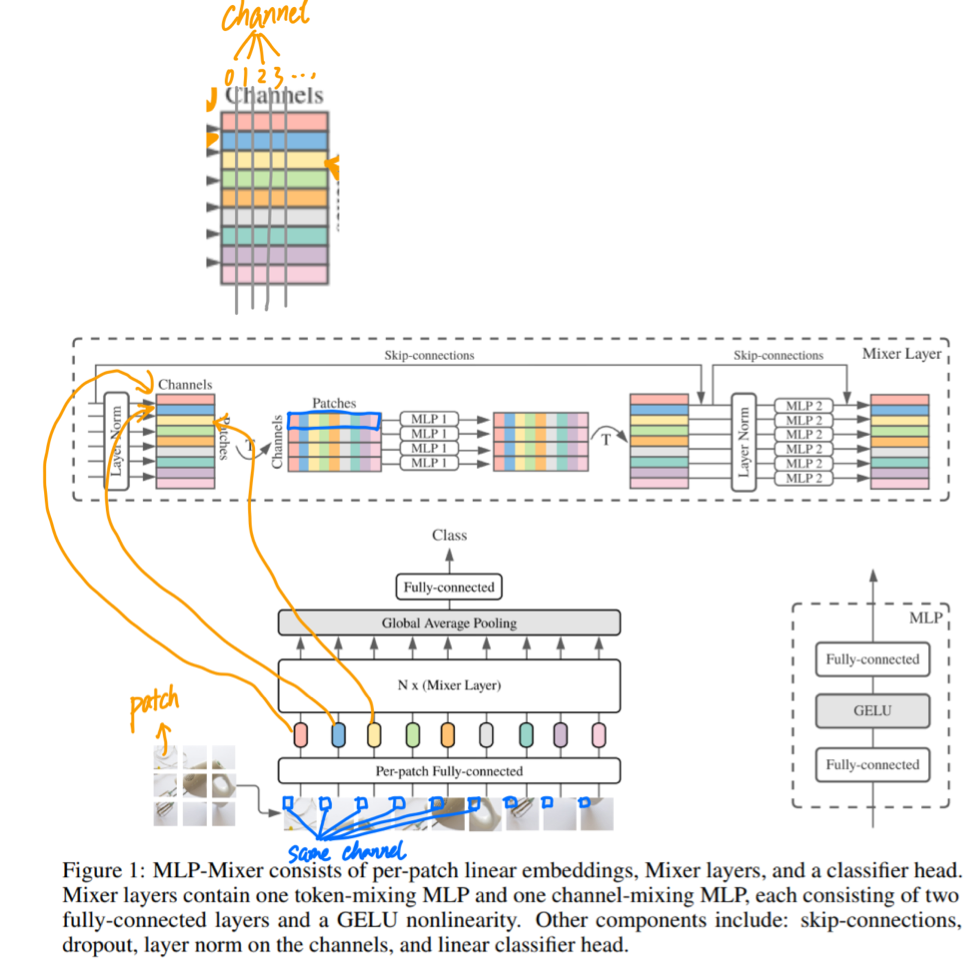
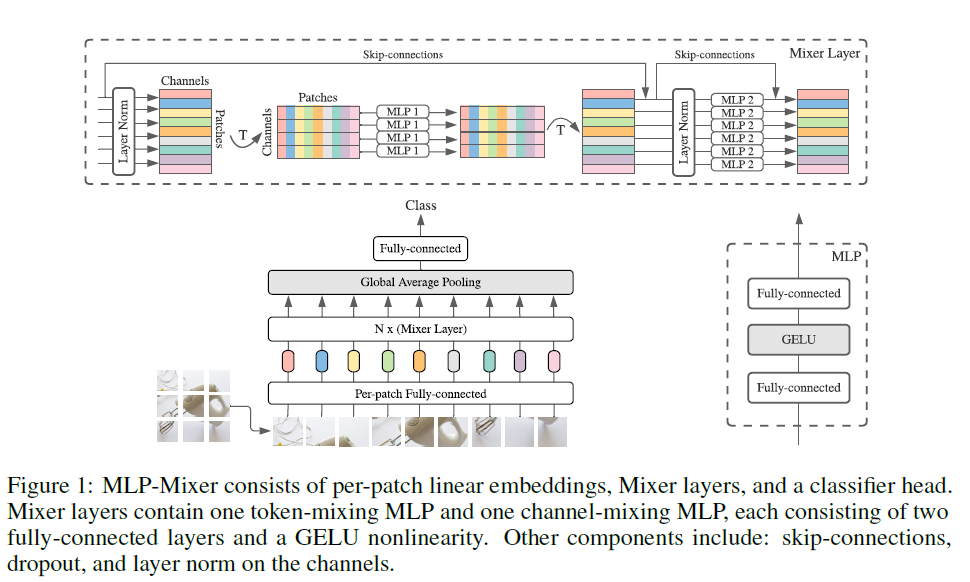 Assuming that a picture is finally divided into 7x7=49 patches, note that the patches here do not overlap each other, which is regarded as a convolution with stride equal to the patch size, and then Per-patch Fully-connected the data in each patch Converted to channel information, and assuming that the number of channels is 512, the MLP1 part is:Token mixing(cross token mixing), I personally feel the same as Depth-wise conv (can be seen as the number of group convolutions in nn.Conv2d = the number of input feature map channels = the number of output feature map channels), and they are all implemented on each channel For the fusion of spatial information, if the previous patch embedding is regarded as local information fusion, then the 7x7 token (feature map) on each channel is regarded as the fusion of global information through MLP.
Assuming that a picture is finally divided into 7x7=49 patches, note that the patches here do not overlap each other, which is regarded as a convolution with stride equal to the patch size, and then Per-patch Fully-connected the data in each patch Converted to channel information, and assuming that the number of channels is 512, the MLP1 part is:Token mixing(cross token mixing), I personally feel the same as Depth-wise conv (can be seen as the number of group convolutions in nn.Conv2d = the number of input feature map channels = the number of output feature map channels), and they are all implemented on each channel For the fusion of spatial information, if the previous patch embedding is regarded as local information fusion, then the 7x7 token (feature map) on each channel is regarded as the fusion of global information through MLP.
Afterchannel mixingIt can be regarded as Point-wise conv (1x1 convolution), which fuses channel information for fixed positions.
Intelligent Recommendation
Thesis reading notes | MLP series-MLP part summary (MLP-MIXER, S2-MLP, AS-MLP, VIP, S2-MLPV2)
If there are mistakes, please point out. This blog is a summary of a summary of the summary of the MLP structure articles. Articles directory 1. MLP-Mixer 2. S2-MLP 3. AS-MLP 4. ViP 5. S2-MLPv2 1. MLP...
MLP-Mixer Pytorch Implementation and Analysis (2)
First of all, the parameters are as follows (enter the picture 3 * 224 * 224): In_Channels: Enter the number of channels, 3. DIM: The number of output channels of the convolution operation is OUT_CHAN...

MLP-Mixer Pytorch Implementation and Analysis (1)
MLP-Mixer Network Structure Analysis:MLP-MIXER: ALL-MLP Architecture for Vision_hzdh blog - CSDN blog Mixer's Pytorch code is difficult to implementMatrix rotation,USUse the REARRANGE implementation m...
Day 3: MLP-Mixer: An all-MLP Architecture for Vision
This article is about the latest multi-level perception machine, the main contribution of the article is as follows The author said domineering: "Although convolutional and attention mechanisms h...
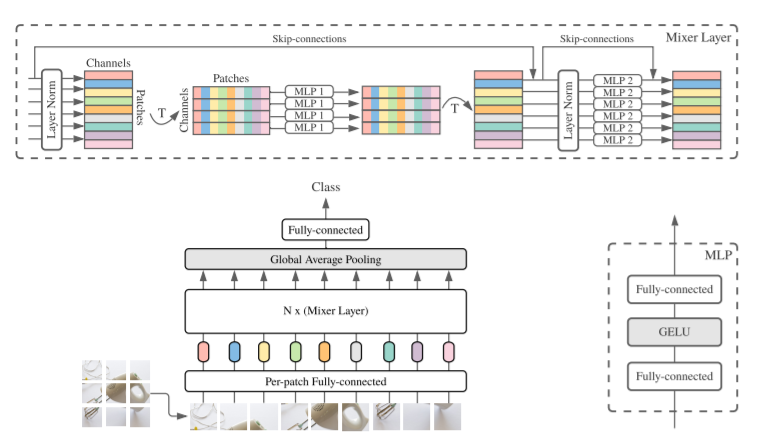
MLP-Mixer: a visual architecture that consists of uniform, no attention, pure mlp
Summary At present, computer visual fields use convolutional neural networks (CNN) and self-focused networks (such as VIT). Recently, Google's research team (formerly VIT team) proposes a visual netwo...
More Recommendation
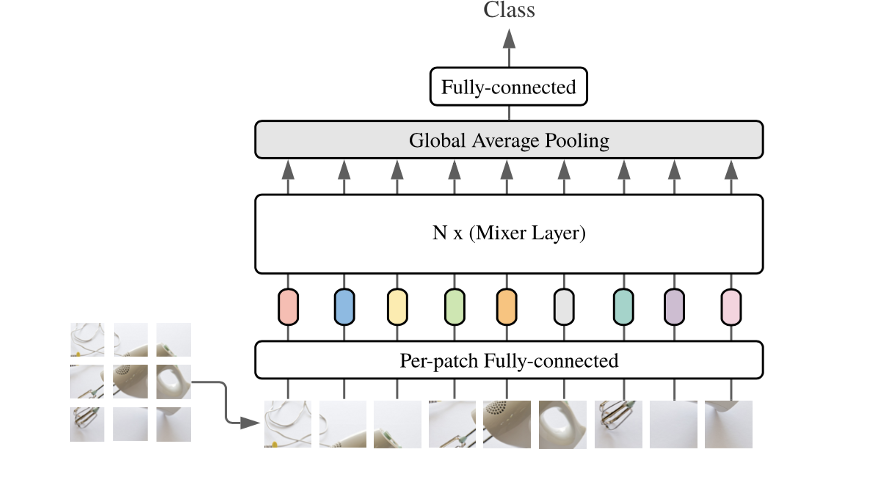
Google MLP-Mixer: All MLP Architecture for Image Processing
Image processing is one of the most interesting sub-areas in machine learning. It starts from multi-layer sensitization, and later, it has been convolved, and later develops the attention mechanism, t...

Document reading (22): mlp-mixer: an all-mlp architecture for vision
Document reading (22): mlp-mixer: an all-mlp architecture for vision Summary 1 Introduction 2 Mixer Architecture 3 Experiments 3.1 Main results 3.2 The role of the model scale 3.3 The role of the pre-...
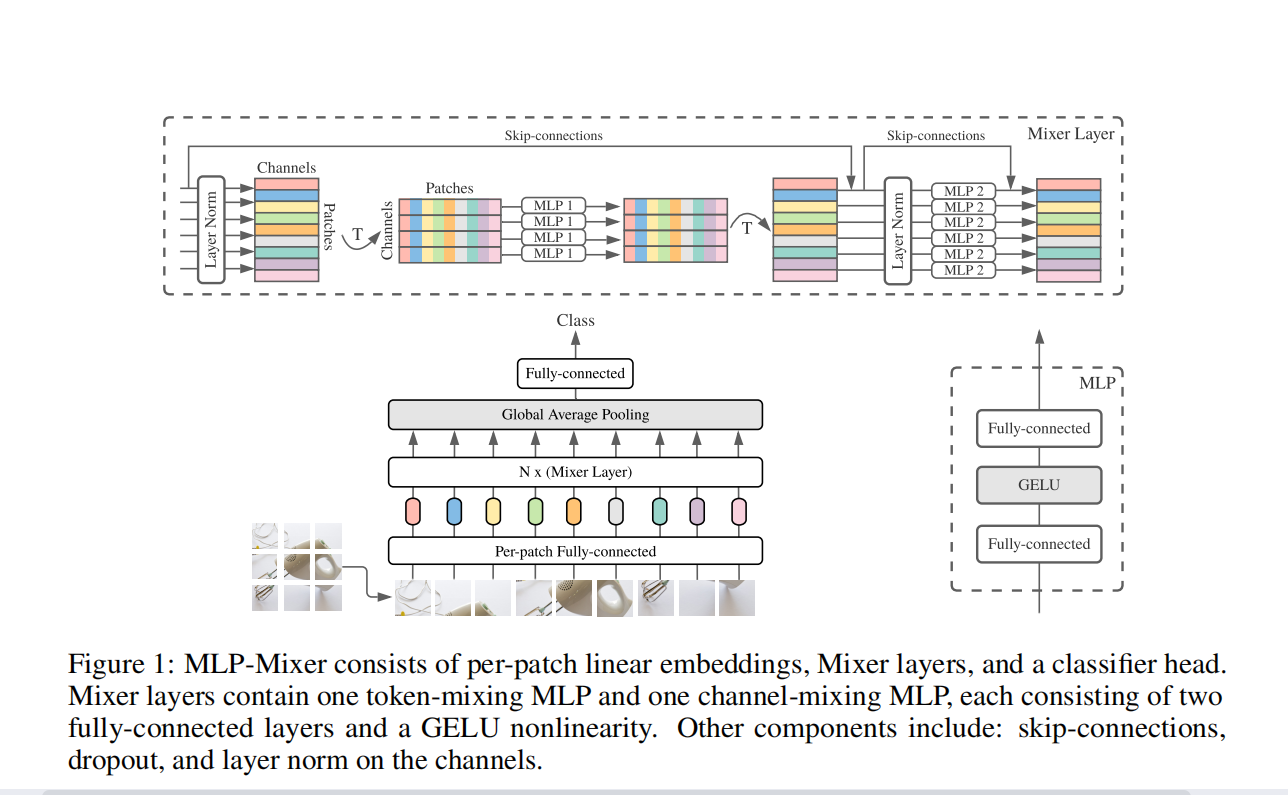
Attached code MLP-MIXER: An All-MLP Architecture for Vision Thesis Interpretation
Mlp-mixer: an all-mlp architecture for vision paper interpretation Reference connection: Summary: In the case of no convolution or self-attention, we proposed MLP-Mixer, a architecture specifically ba...
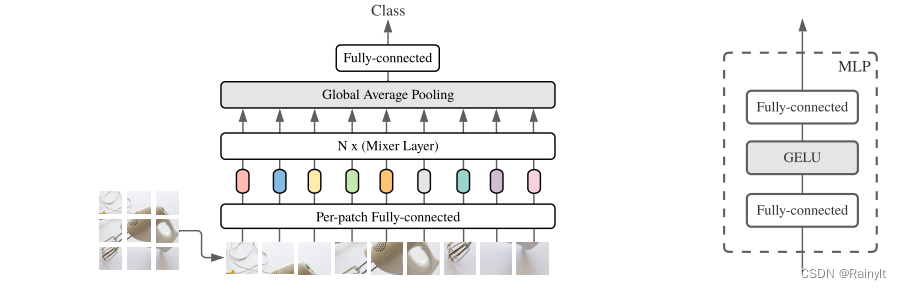
MLP Trilogy (MLP-Mixer -> gMLP -> MAXIM) - Part 1
One: MLP-Mixer Refer to an article to teach you a thorough understanding of Google MLP-Mixer (with code) - Articles of people on the moon - Know https://zhuanlan.zhihu.com/p/372692759 Paper link: http...
PX4 mixer file understanding
PX4 mixer file understanding 1 simple mixer 2 multi-rotor mixer Pure multi-rotor 1 simple mixer Take the fixed-wing mixed file as an example. The file is located. Firmware/ROMFS/px4fmu_common/mixers/f...