《MLP-Mixer: An all-MLP Architecture for Vision》2021
tags: Computer vision Machine learning artificial intelligence
Summary: Convolution Network CNN is a required model in computer vision. Recently, the network structure based on attention mechanisms, such as visual transformer, is increasingly popular. In this article, we will showcase, although the convolutional and attention mechanism is a necessary structure of excellent performance, but they are not required. We propose MLP-Mixer, a structure based only by multi-layer perception (MLPS). MLP-Mixer contains two types of network layers: one is a multi-layer perceived MLPS (such as "mixing" each partial feature applied independently. The other is a multi-layer perceptual machine applied to cross patches (such as "mixed" spatial information). When MLP-Mixer is trained on a large data set, or use the current popular regularization policy, it can obtain competitive scores in the image classification task, under the pre-training and reasoning costs, comparable to the Stoa model. We hope that these results can inspire further research, surpass the convolution established and the TRANSFORM category.
Introduction
The history of computer vision is proved that greater validity of larger data sets (accompanying increased computing capacity) is usually caused by paradigm offset. Although the convolutional neural network CNNS has become the actual standard in the computer visual task, the recent Vision Transformer (VIT), a layer of additional self-focus mechanism, has achieved the highest level of performance. VIT will continue the trend of removing manual visual features and induction offsets from the model, and more step by step is to learn from raw data.
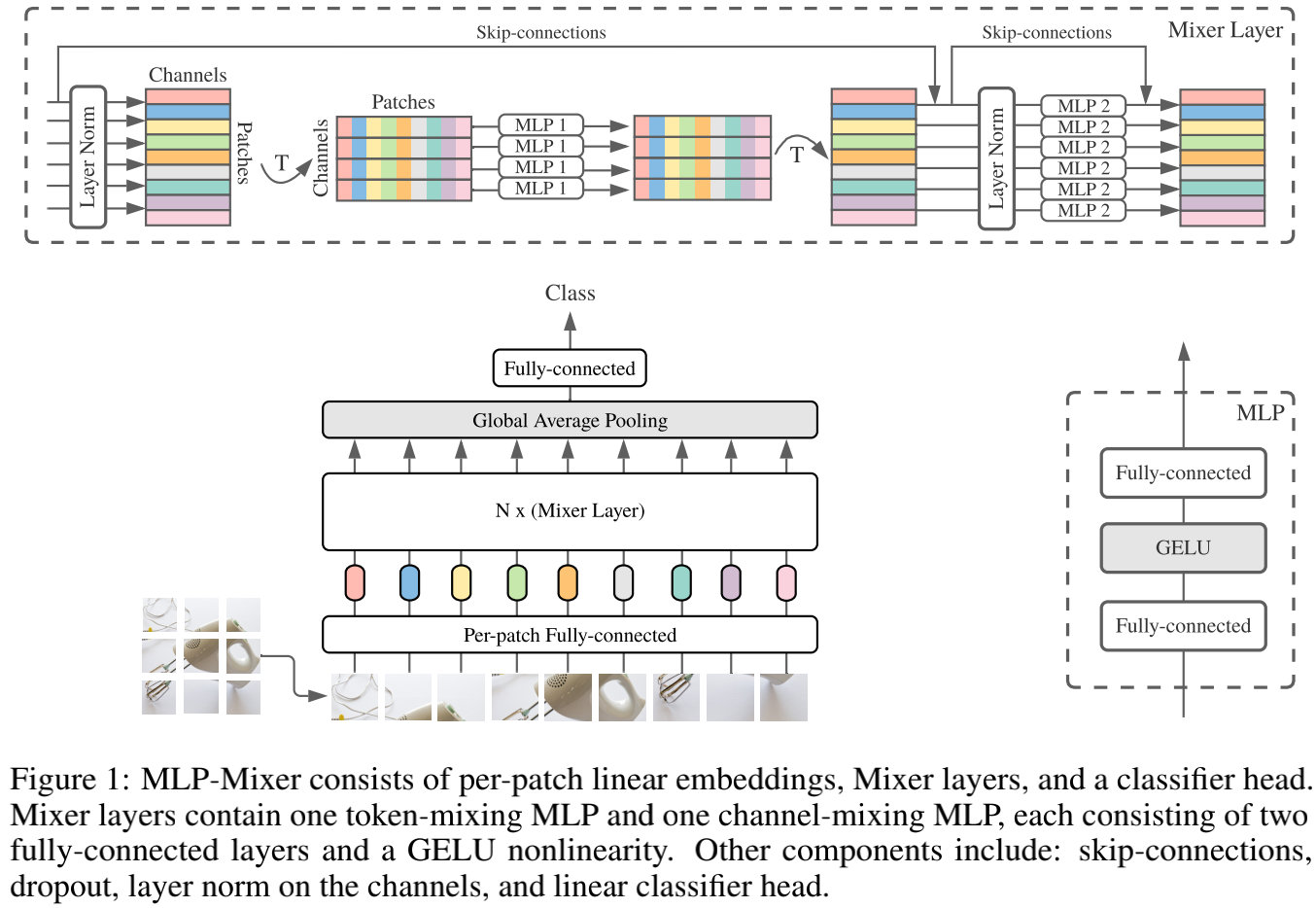
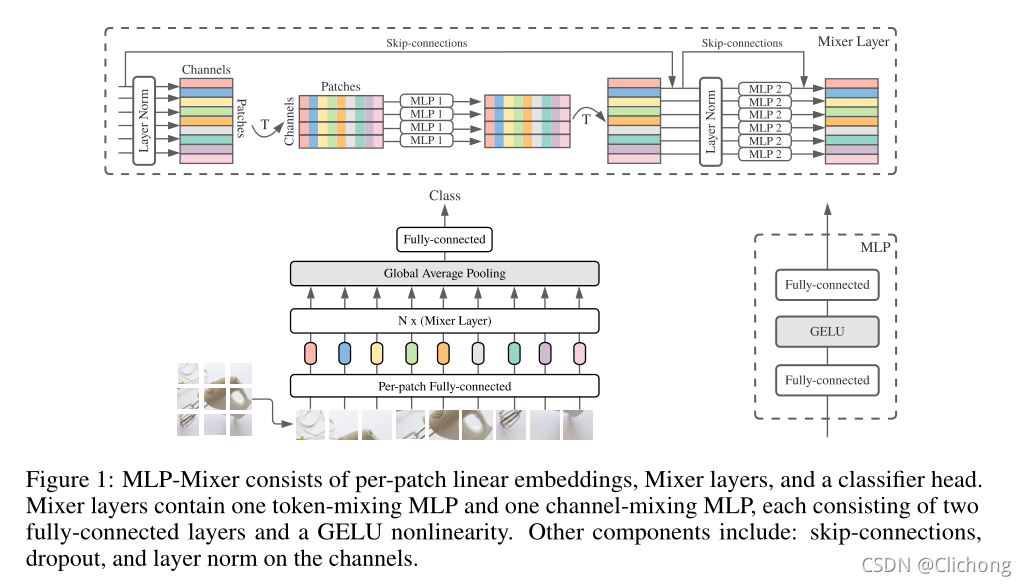
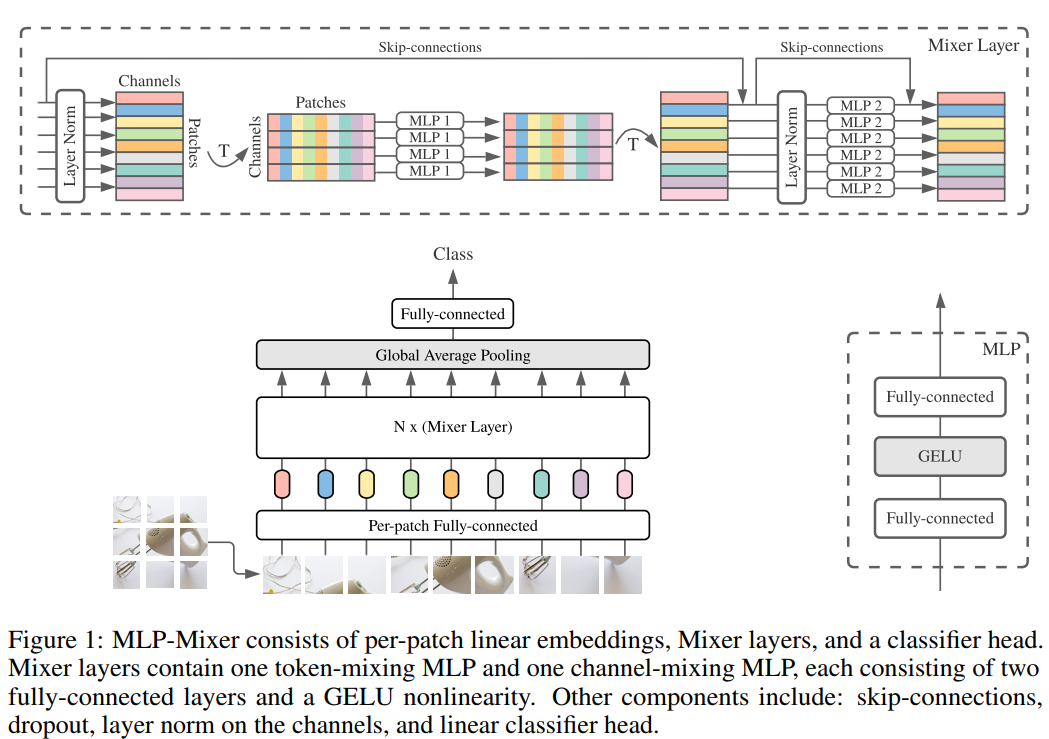
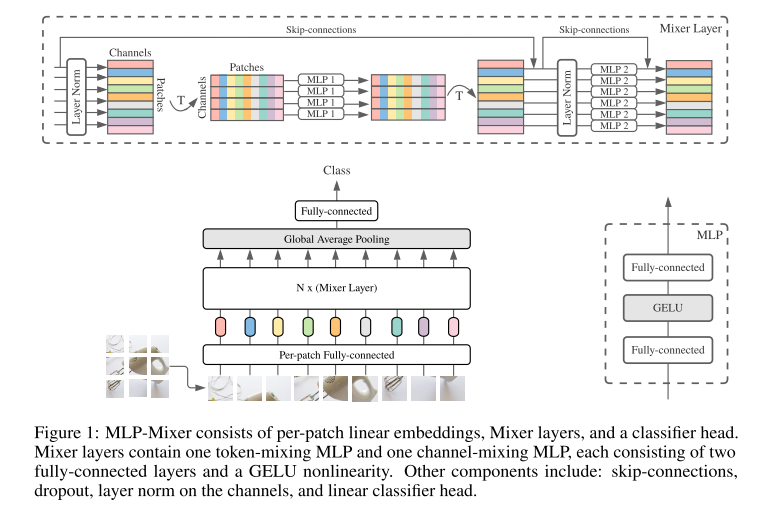
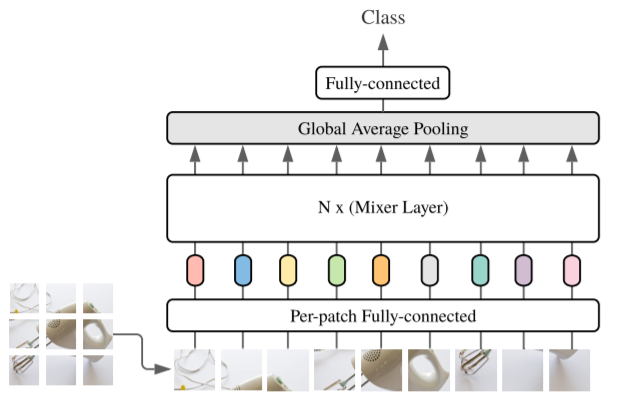
We propose an MLP-Mixer structure, a more competitive alternative but from a relatively simple and technically simpler, which does not use convolutional layers and self-focus layers. In contrast, the Mixer structure is completely based on multi-layer perceived machine structure, which is repeated to spatially or feature channels. Mixer only relies on basic matrix product methods, transform data layout (Reshapes operation and Transposition operation) and scale nonlinearity. Fig1 describes the microstructure of Mixer, which accepts a linear mapping image (also known as tokens) patches, which is converted to a "Patchesxchannel" table as input and maintains this dimension. Mixer uses two types of MLP layers: channel mixing MLPS and marker mixing MLPs. Channel mixing MLPS allows information between different channels to communicate, which actually acts on each TOKEN, using each line in the "Patchesxchannel" table as input. Marking Mix MLPS Allows information between marks of different spatial locations, which act individually on each channel and take each of the above tables as input. These two types of layer interleaved connections make all input dimensions interact.
In extreme cases, our structure can be considered a very special CNN layer that uses a 1x1 convolution to make channel mixing, a single-pass-by-depth convolution and parameter sharing mechanism to make a marking mix. But it is not correct because a typical CNN structure is not a special case of Mixer. Further, a convolution operation is more complex than the MLPS, because it requires additional cost reduction matrix product or specialization.
Although Mixers is very simple, it gains very competitive results. When doing pre-training on big data sets, it gets close to the best model now (those obtained by CNNS and TRANFORMER), with the trade-off of accuracy and calculation cost. This includes the 87.94% of the ILSVRC2012 "ImageNet" competition, 87.94% of TOP-1 verification set accuracy.
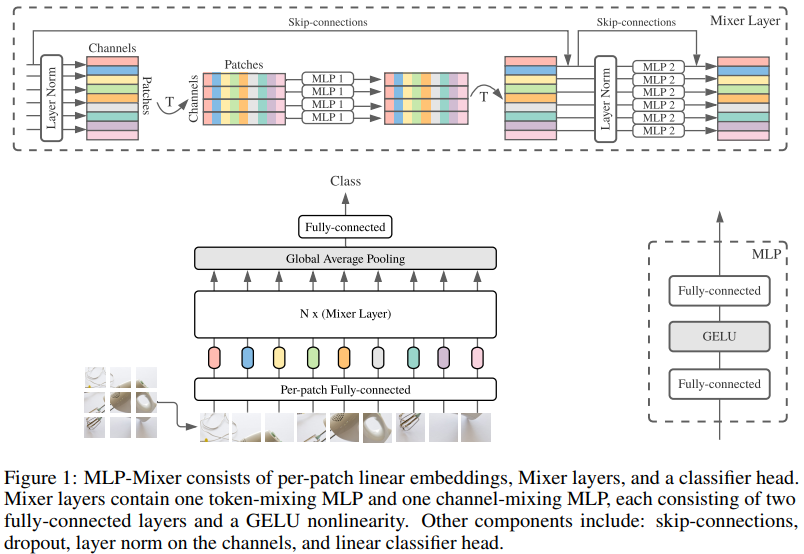
2. Mixer Architecture
The current depth visual structure contains a neural network layer that mixes in (1) a given spatial position mixing feature, (2) mixing features in different spatial positions, or at a time, (1) and (2). In the CNNS structure, (2) is realized by a NXN (for N> 1) convolution layer and the pool layer layer. There is a greater feeling of neurons in a deeper layer. At the same time, the 1x1 convolution layer can also be achieved (1), and the larger core is simultaneously implemented (1) and (2). In visual transformer and other focus-based structures, the self-focus layer simultaneously (1) and (2), MLP implementation (1). The idea behind the Mixer structure is clearly separated (1) and actions token-mixing operations (2). Both operations are implemented in MLPs.
Fig1 summarizes the entire structure. Mixer uses a sequence of S non-hemorphinal PATCH block as an input, each projected to an expected hidden dimension C. This creates a two-dimensional real value input table. . If the resolution of the original input image is (h, w), each PATCH resolution is (P, P), then the number of PATCH blocks is
. If the resolution of the original input image is (h, w), each PATCH resolution is (P, P), then the number of PATCH blocks is . All PATCH is linearly projected by one identical projection matrix. Mixer contains multiple layers having the same size, each with two mlp blocks. The first is to mark the mixed MLP Blocks, which acts on X (for example, it acts on inputting TABLE
. All PATCH is linearly projected by one identical projection matrix. Mixer contains multiple layers having the same size, each with two mlp blocks. The first is to mark the mixed MLP Blocks, which acts on X (for example, it acts on inputting TABLE Columns, mapping
Columns, mapping , Share parameters in all columns. The other is the channel mixed mlp blocks, which acts on X-line, mapping
, Share parameters in all columns. The other is the channel mixed mlp blocks, which acts on X-line, mapping , Which share parameters in all rows. Each MLP Block contains two full-connection layers and a nonlinear layer that is independently applied to each row of Tensor. The Mixer layer can be written as the following formula:
, Which share parameters in all rows. Each MLP Block contains two full-connection layers and a nonlinear layer that is independently applied to each row of Tensor. The Mixer layer can be written as the following formula:


among them It is a nonlinearization (GELU).
It is a nonlinearization (GELU). with
with It is the adjustable width in marking mixing and channel mixing MLPs, respectively. Note
It is the adjustable width in marking mixing and channel mixing MLPs, respectively. Note The selection is independent of the number of input patches. Therefore, the computational complexity of the network is linearly related to the number of input PATCH, unlike a VIT network, its computational complexity is square relationship. becauseIndependent in the size of the input PATCH, all of which compute complexity is linearly related to the number of pixels in the input image, similar to a typical CNN network.
The selection is independent of the number of input patches. Therefore, the computational complexity of the network is linearly related to the number of input PATCH, unlike a VIT network, its computational complexity is square relationship. becauseIndependent in the size of the input PATCH, all of which compute complexity is linearly related to the number of pixels in the input image, similar to a typical CNN network.
As described above, the same channel mixing (marking mix) The MLP structure is applied to each row of input X (each column). The parameters in the binding channel mixed MLP layer are a natural selection - it provides a positional invariance, the infrastructure of a convolution. However, bundled across channel parameters is very rare. For example, the separation convolution applied in some CNN networks, applies the convolution operation to each channel (independent of other channels). However, in separation convolution, different convolution is applied to each channel. This is different from the marking mixed MLPS structure in Mixer, and all channels share the same core (full experience). The parameter bundle blocking structure increases too fast in the case where the hidden dimension C or the sequence length S is increased, resulting in huge memory storage. Surprisingly, this choice does not affect the actual performance of the network.
Each layer (except for the first initial mapping layer) in Mixer is accepted the same size. This isotropic design is very similar to the Transformer structure, or the depth RRN structure in other fields, which also use fixed spans. This is different from CNN networks with pyramid structures: deeper layers have lower resolution but more access to more channels. It is worth noting that although these are classic design structures, other combinations still exist, such as the isotropic resnets and pyramids VITS. In addition to the MLP layer, Mixer uses other standard structural components: Skip-connection and layer normalization. Further, unlike VITS, Mixer does not use location Embedding because the logo mixed MLP layer is sensitive to the order of the input flag, so it is possible to learn how to express location. Finally, Mixer uses a standard classification head structure that is a global average pool layer to pick a linear classifier.
3. Experiment
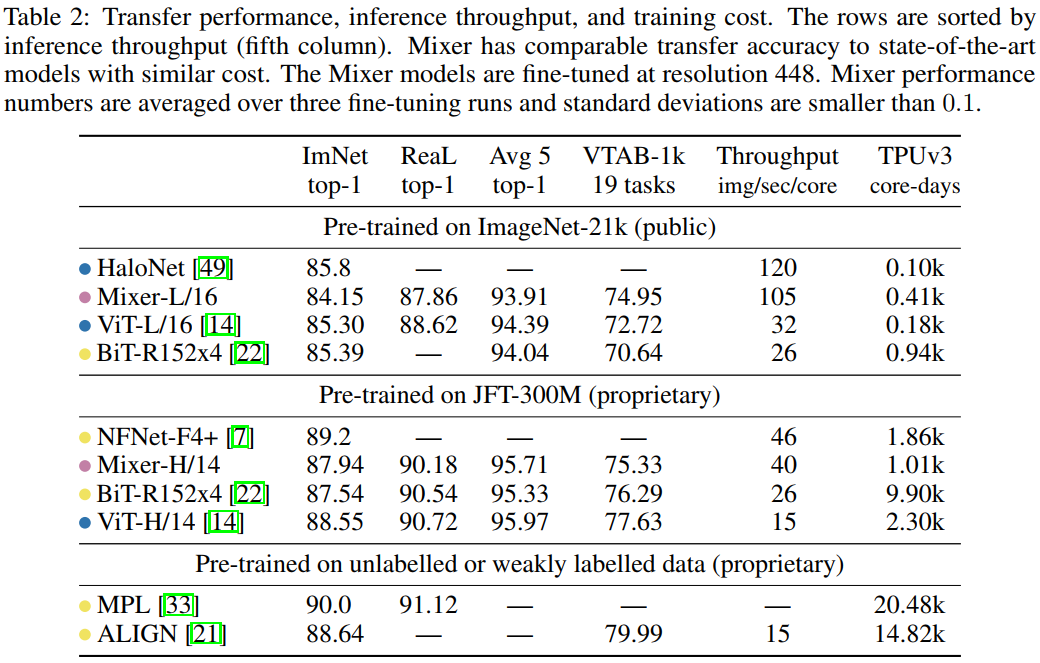
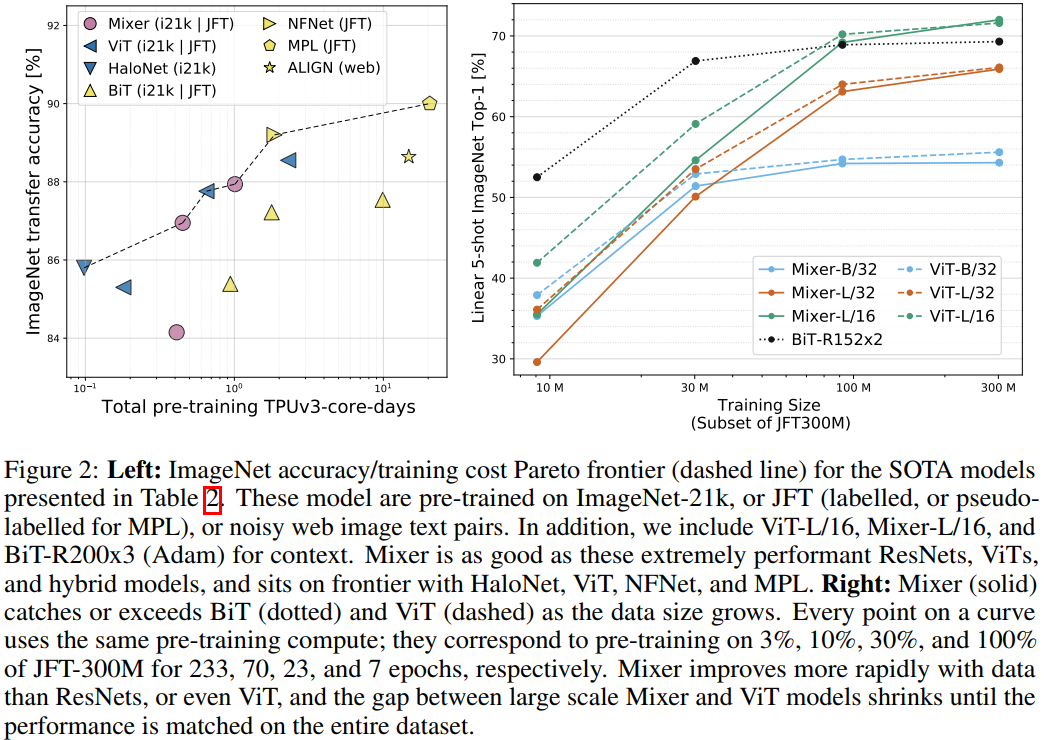

Intelligent Recommendation

MLP-MIXER Detailed
MLP-MIXER Detailed paper《MLP-Mixer: An all-MLP Architecture for Vision》 1 main ideas As a CV framework that the Google VIT team recently raised, MLP-Mixer uses a multi-layer perceived machine (MLP) in...

Personal understanding of MLP-Mixer
main idea: to CHAfter Patch embedding is performed on the image of W, the spatial (global/local) information fusion part and the channel information fusion part are separated. In MLP-Mixer: Assuming t...

Paper reading notes | MLP series - MLP-Mixer
If there is any error, please point it out. paper:MLP-Mixer: An all-MLP Architecture for Vision code:https://github.com/google-research/vision_transformer summary: Researchers show that although both ...
MLP-Mixer: A full mlp network architecture for visual tasks [code implementation (based on mnist)]
This article is based on the MLP-Mixer-Pytorch on Github on GitHub to implement MLP-Mixer Demo on Mnist data. MLP-Mixer: An all-MLP Architecture for Vision[PDF] MLP-Mixer introduction and some ideas [...
Thesis reading notes | MLP series-MLP part summary (MLP-MIXER, S2-MLP, AS-MLP, VIP, S2-MLPV2)
If there are mistakes, please point out. This blog is a summary of a summary of the summary of the MLP structure articles. Articles directory 1. MLP-Mixer 2. S2-MLP 3. AS-MLP 4. ViP 5. S2-MLPv2 1. MLP...
More Recommendation
MLP-Mixer introduction and some ideas
Recently, Google Research's Brain Team also published a heavy article, pure MLP architecture ------MLP-MixerThis team is the original VIT team with strong strength. The authors have been compared with...
MLP-Mixer,External Attention,RepMLP
MLP-Mixer,External Attention,RepMLP Article catalog MLP-Mixer,External Attention,RepMLP MLP-Mixer:An all-MLP Architecture for Vision (Google) Beyond Self-Attention: External Attention Using Two Linear...
MLP-Mixer Introduction and PyToch Code
MLP-Mixer Introduction and PyToch Code Mlp-Mixer Network structure TIPS to sum up reference Mlp-Mixer Paper:MLP-Mixer: An all-MLP Architecture for Vision. Pytorch code:An unofficial implementation of ...
DL-PAPER Entities: MLP-Mixer
MLP-Mixer: An all-MLP Architecture for Vision Paper (Grand Factory is always do not go to the common road, this summary does not follow the past reading mode) Recently, Google has released a papers &q...
MLP
BP neural network: 1, input layer: input data 2, Hidden layer: responsible to increase its computing power; how to solve problems. The more layers, the stronger computing power. 3, output layer: makin...