[Mixer]MLP-Mixer: An all-MLP Architecture forvision
tags: Learn

1. Motivation
In this paper we show that while convolutions and attention are both sufficient for good performance, neither of them are necessary.
2. Contribution
- We propose the MLP-Mixer architecture (or “Mixer” for short), a competitive but conceptually and technically simple alternative, that does not use convolutions or self-attention.
- Mixer’s architecture is based entirely on multi-layer perceptrons (MLPs) that are repeatedly applied across either spatial locations or feature channels.
- Mixer relies only on basic matrix multiplication routines, changes to data layout (reshapes and transpositions), and scalar non-linearities.
3. Mixer Architecture
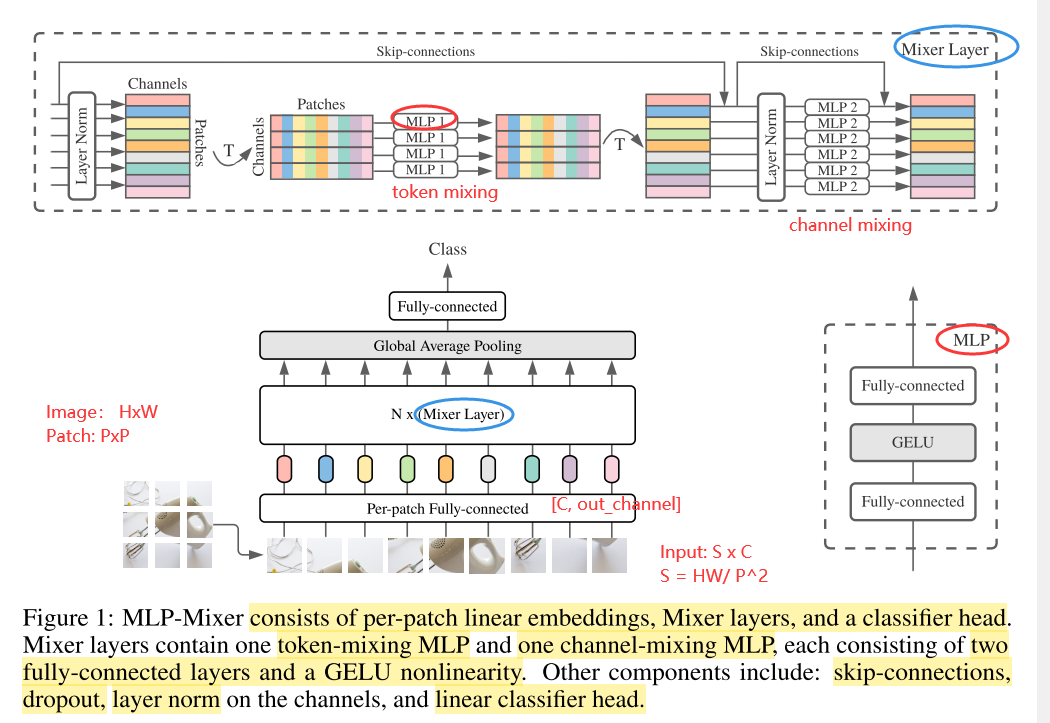
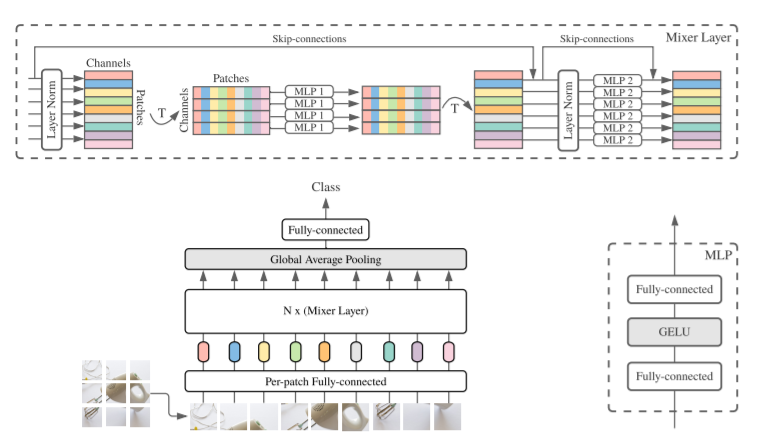
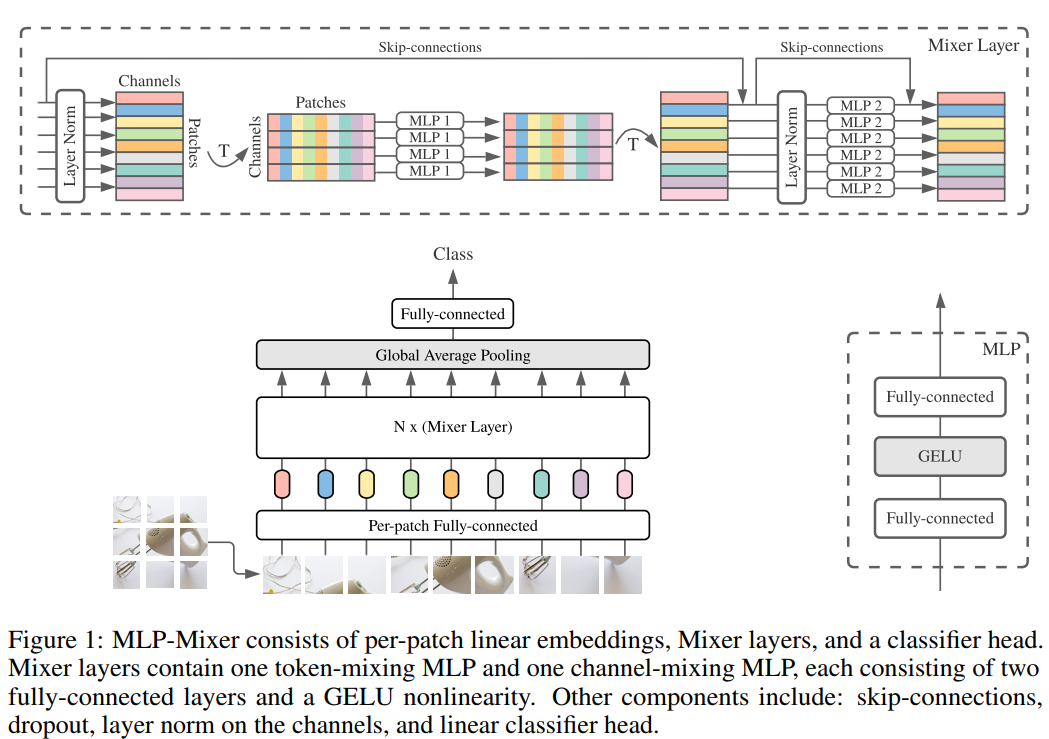
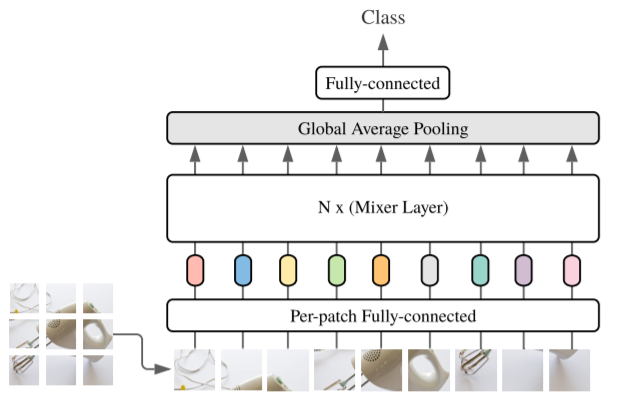
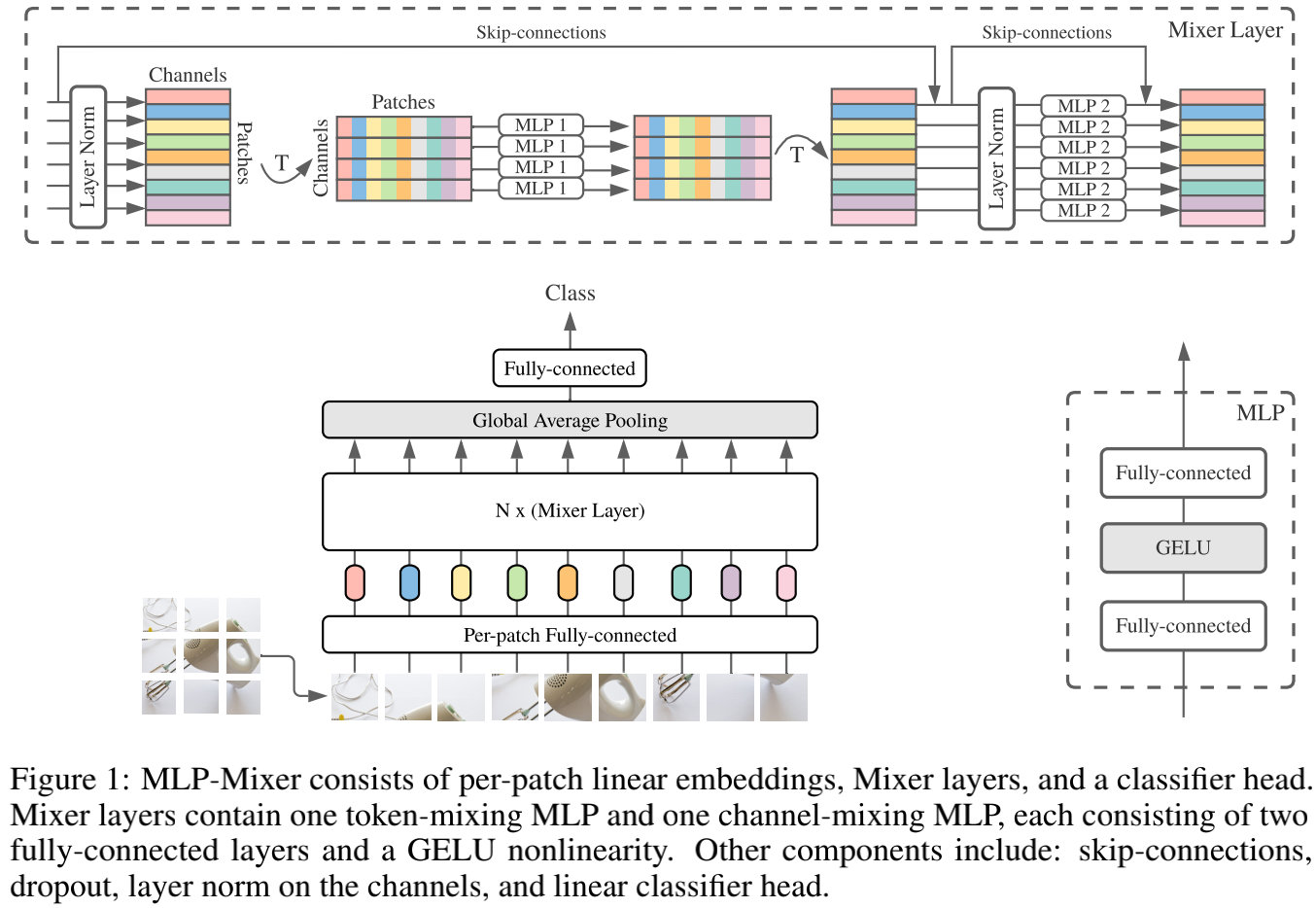
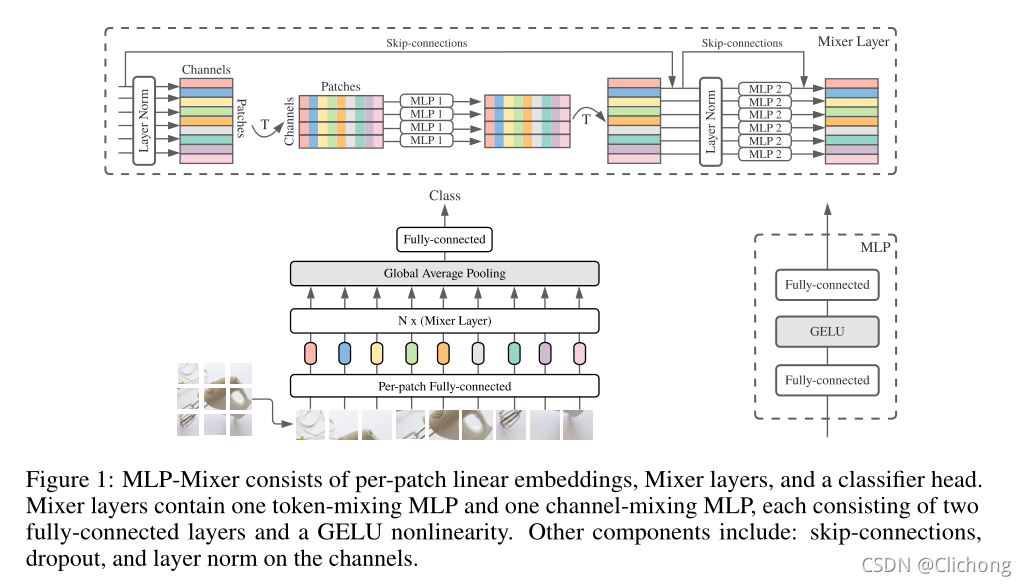
As shown in Figure 1, for mlp-mixer macroscopic structures, MLP-Mixer consists of PER-Patch Linear Embedding, Mixer Layers, and Classifier HEAD. For Mixer Layer, it consists of Token-Mixing MLP and the Channel-Mixing MLP, each MLP consists of two FC layers and a GELU nonlinear activation layer. The remaining ingredients include Skip-Connection, Dropout, Layer Norm, Linear Classifier HEAD.
There are two ways to mix the characteristics:
1 At a Given Spatial Location, in a specific spatial location
2 Between Different Spatial Locations in different spatial locations
In CNN, the NXN convolutionary nuclear and poolization operation can be completed 2, 1x1 volume nucleus can be completed 1, larger kernels1 and 2 can be Perform; in the VIT, Self-Attention can be completed 1, MLP-blocks can be completed 2.
These IDEAs are separated by per-location (Channel-Mixing) and CROSS-Location.
The input of mlp-mixer layer is a sequence of linearly projected image patches (also known as tokens), and the input dimension is Pathches X Channel.
Chennel-Mixing MLPS and token-Mixing works as follows:
The channel-mixing MLPs allow communication between different channels; they operate on each token independently and take individual rows of the table as inputs.
The token-mixing MLPs allow communication between different spatial locations (tokens); they operate on each channel independently and take individual columns of the table as inputs. These
Specifically, the input taken by Mixer is the s image patches, each Patch's dimension is C, which is two-dimensional Real-Value Input Table, X ∈ R ( S × C ) X \in R^{(S \times C)} X∈R(S×C)If the original image is distinguished H × W H \times W H×W, Each Patch resolution is P × P P \times P P×PThen, the number of patches is S = H W / P 2 S= HW/P^2 S=HW/P2。
For Mixer Layer has N layers, each layer has 2 MLP Blocks, the first is token-mlp block, which is the column of X, which is understood as a transposition. X T X^T XT, maps R S → R S R^S \rightarrow R^S RS→RSThe second is a line vector of the Channel-Mixing Mlp Block, and the input is X. Maps R C → R C R^C \rightarrow R^C RC→RC。
The 2 MLP Blocks formula is as follows:
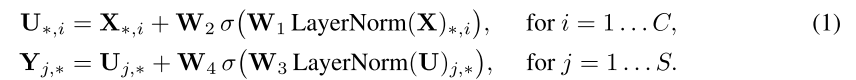
From the formula, you can draw σ \sigma σIt is the subscript from 1 to 4 from 1 to 4, because there are 2 linear in the MLP layer. U indicates that token mixing, y is Channel Mixing. It should be noted that the LN layer is for u. It is regularization for Per s x 1, which is the value of all Channel on the same location; the U's LN layer is optimized for Per Sx1, That is, the value of all local locations on the same Channel.
1. Input:
H X W = 100 x 100
P X P = 10 x 10
S = HW/P^2 = 100
C = P x P x 3 = 10 x 10 x 3
input: 100 x (10 x 10 x 3)
2. per-patch fully-connected:
linear(10x10x3, output_channel)
3. Mixer Layer
LN
linear1
GELU
linear2
4. Linear Classifier Head(Fully-Connected)
[in_channel, classes]
The author believes that Channel-Mixing MLPS is very normal Choice, providing CNNS important location invariance.
Tying the parameters of the channel-mixing MLPs (within each layer) is a natural choice—it provides positional invariance, a prominent feature of convolutions.
However, the binding parameters for Across Channel are uncommon (that is, token Mixing MLPs). Unlike the previous separation convolution, the Token Mixing MLPS is a global feeling, which is the same for all Channels sharing the same kernel (because of the FC, there is a matrix multiplication of [in_chanel, out_channel] for each Patch).
However, tying parameters across channels is much less common.
Advantages of Parameter Tying:
The parameter tying prevents the architecture from growing too fast when increasing the hidden dimension C or the sequence length S and leads to significant memory savings.
Each layer in Mixer (except for the initial patch projection layer) takes an input of the same size. This
Mixer no location coding
Furthermore, unlike ViTs, Mixer does not use position embeddings because the token-mixing MLPs are sensitive to the order of the input tokens, and therefore may learn to represent location.
Intelligent Recommendation

Personal understanding of MLP-Mixer
main idea: to CHAfter Patch embedding is performed on the image of W, the spatial (global/local) information fusion part and the channel information fusion part are separated. In MLP-Mixer: Assuming t...
MLP-Mixer: a visual architecture that consists of uniform, no attention, pure mlp
Summary At present, computer visual fields use convolutional neural networks (CNN) and self-focused networks (such as VIT). Recently, Google's research team (formerly VIT team) proposes a visual netwo...

Paper reading notes | MLP series - MLP-Mixer
If there is any error, please point it out. paper:MLP-Mixer: An all-MLP Architecture for Vision code:https://github.com/google-research/vision_transformer summary: Researchers show that although both ...
MLP-Mixer introduction and some ideas
Recently, Google Research's Brain Team also published a heavy article, pure MLP architecture ------MLP-MixerThis team is the original VIT team with strong strength. The authors have been compared with...
MLP-Mixer,External Attention,RepMLP
MLP-Mixer,External Attention,RepMLP Article catalog MLP-Mixer,External Attention,RepMLP MLP-Mixer:An all-MLP Architecture for Vision (Google) Beyond Self-Attention: External Attention Using Two Linear...
More Recommendation
MLP-Mixer Introduction and PyToch Code
MLP-Mixer Introduction and PyToch Code Mlp-Mixer Network structure TIPS to sum up reference Mlp-Mixer Paper:MLP-Mixer: An all-MLP Architecture for Vision. Pytorch code:An unofficial implementation of ...
DL-PAPER Entities: MLP-Mixer
MLP-Mixer: An all-MLP Architecture for Vision Paper (Grand Factory is always do not go to the common road, this summary does not follow the past reading mode) Recently, Google has released a papers &q...
MLP-Mixer: A full mlp network architecture for visual tasks [code implementation (based on mnist)]
This article is based on the MLP-Mixer-Pytorch on Github on GitHub to implement MLP-Mixer Demo on Mnist data. MLP-Mixer: An all-MLP Architecture for Vision[PDF] MLP-Mixer introduction and some ideas [...
Thesis reading notes | MLP series-MLP part summary (MLP-MIXER, S2-MLP, AS-MLP, VIP, S2-MLPV2)
If there are mistakes, please point out. This blog is a summary of a summary of the summary of the MLP structure articles. Articles directory 1. MLP-Mixer 2. S2-MLP 3. AS-MLP 4. ViP 5. S2-MLPv2 1. MLP...
MLP-Mixer Pytorch Implementation and Analysis (2)
First of all, the parameters are as follows (enter the picture 3 * 224 * 224): In_Channels: Enter the number of channels, 3. DIM: The number of output channels of the convolution operation is OUT_CHAN...