MLP-Mixer: a visual architecture that consists of uniform, no attention, pure mlp
Summary
At present, computer visual fields use convolutional neural networks (CNN) and self-focused networks (such as VIT). Recently, Google's research team (formerly VIT team) proposes a visual network architecture that discards a volume and self-focused and completely using multi-layer perception machine (MLP), which is very simple in design and implemented on the ImageNet data set. It is comparable to the performance performance of CNN and VIT.
Paper address:MLP-Mixer: An all-MLP Architecture for Vision
Article structure
The first part introduces the macro structure of MLP-Mixer, introduced it.
Two types of MLP layers adopted by Mixer.
The second part introduces the detailed structure and principle of Mixer.
The third part introduces the experiment and experimental results used.
method
MLP-Mixer is a new architecture that is distinguished from CNN and Transformer, which does not need convolution and self-focus. In contrast, MLP-Mixer only depends on multiple-layer perceptions implemented on a null area or feature channel; Mixer relies only to base matrix operation, data discharge transform (such as Reshape, TransPosition), and nonlinear layers.
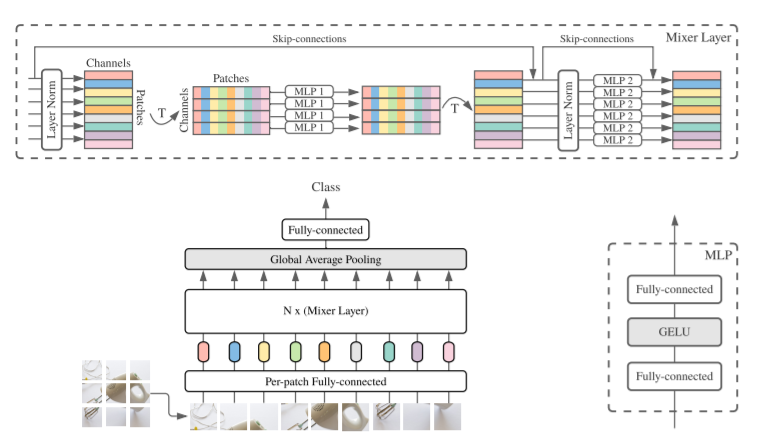
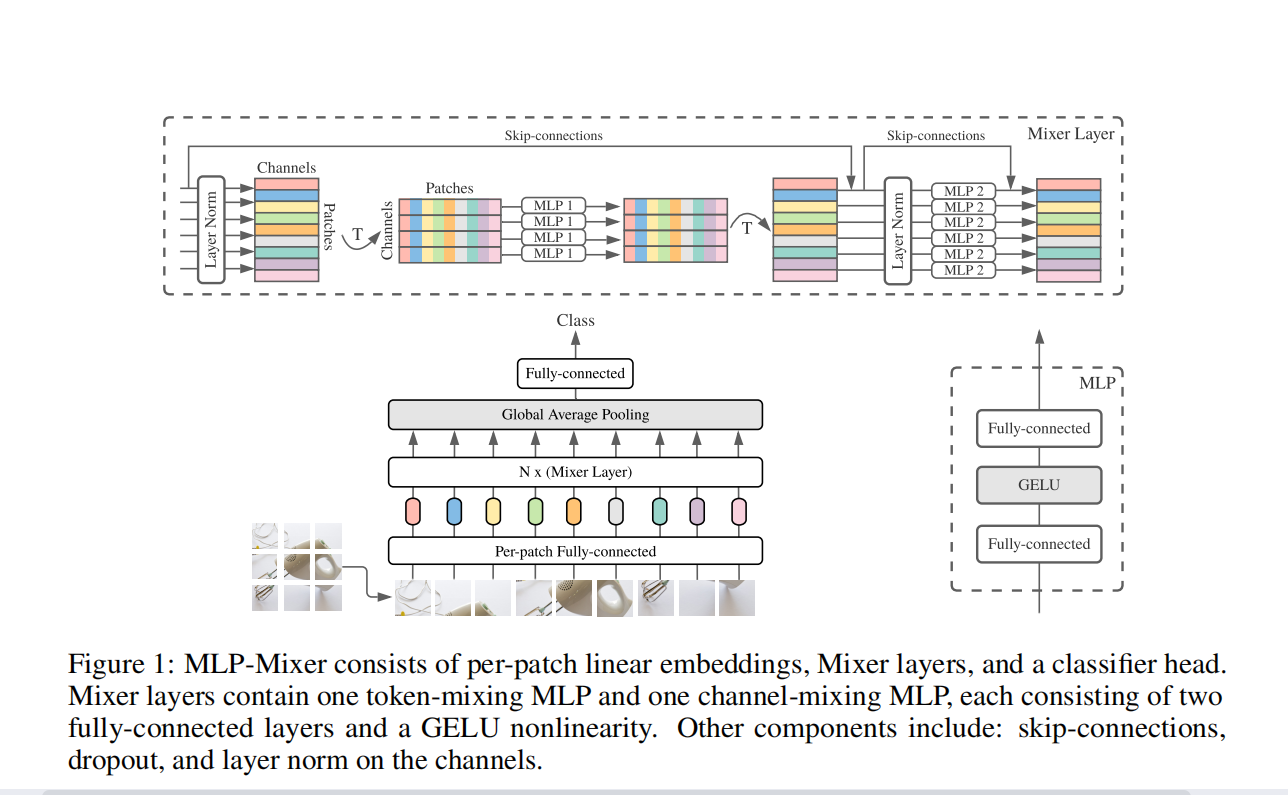
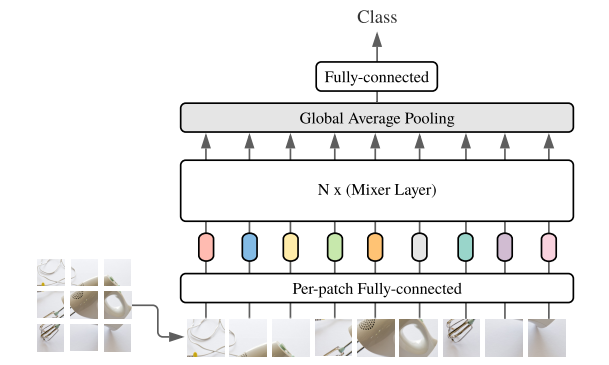
Figure 1 Macro-constructed diagram of Mixer
The general structure of Mixer is shown in Figure 1.
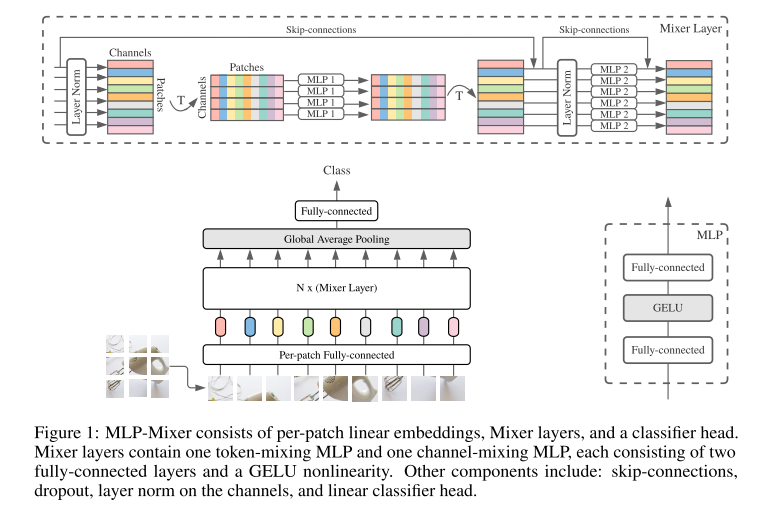
It is input as a linear projection of a series of image blocks (its shape is patches x channels). Mixer uses two types of MLP layers (Note: These two types of layers alternately perform information interaction between two dimensions):
- Channel-MixingMLP: For different channels, each Token is independently handled, that is, each line is used as input.
- Token-MixingMLP: Used for different space domain location communication, each channel legend processing, that is, each column is used as input.
In extreme cases, the MLP-Mixer architecture can be regarded as a special CNN that uses a 1 × 1 channel mixed convolution, a single-channel depth convolution of the full substance domain, and a token mixed parameter sharing.
Mixer mixer architecture
Generally speaking, the deep visual architecture today uses three ways of feature mixing:
(I) at a given spatial position;
(Ii) Different spatial positions;
(Iii) combining the above two methods.
In CNNS, (ii) is a convolution and cellularization using N × N, where n> 1; (i) is 1 × 1 convolution; larger verification, (i) and (ii). Usually a deeper level of neurons have a bigger feeling.
In Transformer and other focus architectures, the self-focus layer allows simultaneous execution (i) and (ii), while MLP only (i). The mind behind the Mixer architecture is to achieve significant separation of each channel mixing operation (I) and TokeN mixed operation (II) via MLP.
In the figure 1 architecture, Mixer uses a non-overlapping image block of the sequence length as input, each image block projection to the desired hidden dimension C, and generates a two-dimensional real value input x ∈ RS × C . If the resolution of the original image is (H x W), the resolution of each image block is (P x P), then the number of image blocks is S = HW / P2. All blocks use the same projection matrix for linear projection.
Mixer consists of a multilayer of equal size, with two MLP blocks per layer. The first is the Token Mixing MLP block: it acts on the X column, mapping from RS to R s, can be shared in all columns. The second is the Channel-Mixing MLP block: it acts on the line X, mapping from the RC to R C, can be shared in all rows. Each MLP block contains two full-connection layers and a nonlinear layer independent of the input. Its basic equation, such as Figure 2:
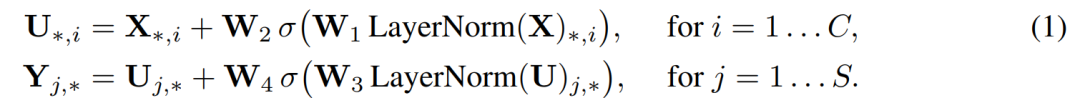
figure 2
DS DC represents the hidden width of Token-Mixing and Channel-Mixing MLP, respectively. Since the selection of the DS is independent of the number of input image blocks, the computational complexity of the network is linear with the number of input blocks; in addition, DC is independent of block size, the overall calculation amount is linear with the image of the image, which is similar CNN.
The same channel hybrid MLP (or token mixed MLP) is applied to each row and column of X, and the parameters of the binding channel mixed MLP in each layer are natural selection, which provides positional invariance, this is a volume A significant feature of the accumulation.
However, the situation across channel binding parameters is not common in CNN. For example, it can be separated in the CNN to separate different convolutionary nucleus to each channel. The Token Mix MLP in Mixer can share the same core (i.e., fully experienced wild). THE INVENTION, when the hidden layer C or sequence length S is increased, this parameter binding can avoid excessive growth of the architecture and save memory. But this binding mechanism has no effect on performance.
Each layer in Mixer (except for the initial block projection layer) receives the same size input. This "allogeneity" design is most similar to using the fixed width Transformer and RNN. This is different from most CNN, CNN has a pyramid structure: the deeper layer has a lower resolution, more channels.
In addition, different from VITS, Mixer does not use location embedding, because the Token hybrid MLP is sensitive to the order of input token, so you can learn the location. Finally, Mixer uses a standard classification HEAD and a linear classifier.
experiment
It is mainly to analyze three issues:
- Accuracy on the downstream task
- Total pre-training calculation amount, which is very important for training models from scratch on the upstream data.
- In reasoning, this is very important for practical applications
The purpose of the article is not to reach the SOTA results, which is indicated that the simple MLP model can obtain comparable performance with the current best CNN, the attention model.
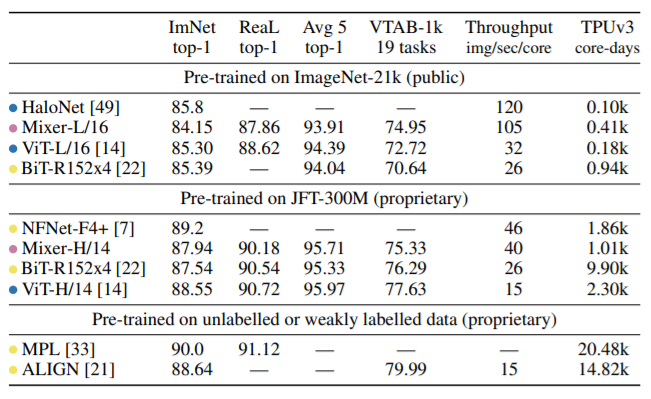
image 3
Figure 3 shows the maximum MIXER model and the SOTA model in ImageNet, the performance of the REAL data set, can be seen from it:
- When ImagingNet-21k + additional regular technology is pre-training, Mixer has achieved very strong performance in the ImageNet data set: 84.15% TOP1, which is slightly smaller than other models. At this point, similar to VIT, the regular technology is necessary to help Mixer avoid the fit.
- When upgrading the upstream data set size, Mixer performance can be further improved. Specifically, Mixer-H / 14 achieved 87.94% TOP1 precision, 0.5% higher than Bit-Resnet152x4, 0.5% lower than Vit-H / 14. It is worth mentioning that Mixer-H / 14's reasoning speed is 2.5 times faster than Vit-H / 14, which is 2 times faster than Bit.
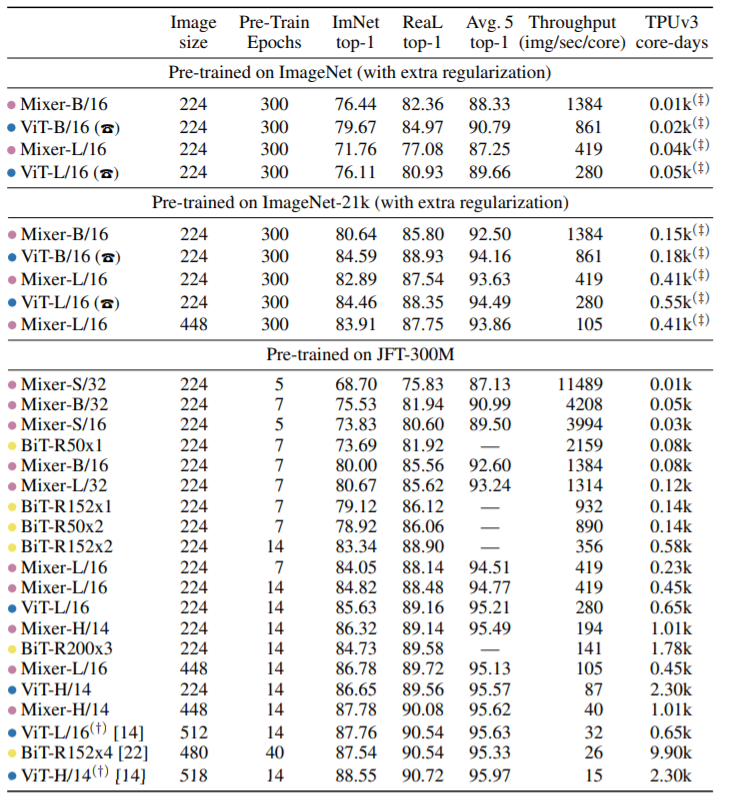
Figure 4
Figure 4 is compared with different model sizes, and the performance comparison of models when inputting different resolution inputs can be seen from it:
- When training from the headnet, Mixer-B / 16 has achieved a relatively reasonable accuracy: 76.44%. This is 3% lower than the VIT-B / 16. That is, when training is started from the headnet, Mixer-B / 16 has a fit problem.
- With the high training data, Mixer's performance is steadily improved. It is worth mentioning that JFT-300M data pre-training, 224-sized fine-tuning Mixer-H / 14 achieved 86.32% accuracy, only 0.3% weaker than VIT-H / 14, but the reason is 2.2 times fast.
Intelligent Recommendation
Attached code MLP-MIXER: An All-MLP Architecture for Vision Thesis Interpretation
Mlp-mixer: an all-mlp architecture for vision paper interpretation Reference connection: Summary: In the case of no convolution or self-attention, we proposed MLP-Mixer, a architecture specifically ba...

MLP-MIXER Detailed
MLP-MIXER Detailed paper《MLP-Mixer: An all-MLP Architecture for Vision》 1 main ideas As a CV framework that the Google VIT team recently raised, MLP-Mixer uses a multi-layer perceived machine (MLP) in...

Personal understanding of MLP-Mixer
main idea: to CHAfter Patch embedding is performed on the image of W, the spatial (global/local) information fusion part and the channel information fusion part are separated. In MLP-Mixer: Assuming t...

Paper reading notes | MLP series - MLP-Mixer
If there is any error, please point it out. paper:MLP-Mixer: An all-MLP Architecture for Vision code:https://github.com/google-research/vision_transformer summary: Researchers show that although both ...
[Visual Transformer] Ultra-detailed interpretation of the MLP-MIXER model
MLP-Mixer paper:https://arxiv.org/abs/2105.01601 Talk about mlp-mixer Hi Guy! We have met again. Here we will analyze a job from Google MLP-MIXER Before talking about MLP-Mixer, let's first understand...
More Recommendation
5 minutes to learn simple structure | mlp-mixer: an all-mlp architecture for vision | CVPR2021
The article is transferred from: WeChat public account "machine learning refining" Author: alchemy (welcome to exchange, common progress) Contact: WeChat cyx645016617 Paper Name: "MLP-M...
Paper Reading 2: A brief summary MLP-Mixer: An all-MLP Architecture for Vision
Summarize The authors propose MLP-Mixer for image classification tasks, based only on multi-layer perceptrons (MLP). MLP-Mixer has achieved competitive results in popular benchmarks, with pre-training...
Thesis reading notes | MLP series-MLP part summary (MLP-MIXER, S2-MLP, AS-MLP, VIP, S2-MLPV2)
If there are mistakes, please point out. This blog is a summary of a summary of the summary of the MLP structure articles. Articles directory 1. MLP-Mixer 2. S2-MLP 3. AS-MLP 4. ViP 5. S2-MLPv2 1. MLP...
MLP-Mixer introduction and some ideas
Recently, Google Research's Brain Team also published a heavy article, pure MLP architecture ------MLP-MixerThis team is the original VIT team with strong strength. The authors have been compared with...
MLP-Mixer Introduction and PyToch Code
MLP-Mixer Introduction and PyToch Code Mlp-Mixer Network structure TIPS to sum up reference Mlp-Mixer Paper:MLP-Mixer: An all-MLP Architecture for Vision. Pytorch code:An unofficial implementation of ...