Google MLP-Mixer: All MLP Architecture for Image Processing
tags: Depth study artificial intelligence Machine learning Neural Networks Computer vision
Image processing is one of the most interesting sub-areas in machine learning. It starts from multi-layer sensitization, and later, it has been convolved, and later develops the attention mechanism, then TRANSFORMERS, now the new papers will also bring back to MLP. If you are like me, your first question will be MLP how to get almost the same result as Transformers and CNN? This is the question we will answer in this article. Google's new "MLP-Mixer" has achieved very close to the SOTA model, which is trained in a large amount of data, and the speed is almost three times. This is also an interesting indicator (image / core / second) in the paper.
MLP-Mixer does not need to use any convolution or any self-payment layer, but almost can achieve SOTA results, which is very deep.
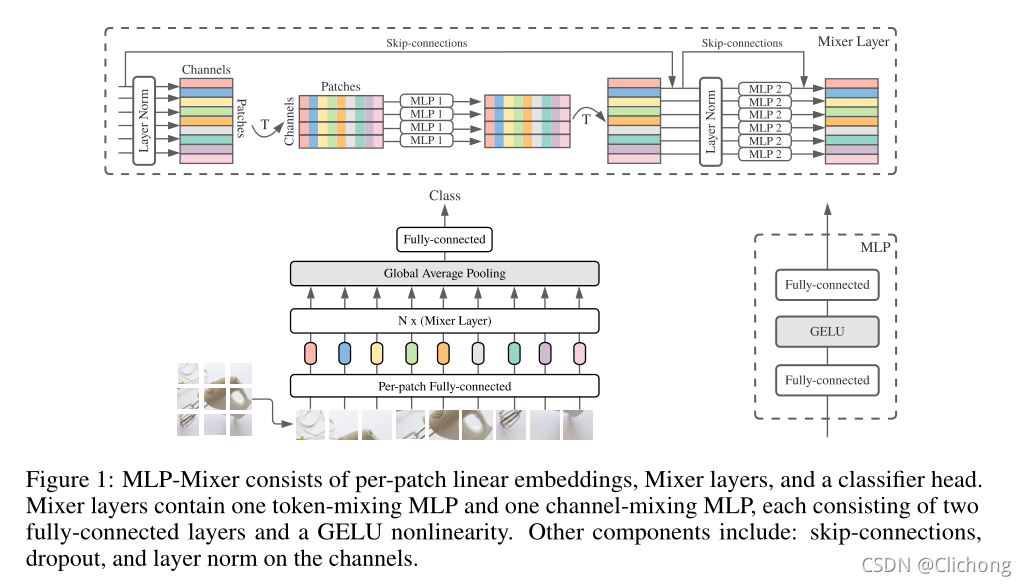
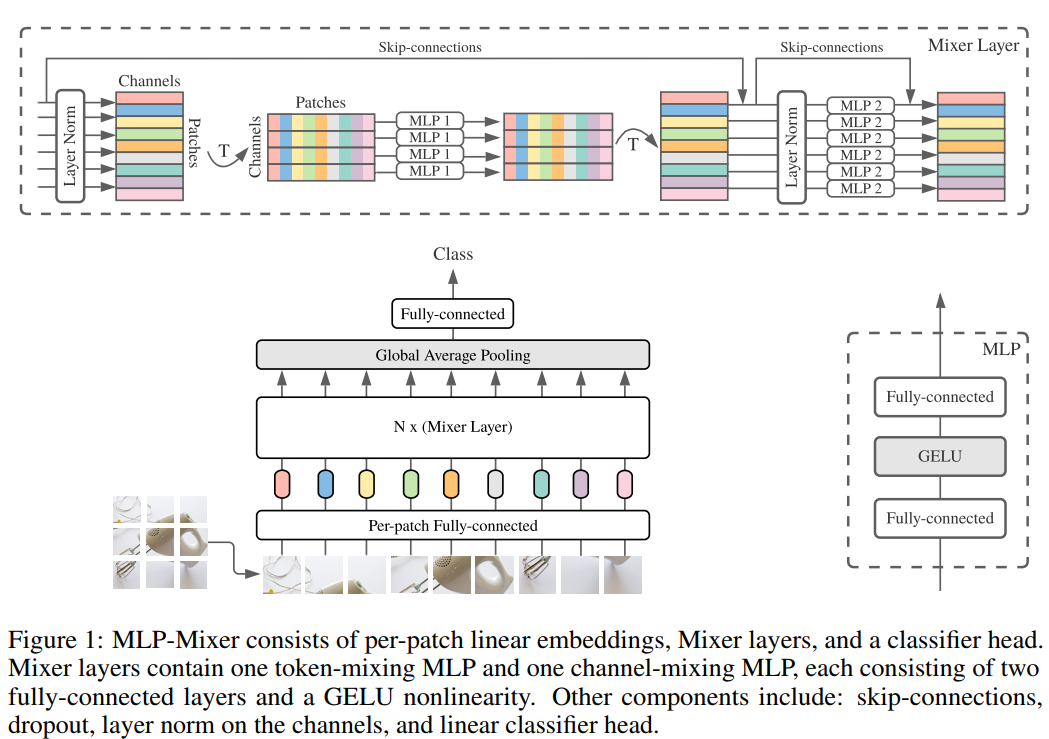
MLP-MIXER architecture
Let us first discuss each component of the network before discussing how the network works, and then combines them together.
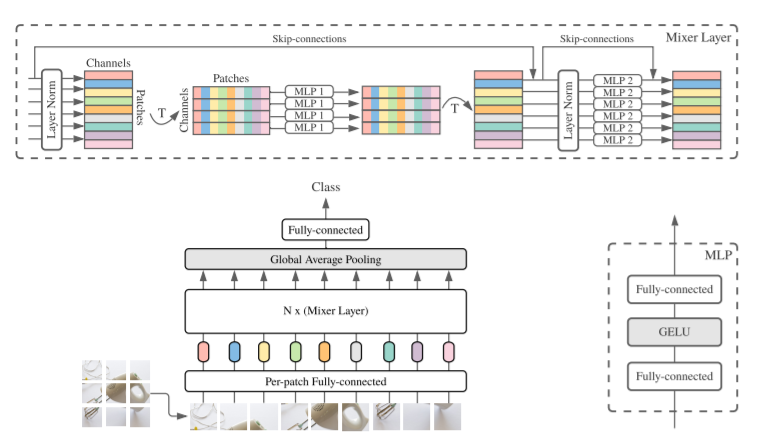
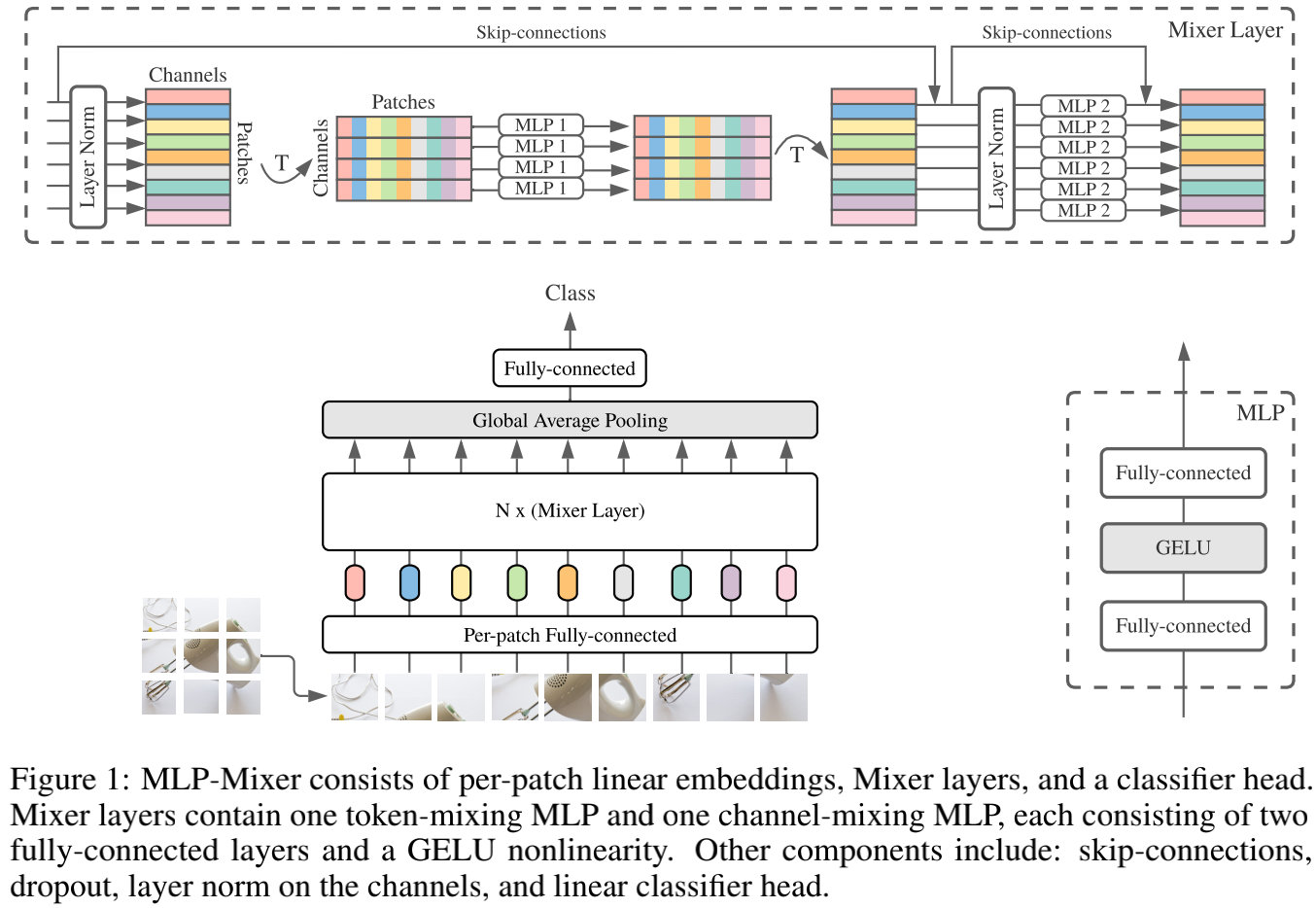
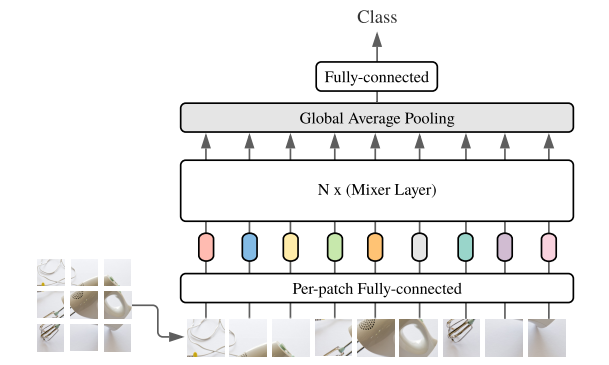
We propose MLP-Mixer, a architecture that is specifically based on multi-layer perception (MLPs). MLP-Mixer contains two types of layers: one is MLPS independently of imagepatches(I.e.: Mix each partial feature), the other is MLPS for cross-patches (i.e., mixed space information).
The first thing to note here is how to "model / represent" in the input image, which is modeled as Patches (when it is split) X channel. The first type of layer (referred to as a channel mixing layer [1]), operates on the stand-side surface of the image, and communicates between the channels during the learning period (thus referred to as a channel mixing). The second type (which is referred to as PATCHES is mixed) works in the same manner, but for PATCHES (allowing communication between different patches).
The core idea of modern image processing networks is to mix characteristics between a given position or mix between different locations [1]. CNN uses convolution, kernel, and pool to perform both different types of mixing, and visual densor uses self-attention to perform them. However, MLP-Mixer tries to implement both functions in a more "independent" manner (will be explained below) and only mlp. The main advantage of using only MLP (essentially matrix multiplication) is the simplicity and calculation speed of the architecture.
How did it work?
This is a fun part, we will discuss how inputs become output, and what the image has happened through the network.
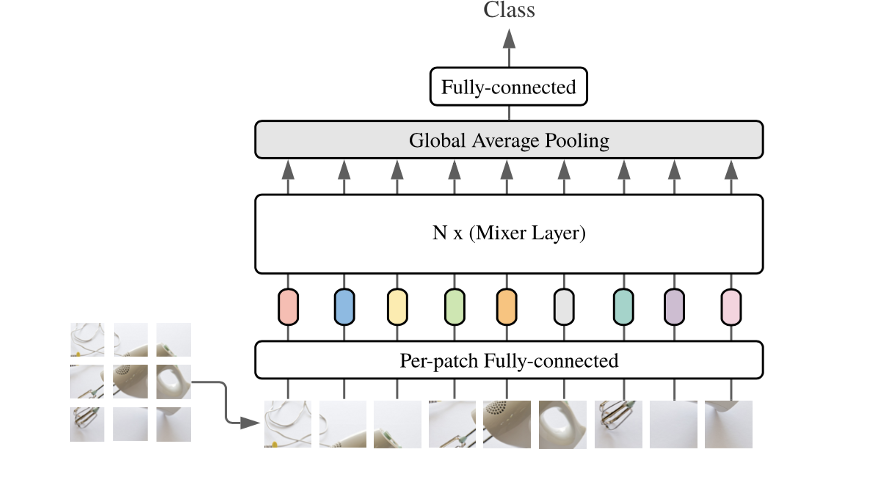
The first fully connected layer will projection into the desired hidden dimension (size depending on the size of the layer). The type of this layer is "PATCHES mix" layer, which makes sense. You can think this is an encoded image, which is a widely used compression tip in the neural network (as an automatic encoder) to reduce the dimension of the image, only to reserve the most critical features. After that, a "table" is constructed from the value of the image patch and the hidden dimensional value.
The column of the PATCHES mixed layer parsing the table performs matrix operation (eg, transposed), and the channel hybrid layer performs matrix operation (which is represented as "mixer layer" above). Then apply a nonlinear activation function [1]. This may sound a bit confusing, but if you can see that the mixer attempts to find the best way to mix and encode channels and image patches to a meaningful output.
It is important to note that the size of the hidden representation of the non-overlapping patch is independent of the number of input patches. It will make this article more than what I want here. Essentially, this gives a very important performance difference, between mlp-mixer and other architectures:
Unlike VIT, MLP-Mixer computational complexity is linear on the number of input patches.
MLP-Mixer also has some advantages that provide many simplified methods for its architecture:
- Layer size
- Each layer contains only 2 MLP blocks
- Each layer accepts the same size input
- All image blocks are linearly projected in the same projection matrix
This makes it more simple to reason for the network than the CNN usually have a pyramid structure [1]. I remember that I tried to design CNN for the first time, and figure out when to narrow the image, when zooming in an image, and the degree of zooming / zooming may be somewhat difficult. However, these problems do not exist in this architecture.
One thing to note is that the model also uses skipping and regularization, but I think we don't have to discuss these concepts because they have been widely used and explained in many other resources.
Last idea
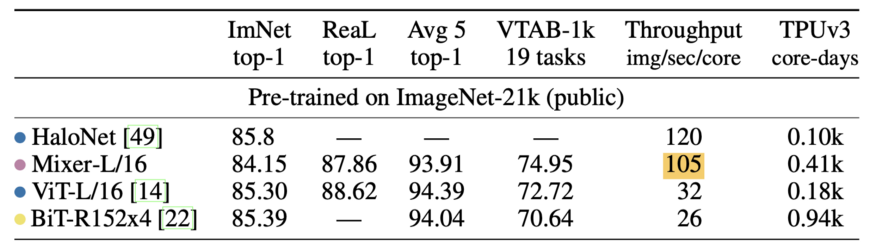
In terms of the results, there are multiple tables that have highlighted a fact that Mixer's performance is very similar to other architectures, but the speed is faster. It "throughput" is 105 images / second / core, while Vision Transformer is 32. It is fairly that this sounds like a very strange indicator, and sometimes it feels like ML researchers try to find an indicator, so that their network seems to be much better than other indicators. However, I think we can objectively agree, using only MLP blocks to achieve the same level of performance is still impressive.
MLP-Mixer Paper: Arxiv: 2105.01601
Our article: Mostafa ibrahim
Deephub translation group
Intelligent Recommendation
MLP-Mixer: a visual architecture that consists of uniform, no attention, pure mlp
Summary At present, computer visual fields use convolutional neural networks (CNN) and self-focused networks (such as VIT). Recently, Google's research team (formerly VIT team) proposes a visual netwo...

MLP-MIXER Detailed
MLP-MIXER Detailed paper《MLP-Mixer: An all-MLP Architecture for Vision》 1 main ideas As a CV framework that the Google VIT team recently raised, MLP-Mixer uses a multi-layer perceived machine (MLP) in...

Personal understanding of MLP-Mixer
main idea: to CHAfter Patch embedding is performed on the image of W, the spatial (global/local) information fusion part and the channel information fusion part are separated. In MLP-Mixer: Assuming t...

MLP-Mixer: Image Identification Network Based on Multi-layer Perception Machine Architecture
Overall guide: Convolutional Neural Network (CNNS) is the mainstream model of computer vision. In recent years, the attention based network, such as Vision Transformer has also been widely used. On Ma...

Paper reading notes | MLP series - MLP-Mixer
If there is any error, please point it out. paper:MLP-Mixer: An all-MLP Architecture for Vision code:https://github.com/google-research/vision_transformer summary: Researchers show that although both ...
More Recommendation
MLP-Mixer: A full mlp network architecture for visual tasks [code implementation (based on mnist)]
This article is based on the MLP-Mixer-Pytorch on Github on GitHub to implement MLP-Mixer Demo on Mnist data. MLP-Mixer: An all-MLP Architecture for Vision[PDF] MLP-Mixer introduction and some ideas [...

Image classification of deep learning (21)-MLP-MIXER network detailed explanation
Image classification of deep learning (21) MLP-MIXER network detailed explanation Table of contents Image classification of deep learning (21) MLP-MIXER network detailed explanation 1 Introduction 2. ...
Thesis reading notes | MLP series-MLP part summary (MLP-MIXER, S2-MLP, AS-MLP, VIP, S2-MLPV2)
If there are mistakes, please point out. This blog is a summary of a summary of the summary of the MLP structure articles. Articles directory 1. MLP-Mixer 2. S2-MLP 3. AS-MLP 4. ViP 5. S2-MLPv2 1. MLP...
MLP-Mixer introduction and some ideas
Recently, Google Research's Brain Team also published a heavy article, pure MLP architecture ------MLP-MixerThis team is the original VIT team with strong strength. The authors have been compared with...
MLP-Mixer,External Attention,RepMLP
MLP-Mixer,External Attention,RepMLP Article catalog MLP-Mixer,External Attention,RepMLP MLP-Mixer:An all-MLP Architecture for Vision (Google) Beyond Self-Attention: External Attention Using Two Linear...