DL-PAPER Entities: MLP-Mixer
tags: Paper reading Machine learning artificial intelligence algorithm Computer vision Depth study
MLP-Mixer: An all-MLP Architecture for Vision
Paper
(Grand Factory is always do not go to the common road, this summary does not follow the past reading mode)
Recently, Google has released a papers "mlp-mixer", which is known as the use of pure MLP structures to achieve SOTA results on ImageNet. A stone aroused a thousand waves, very fast Tsinghua, Oxford, Facebook, etc. also released a similar work, although there is no such as Google as a pure mlp replaces CNN and Transformer. But you can't help but let the industry exclaim, MLP's era is back? The development history of the CV field, mlp -> CNN -> Transformer -> mlp is similar.
For Google, this mlp-mixer is more controversial, and does not discuss, first pay attention to its content.
Network structure
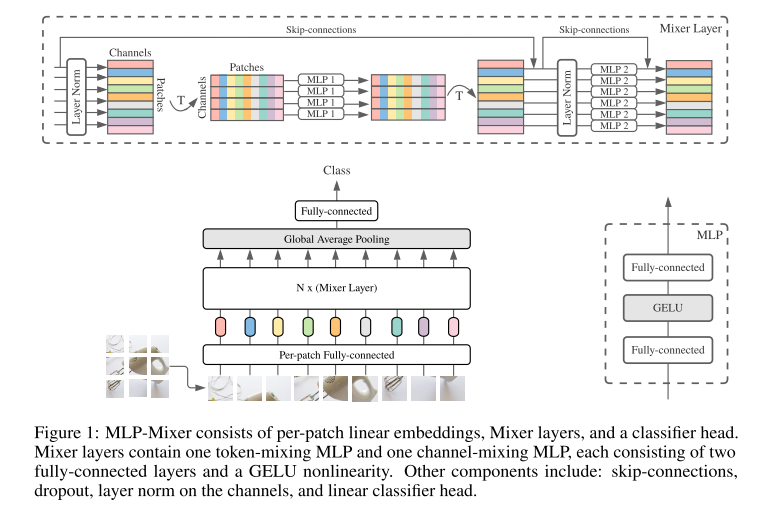
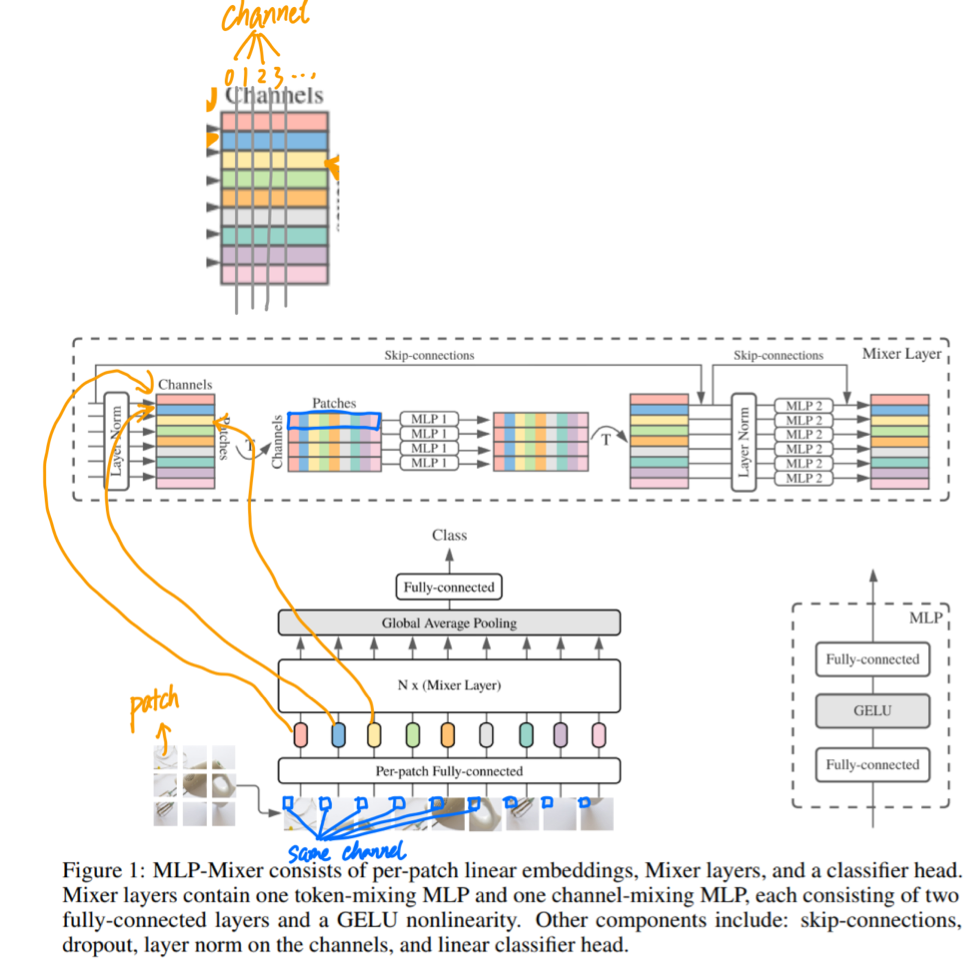
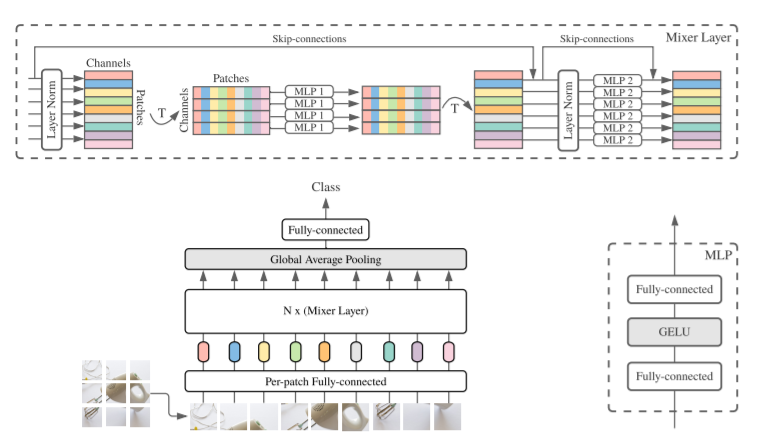
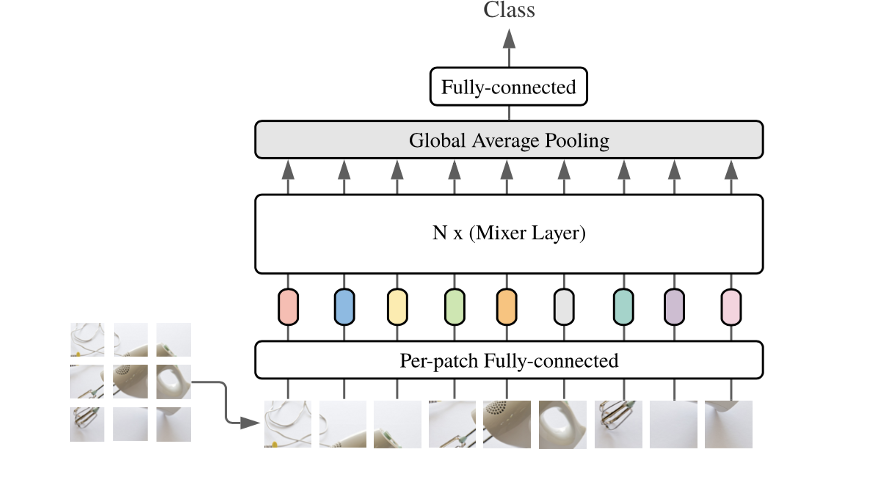
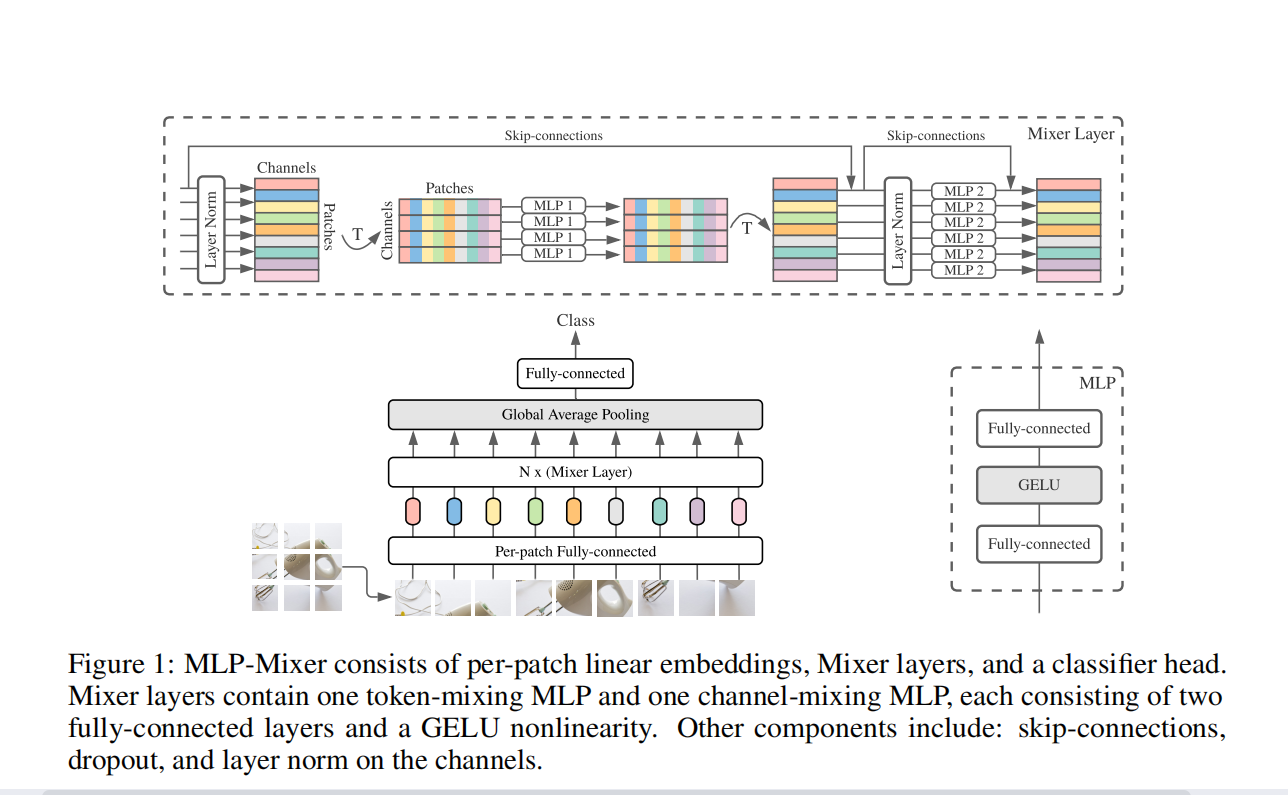
The overall structure is as follows, very simple and clear: Input -> NX (Mixer-mlp) -> ClassFICATION Head. Similar to the structure of the VIT, the main difference is that the module of Encoder is changed to Mixer.
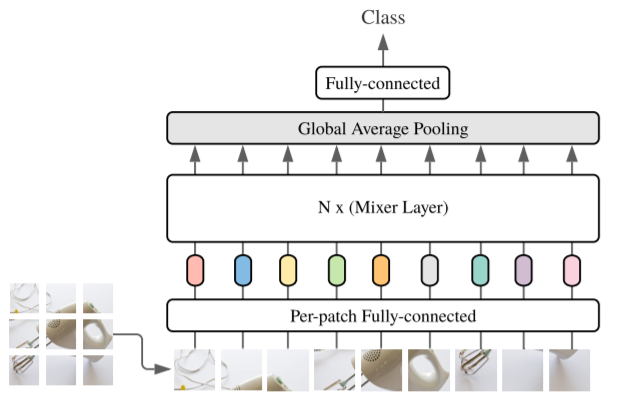
ClassFICATION Head is implemented in conventional global avg_pooling + fc. INPUT uses the practice in the VIT, and the 2-D image is divided into the matrix (S × C) matrix, where S is the number of PATCH, C is Hidden Dimension. It should be noted that the operation of Patch here is that VIT and Mixer are mainly attacked. Two articles are known as pure mlp / attntions, but in essence, in the input PATCH part is separated, consolidation (conv2d: c_in = 3, c_out = c_hid, kerner_size = patch_size (usually 16)) is obtained.
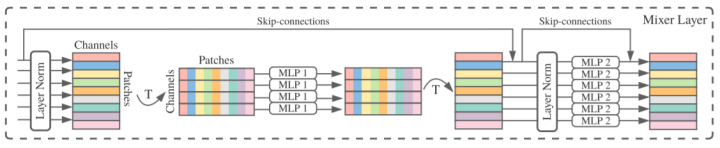
Mainly pay attention to the Mixer module, the structure is shown, as shown above, each Mixer contains a token-mixing mlp and a Channel Mixing MLP, which mixes the input matrix (S × C), respectively. Simply put, it is a matrix of (S × C), first transfers to (C × S) for MLP, and then turn back (S × C) for MLP. Formulas and code indicate more intuitive, as follows:

Mixer in Mixer is mixed with information on both TOKEN and CHANNEL. It is currently uncommon that the operation allows data to communicate between different channels and different spatial locations. Where each MLP operation contains two matrix multiplication.
Repeat the Mixer module n times, the input and output size of each module is all the same, there is no change in Feature resolution, and there is no segment node.
However, it should be noted that although it is pure MLP, in fact, the structure also contains LN, Skip_Connection and other structures, while also adopting some advanced Regularizaiton methods during the training. Therefore, this article is not denying in recent years and re-establishing early results, which also borrowed a lot of new ideas. This is a spiral process.
Experiments
Mixer is pre-trained on large and medium-sized data sets, and then perform performance assessment on the downstream task and compared with CNN and Transformer. The main results are as follows, there are several characteristics, summarized as follows:
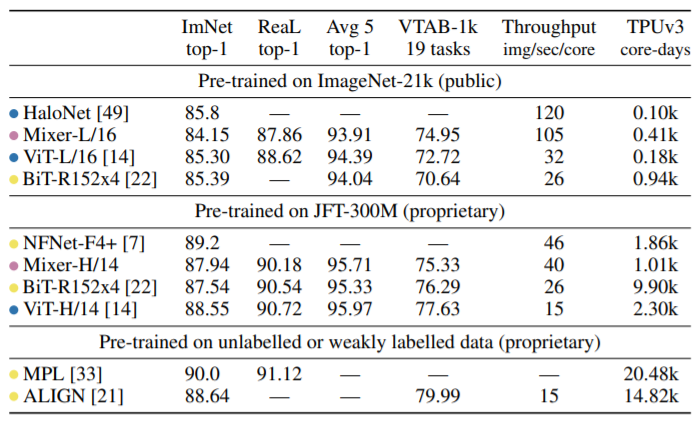
- Mixer implements the results compared to CNN and Transformer in Trade OFF, which is the intensity and training time, and the like. This is also a place to be spit, because the accuracy does not reach SOTA ...
- Mixer's training is closely related to the pre-training parameters. Mixer-B / 16 direct training on ImageNet reaches 76.44% accuracy, but before IMG-21K pre-training, migrate to imageNet to get 80.64% accuracy. This is explained in this paper that Mixer's training has been more severe in the case where the amount of data is small. As the quantity of the pre-training data, Mixer's performance has gradually improved, where Mixer-H / 14 is no weaker than the equivalent CNN or Transformer.
to sum up
Finally, in general, Mixer has given a very simple visual architecture that is in the same amount of existing CNN and Transformer in the tradeoff required for the resources required by accuracy and training in the exact rate and training. This article also mentioned the MLP structure to the precedent of CV research, but it is not rumored to overthrow. In fact, several other articles in the same period, the proposed binding studies of MLP and CNN, and also achieved good results.
For the phenomenon of CV research sets, the words of the big cow

But this phenomenon is not good, just like a computer solution, there is no need to calculate complex high-order differential, numerical analysis, and a large-scale approximation can also achieve good results. Whether CNN, Transformer is MLP, for researchers, good performance is a good architecture. Only engineers who are deployed downstream, need gray face, eat soil ...
Intelligent Recommendation
MLP-Mixer,External Attention,RepMLP
MLP-Mixer,External Attention,RepMLP Article catalog MLP-Mixer,External Attention,RepMLP MLP-Mixer:An all-MLP Architecture for Vision (Google) Beyond Self-Attention: External Attention Using Two Linear...
MLP-Mixer Introduction and PyToch Code
MLP-Mixer Introduction and PyToch Code Mlp-Mixer Network structure TIPS to sum up reference Mlp-Mixer Paper:MLP-Mixer: An all-MLP Architecture for Vision. Pytorch code:An unofficial implementation of ...
Thesis reading notes | MLP series-MLP part summary (MLP-MIXER, S2-MLP, AS-MLP, VIP, S2-MLPV2)
If there are mistakes, please point out. This blog is a summary of a summary of the summary of the MLP structure articles. Articles directory 1. MLP-Mixer 2. S2-MLP 3. AS-MLP 4. ViP 5. S2-MLPv2 1. MLP...
MLP-Mixer Pytorch Implementation and Analysis (2)
First of all, the parameters are as follows (enter the picture 3 * 224 * 224): In_Channels: Enter the number of channels, 3. DIM: The number of output channels of the convolution operation is OUT_CHAN...

MLP-Mixer Pytorch Implementation and Analysis (1)
MLP-Mixer Network Structure Analysis:MLP-MIXER: ALL-MLP Architecture for Vision_hzdh blog - CSDN blog Mixer's Pytorch code is difficult to implementMatrix rotation,USUse the REARRANGE implementation m...
More Recommendation
Day 3: MLP-Mixer: An all-MLP Architecture for Vision
This article is about the latest multi-level perception machine, the main contribution of the article is as follows The author said domineering: "Although convolutional and attention mechanisms h...
MLP-Mixer: a visual architecture that consists of uniform, no attention, pure mlp
Summary At present, computer visual fields use convolutional neural networks (CNN) and self-focused networks (such as VIT). Recently, Google's research team (formerly VIT team) proposes a visual netwo...
Google MLP-Mixer: All MLP Architecture for Image Processing
Image processing is one of the most interesting sub-areas in machine learning. It starts from multi-layer sensitization, and later, it has been convolved, and later develops the attention mechanism, t...

Document reading (22): mlp-mixer: an all-mlp architecture for vision
Document reading (22): mlp-mixer: an all-mlp architecture for vision Summary 1 Introduction 2 Mixer Architecture 3 Experiments 3.1 Main results 3.2 The role of the model scale 3.3 The role of the pre-...
Attached code MLP-MIXER: An All-MLP Architecture for Vision Thesis Interpretation
Mlp-mixer: an all-mlp architecture for vision paper interpretation Reference connection: Summary: In the case of no convolution or self-attention, we proposed MLP-Mixer, a architecture specifically ba...