Caffe learning-source code analysis of syncedmem.cpp and syncedmem.hpp
tags: syncedmem.cpp The data is the same
#ifndef CAFFE_SYNCEDMEM_HPP_
#define CAFFE_SYNCEDMEM_HPP_
#include <cstdlib>
#include "caffe/common.hpp"
namespace caffe {
/ * Translation of the following notes :::
When Cuda is available and in GPU mode, cudaMallocHost can be used to allocate fixed memory.
Such allocated memory will not be dynamically occupied by memory access mechanisms such as DMA,
The memory allocated in this way will not have much use for a single GPU,
But it will be more useful for parallel training. In particular, such allocated memory can significantly improve the stability of large models in the case of multiple GPUs * /
// If CUDA is available and in GPU mode, host memory will be allocated pinned,
// using cudaMallocHost. It avoids dynamic pinning for transfers (DMA).
// The improvement in performance seems negligible in the single GPU case,
// but might be more significant for parallel training. Most importantly,
// it improved stability for large models on many GPUs.
inline void CaffeMallocHost(void** ptr, size_t size, bool* use_cuda) {
#ifndef CPU_ONLY
if (Caffe::mode() == Caffe::GPU) {
CUDA_CHECK (cudaMallocHost (ptr, size)); // Using cuda to provide library functions to allocate memory in GPU mode
*use_cuda = true;
return;
}
#endif
* ptr = malloc (size); // In single CPU mode, it is allocated by the malloc function of c
*use_cuda = false;
CHECK(*ptr) << "host allocation of size " << size << " failed";
}
inline void CaffeFreeHost(void* ptr, bool use_cuda) {
#ifndef CPU_ONLY
if (use_cuda) {
CUDA_CHECK (cudaFreeHost (ptr)); // Using the cuda library function cudaFreeHost in GPU mode to release memory
return;
}
#endif
free (ptr); // Single CPU mode uses C library function to release memory
}
/**
* @brief Manages memory allocation and synchronization between the host (CPU)
* and device (GPU).
*
* TODO(dox): more thorough description.
*/
class SyncedMemory {
public:
SyncedMemory () // Constructor, responsible for initialization
: cpu_ptr_(NULL), gpu_ptr_(NULL), size_(0), head_(UNINITIALIZED),
own_cpu_data_(false), cpu_malloc_use_cuda_(false), own_gpu_data_(false),
gpu_device_(-1) {}
explicit SyncedMemory (size_t size) // With explicit keyword, there is a single parameter constructor, explicit prohibits the implicit conversion of single parameter constructor
: cpu_ptr_(NULL), gpu_ptr_(NULL), size_(size), head_(UNINITIALIZED),
own_cpu_data_(false), cpu_malloc_use_cuda_(false), own_gpu_data_(false),
gpu_device_(-1) {}
~SyncedMemory();
const void * cpu_data (); / * Return the allocated CPU memory address: cpu_ptr _ * /
void set_cpu_data (void * data); / * The memory pointed to by cpu_ptr_ is released, and cpu_ptr_ points to the memory pointed to by the input data * /
const void * gpu_data (); / * If GPU mode, return the memory address of the allocated gpu: gpu_ptr _ * /
void set_gpu_data (void * data); / * If GPU mode, the memory pointed to by gpu_ptr_ is released, and gpu_ptr_ points to the memory pointed to by the input data * /
void * mutable_cpu_data (); / * Return the allocated CPU memory address: cpu_ptr_, set the state to head_ = HEAD_AT_CPU * /
void * mutable_gpu_data (); / * If GPU mode, return the allocated memory address of gpu: gpu_ptr_, set the state to head_ = HEAD_AT_GPU * /
enum SyncedHead {UNINITIALIZED, HEAD_AT_CPU, HEAD_AT_GPU, SYNCED}; / * SyncedHead enumeration type, used to set the status of head _ * /
SyncedHead head () {return head_;} / * Return the corresponding data memory status * /
size_t size () {return size_;} / * Return data memory size * /
#ifndef CPU_ONLY
void async_gpu_push (const cudaStream_t & stream); / * Asynchronously transfer data, copy data from cpu to gpu * /
#endif
private:
void to_cpu (); / * See note in .cpp * /
void to_gpu (); / * See note in .cpp * /
void * cpu_ptr_; / * cpu memory data pointer * /
void * gpu_ptr_; / * gpu memory data pointer * /
size_t size_; / * Data memory size * /
SyncedHead head_; / * Data status * /
bool own_cpu_data_; / * Is there cpu memory * /
bool cpu_malloc_use_cuda_;
bool own_gpu_data _; / * Is there GPU memory * /
int gpu_device_; / * Device ID number of GPU * /
DISABLE_COPY_AND_ASSIGN (SyncedMemory); / * See common.cpp analysis * /
}; // class SyncedMemory
} // namespace caffe
#endif // CAFFE_SYNCEDMEM_HPP_#######slightly##########
/ * If it is the first initialization, CaffeMallocHost allocates CPU memory,
If the data is in the GPU state, if it is in GPU mode, allocate CPU memory, copy the GPU memory data to the CPU,
If the data is in the CPU state or has been synchronized, it is not processed
In short, the data is synchronized to the CPU * /
inline void SyncedMemory::to_cpu() {
switch (head_) {
case UNINITIALIZED:
CaffeMallocHost(&cpu_ptr_, size_, &cpu_malloc_use_cuda_);
caffe_memset(size_, 0, cpu_ptr_);
head_ = HEAD_AT_CPU;
own_cpu_data_ = true;
break;
case HEAD_AT_GPU:
#ifndef CPU_ONLY
if (cpu_ptr_ == NULL) {
CaffeMallocHost(&cpu_ptr_, size_, &cpu_malloc_use_cuda_);
own_cpu_data_ = true;
}
caffe_gpu_memcpy(size_, gpu_ptr_, cpu_ptr_);
head_ = SYNCED;
#else
NO_GPU;
#endif
break;
case HEAD_AT_CPU:
case SYNCED:
break;
}
}
/ * If it is processed in GPU mode, an error will be reported if it is in single cpu mode
If the data is in the first initialization state, allocate GPU memory and initialize to 0
If the data is in the CPU state, allocate GPU memory to copy the data from the CPU to the GPU
Not deal with other situations,
In short, the data synchronization is GPU * /
inline void SyncedMemory::to_gpu() {
#ifndef CPU_ONLY
switch (head_) {
case UNINITIALIZED:
CUDA_CHECK(cudaGetDevice(&gpu_device_));
CUDA_CHECK(cudaMalloc(&gpu_ptr_, size_));
caffe_gpu_memset(size_, 0, gpu_ptr_);
head_ = HEAD_AT_GPU;
own_gpu_data_ = true;
break;
case HEAD_AT_CPU:
if (gpu_ptr_ == NULL) {
CUDA_CHECK(cudaGetDevice(&gpu_device_));
CUDA_CHECK(cudaMalloc(&gpu_ptr_, size_));
own_gpu_data_ = true;
}
caffe_gpu_memcpy(size_, cpu_ptr_, gpu_ptr_);
head_ = SYNCED;
break;
case HEAD_AT_GPU:
case SYNCED:
break;
}
#else
NO_GPU;
#endif
}
#######slightly##########Intelligent Recommendation
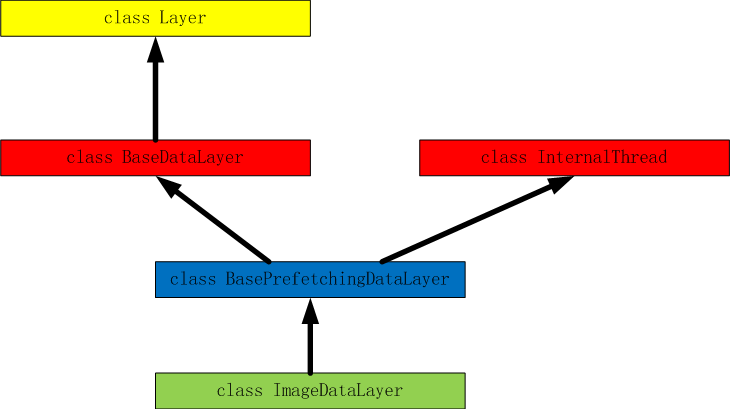
Analysis of ImageDataLayer of Caffe source code
table of Contents ImageDataLayer parameters Source root_folder new_height、new_width is_color crop_size Prototxt configuration Class ImageDataLayer Inheritance Source code DataLayerSetUp Get param...
Analysis of Layer_factory of Caffe source code
in<Analysis of the Layer of Caffe source code>, Basic analysis of the Layer code, we can know that Layer is the basic class of all other Layers, which expands the layers needed in each neural ne...
Caffe source code: blob analysis
directory table of Contents basic introduction Source code analysis Reshape function Blob constructor data_ data manipulation function Back propagation derivative diff_ operation function ShareData fu...
Caffe Source Code Analysis Solver
Solver: Network Solution Strategy Solver mainly implements the optimization algorithm used by the training model parameters. Different classes are derived depending on the optimization algorithm, and ...
CAFFE source code analysis NET
NET: Network's overall skeleton NET is a representation of the entire network. It is made up of a variety of Layer before and after connecting, NETs are in order to place multiple layers in the form o...
More Recommendation
CAFFE source code analysis Layer
Layer: Basic unit of the network Layer is an abstraction of various layers in neural networks, including the convolutional layer and the sample sample we are well known, as well as a full-connection l...

Deep learning library caffe use source code analysis dependent library analysis caffe glog gflags openBlas prototxt yolo_darknet to caffe
Deep learning library caffe uses source code analysis Dependency library analysis caffe glog gflags openBlas This article github link yolo_darknet to caffe caffe installation Caffe code analysis Caffe...

Caffe softmax source code interpretation of the caffe source code learning
Forward propagation Backward propagation...
CAFFE source code analysis (2) - SYNCEDMEMORY analysis
Today we analyze the underlying data format in Caffe. In Caffe, the data is stored in the form of a one-dimensional array. And because data exchange between the CPU and the GPU is therefore defined in...
Caffe source code learning 2: Glog learning
Google glog is a library that implements application-level logging. This library provides logging APIs based on C++ style streams and various helper macros. You can stream the content to LOG by simply...