Caffe softmax source code interpretation of the caffe source code learning
Forward propagation
template <typename Dtype>
void SoftmaxLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = top[0]->mutable_cpu_data();
Dtype* scale_data = scale_.mutable_cpu_data();
int channels = bottom[0]->shape(softmax_axis_);
int dim = bottom[0]->count() / outer_num_; //dim represents the number of categories to be classified, count() gets the total number of input blobs, and outer_num_ gets the number of blobs for each category
caffe_copy(bottom[0]->count(), bottom_data, top_data); //First copy the input to the output buffer
// We need to subtract the max to avoid numerical issues, compute the exp,
// and then normalize, subtract the maximum value, avoid numerical problems, calculate the exponent, and normalize
for (int i = 0; i < outer_num_; ++i) {
// Initialize the data field of scale_ as the first plane, where scale is used to store temporary calculation results
caffe_copy(inner_num_, bottom_data + i * dim, scale_data);
for (int j = 0; j < channels; j++) {
for (int k = 0; k < inner_num_; k++) {
scale_data[k] = std::max(scale_data[k],
bottom_data[i * dim + j * inner_num_ + k]);
}
}
// output buffer minus maximum value
//a_k = a_k - max(a_i)
// C = alpha . A . B + beta * C
// A is the unit 1 matrix
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels, inner_num_,
1, -1., sum_multiplier_.cpu_data(), scale_data, 1., top_data);
// exponentiation
caffe_exp<Dtype>(dim, top_data, top_data);
// sum after exp
caffe_cpu_gemv<Dtype>(CblasTrans, channels, inner_num_, 1.,
top_data, sum_multiplier_.cpu_data(), 0., scale_data);
// division
for (int j = 0; j < channels; j++) {
caffe_div(inner_num_, top_data, scale_data, top_data);
top_data += inner_num_;
}
}
}Backward propagation
template <typename Dtype>
void SoftmaxLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
//Get data, diff pointer
const Dtype* top_diff = top[0]->cpu_diff();
const Dtype* top_data = top[0]->cpu_data();
Dtype* bottom_diff = bottom[0]->mutable_cpu_diff();
Dtype* scale_data = scale_.mutable_cpu_data();
int channels = top[0]->shape(softmax_axis_);
int dim = top[0]->count() / outer_num_;
caffe_copy(top[0]->count(), top_diff, bottom_diff); //First initialize bottom_diff with top_diff
for (int i = 0; i < outer_num_; ++i) {
// Calculate the dot product of top_diff and top_data, and then subtract the value from bottom_diff
for (int k = 0; k < inner_num_; ++k) {
scale_data[k] = caffe_cpu_strided_dot<Dtype>(channels,
bottom_diff + i * dim + k, inner_num_,
top_data + i * dim + k, inner_num_);
}
// Impairment
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels, inner_num_, 1,
-1., sum_multiplier_.cpu_data(), scale_data, 1., bottom_diff + i * dim);
}
// multiply point by point
caffe_mul(top[0]->count(), bottom_diff, top_data, bottom_diff);
}

Intelligent Recommendation
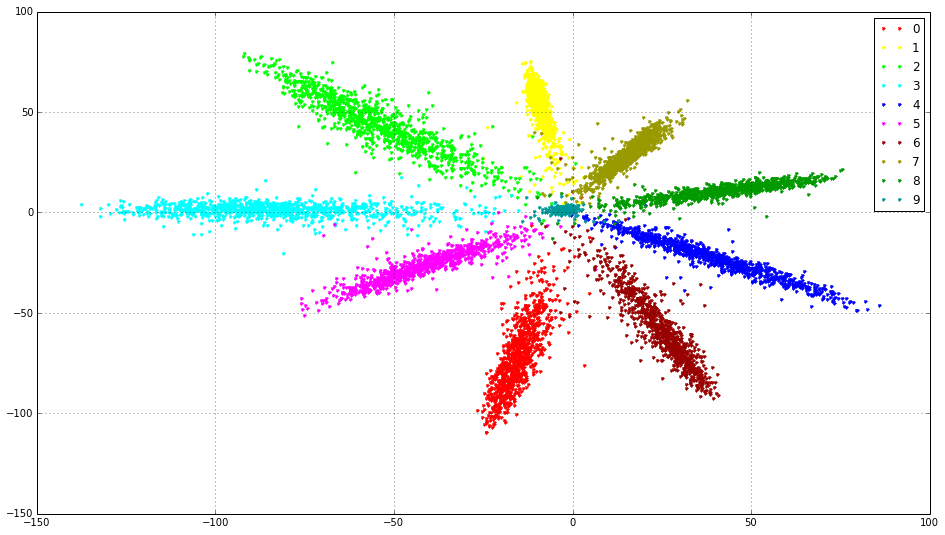
Caffe source code interpretation (2)-center_loss_layer.cpp
center_loss formula definition Center_loss_layer.cpp source code interpretation Comparative experiment of center loss and softmax loss on mnist data set definition "Center Loss: simultaneously le...
Caffe source code interpretation (12)-convert_imageset.cpp
caffe The allowed data type in can be LMDB or LEVELDB , caffe A tool for converting images to LMDB is provided in caffe_dir/tools/convert_imageset.cpp. The source code is briefly analyzed below: Main ...
Caffe source code interpretation (13)-blob.hpp
Caffe uses four-dimensional arrays called blobs to store and exchange data. Blob provides a unified memory interface, holding a batch of images or other data, weights, and weight update values. Blob...
Caffe source code interpretation (1)-softmax_loss_layer.cpp
Softmax formula definition Caffe source code interpretation definition "Softmax function is a generalization of the logistic function that maps a length-p vector of real values to a length-K ve...
Caffe source code interpretation (3)-contrast_loss_layer.cpp
Definition The loss function was first proposed in this paper and was mainly used for dimensionality reduction processing.link Contrastive loss is used in the siamese network in caffe. This loss funct...
More Recommendation
Caffe source code interpretation (4)-concate_layer.cpp and slice_layer.cpp
1. Concate Role: to realize the splicing of multiple input data Input: x1,x2,…,xk Output: y x1: N*C*H*W x2: N*C*H*W xk: N*C*H*W y: kN*C*H*W(concate_dim=0) y: N*kC*H*W(concate_dim=1) Parameters:...
Caffe source code interpretation (7)-data_transformer.cpp
The DataTransformer class is mainly responsible for preprocessing the data, such as subtracting the mean value, performing crop, mirroring mirror, forced setting to color image force_color, forced set...
Caffe source code interpretation (5)-image_data_layer.cpp
Data layer: Image_data_layer layer is mainly used for caffe data processing from pictures. Layer type:ImageData Parameters that must be set:①source: the name of a text file, each line gives the name a...
Caffe source code interpretation (9)-euclidean_loss_layer.cpp
formula Parameters: bottom[0], bottom[1], top[0] 1. (N*C*H*W) the predictions: yn^ y n ^ –>bottom[0] 2. (N*C*H*W) the targets: yn y n –>bottom[1] 3. (1*1*1*1) the computed Euclidean ...
Caffe source code interpretation (11)-triplet_loss_layer.cpp
definition TripletLoss T r i p l e t L o s s Is proposed in this paper—FaceNet: A Unified Embedding for Face Recognition and Clustering, TripletLoss T r i p l e t L o s s The definition is as fo...