Caffe source code reading softmax data layer
Do not build a platform in floating sand.
Most of the Chinese people are impetuous, and pigs like to run to the wind. I used to be no exception.
template <typename Dtype>
void SoftmaxLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
softmax_axis_ =
bottom[0]->CanonicalAxisIndex(this->layer_param_.softmax_param().axis());
top[0]->ReshapeLike(*bottom[0]);
vector<int> mult_dims(1, bottom[0]->shape(softmax_axis_));
sum_multiplier_.Reshape(mult_dims);
Dtype* multiplier_data = sum_multiplier_.mutable_cpu_data();
caffe_set(sum_multiplier_.count(), Dtype(1), multiplier_data);
// start of liqiming added code
const string s = "liqiming debuging softmax layer!!"
Log(s)
char* t;
sprintf_s(t,"%d",softmax_axis_) // The output here should be 1, which is softmax_axis_ = 1;
Log(t)
//// end of liqiming added code
outer_num_ = bottom[0]->count(0, softmax_axis_); // This is actually shape_(0), the corresponding dimension is n
inner_num_ = bottom[0]->count(softmax_axis_ + 1); // shape_(2)*shape_(4), corresponding to h*w
vector<int> scale_dims = bottom[0]->shape();
scale_dims[softmax_axis_] = 1;
scale_.Reshape(scale_dims);
}
Can be inferred in the source insight software
outer_num = =n;
inner_num = = h*w;
How have you been bothering me from the blob?
Eliminate this question by reading the softmax data layer.
Before diving into the details, I will draw a picture to show the next blob:

From this figure, we can easily see the data in the blob: you can take the following operations:
for ( int i = 0; i < n; i++)
{
for ( int j = 0; j < c; j++ )
{
for ( int k = 0; k < h*w; k++ )
value = blob[i*c*h*w+j*h*w+k]
}
}
Dear readers, please see the following function:
template <typename Dtype>
void SoftmaxLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = top[0]->mutable_cpu_data();
Dtype* scale_data = scale_.mutable_cpu_data();
int channels = bottom[0]->shape(softmax_axis_);
int dim = bottom[0]->count() / outer_num_;
caffe_copy(bottom[0]->count(), bottom_data, top_data);
// We need to subtract the max to avoid numerical issues, compute the exp,
// and then normalize.
for (int i = 0; i < outer_num_; ++i) { // where outer_num_ == n
// initialize scale_data to the first plane
caffe_copy(inner_num_, bottom_data + i * dim, scale_data); //
for (int j = 0; j < channels; j++) { // where channels == c
for (int k = 0; k < inner_num_; k++) { // inner_num_ == h*w here
scale_data[k] = std::max(scale_data[k],
bottom_data[i * dim + j * inner_num_ + k]);
}
}
// subtraction
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels, inner_num_,
1, -1., sum_multiplier_.cpu_data(), scale_data, 1., top_data);
// exponentiation
caffe_exp<Dtype>(dim, top_data, top_data);
// sum after exp
caffe_cpu_gemv<Dtype>(CblasTrans, channels, inner_num_, 1.,
top_data, sum_multiplier_.cpu_data(), 0., scale_data);
// division
for (int j = 0; j < channels; j++) {
caffe_div(inner_num_, top_data, scale_data, top_data);
top_data += inner_num_;
}
}
}
Intelligent Recommendation
Caffe source code reading layer(2)-Euclidean_loss_layer layer
Because the project needs to be positioned, the euclidean_loss_layer layer needs to be used. Here, I have a special look at the source code and location of this layer. E:\Caffe\caffe-windows\include\c...

Caffe softmax source code interpretation of the caffe source code learning
Forward propagation Backward propagation...
caffe detailed softmax layer
softmax layer softmax layer: output likelihood value The formula is as follows: softmax-loss layer: output loss value The formula is as follows: loss_param Description: ignore_label Int variable...
Analysis of caffe softmax-loss source code formula
Transfer from: https://blog.csdn.net/mzpmzk/article/details/53083579 Loss Function The calculation of softmax_loss consists of 2 steps: (1) Calculate the normalized probability of softmax # Why subtra...

Caffe source code pooling layer
The pooling layer is actually a bit similar to the convolutional layer. There is a window similar to the convolution kernel that moves according to a fixed step. Each window does a certain operation, ...
More Recommendation
Caffe source code dropout layer
This article is reproduced from: http://blog.csdn.net/lanxueCC/article/details/53319872?locationNum=2&fps=1 This article mainly analyzes the caffe source code file /src/caffe/layers/Dropout_layer....
CAFFE Source Code Tracking --layer
First come and see caffe / include / caffe / layer.hpp There are many layers of parameters here, and the layer parameters are defined in this file. Caffe / src / caffe / proto / caffe.proto layer.cpp ...
CAFFE source code analysis Layer
Layer: Basic unit of the network Layer is an abstraction of various layers in neural networks, including the convolutional layer and the sample sample we are well known, as well as a full-connection l...
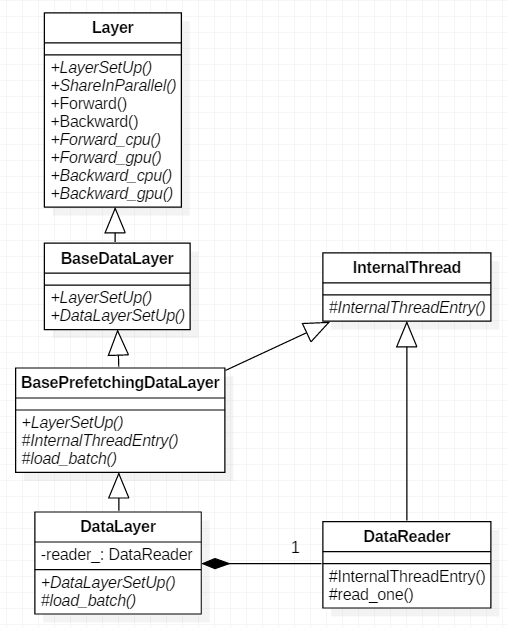
Caffe framework source code analysis (3)-data layer DataLayer
When the Caffe network is forwarded, the first step is the transmission of the DataLayer data layer. This layer reads data from the file and loads it to the convolutional layer above it. When backprop...
CAFFE source code (12): Custom data input layer
The first, 3, 4, 5 steps follow the custom neural layer of the previous section. Data input layer needs to rewrite three functions: 1. Datalayersetup: Define the parameter name and container of the Pa...