Java 4 common ways to parse xml: DOM SAX JDOM DOM4J
tags: Java # java IO flow # java file analysis
Four characteristics of Java parsing XML
1. DOM analysis:
forms a tree structure, which helps to better understand and master, and the code is easy to write.
During the parsing process, the tree structure is stored in memory for easy modification.
2. SAX analysis:
uses event-driven mode, which consumes less memory.
is suitable when only processing data in an XML file
3. JDOM analysis:
Only use concrete classes, not interfaces.
The API makes extensive use of the Collections class.
4. DOM4J analysis:
A smart branch of JDOM that incorporates many functions beyond the basic XML document representation.
It uses interfaces and abstract basic class methods. It has the characteristics of excellent performance, good flexibility, powerful functions and extremely easy to use.
is an open source file
Code:
First prepare a book.xml file and place it in the src directory:
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book id="1001">
<name>Three Kingdoms</name>
<author>Luo Guanzhong</author>
<price>98.5</price>
</book>
<book id="1002">
<name>Water Margin</name>
<author>Shi Nai'an</author>
<price>89.7</price>
</book>
<book id="1003">
<name>Journey to the West</name>
<author>Wu Chengen</author>
<price>99.9</price>
</book>
<book id="1004">
<name>Dream of the Red Chamber</name>
<author>Cao Xueqin</author>
<price>77.7</price>
</book>
</books>
1. DOM analysis:
package com.xzlf.xml;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
/**
* DOM parsing XML
* @author xzlf
*
*/
public class DOMParseTest {
public static void main(String[] args) throws Exception {
// 1. Create a DocumentBuilderFactory factory object
DocumentBuilderFactory docFactory = DocumentBuilderFactory.newInstance();
// 2. Create DocumentBuilder object through factory object
DocumentBuilder docBuilder = docFactory.newDocumentBuilder();
// 3. Get the Document object through the parse (...) method of DocumentBuilder
Document doc = docBuilder.parse("src/book.xml");
// 4. Get the list of nodes
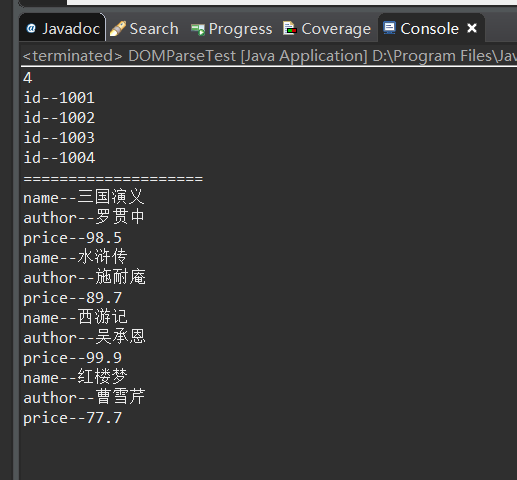
NodeList bookList = doc.getElementsByTagName("book");
System.out.println(bookList.getLength());
// Traverse node attributes
for (int i = 0; i < bookList.getLength(); i++) {
// Get the attributes and values of each node
Node item = bookList.item(i);
// Get the property collection
NamedNodeMap attributes = item.getAttributes();
// Traverse the property collection
for (int j = 0; j < attributes.getLength(); j++) {
Node id = attributes.item(j);
System.out.println(id.getNodeName() + "--" + id.getNodeValue());
}
}
// Traverse the child nodes
System.out.println("====================");
for (int i = 0; i < bookList.getLength(); i++) {
Node item = bookList.item(i);
NodeList childNodes = item.getChildNodes();
for (int j = 0; j < childNodes.getLength(); j++) {
Node child = childNodes.item(j);
if(child.getNodeType() == Node.ELEMENT_NODE) {
System.out.println(child.getNodeName() + "--" + child.getTextContent());
}
}
}
}
}
run:
2. SAX analysis:
package com.xzlf.xml;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
/**
* Sax parses xml
* @author xzlf
*
*/
public class SAXParseTest {
public static void main(String[] args) throws Exception {
// 1. Create an object of SAXParserFactory
SAXParserFactory saxFactory = SAXParserFactory.newInstance();
// 2. Create SAXParser object (parser)
SAXParser parser = saxFactory.newSAXParser();
// 3. Create a subclass of DefaultHandler
BookHandler handler = new BookHandler();
// 4. Call the parse method
parser.parse("src/book.xml", handler);
}
}
class BookHandler extends DefaultHandler{
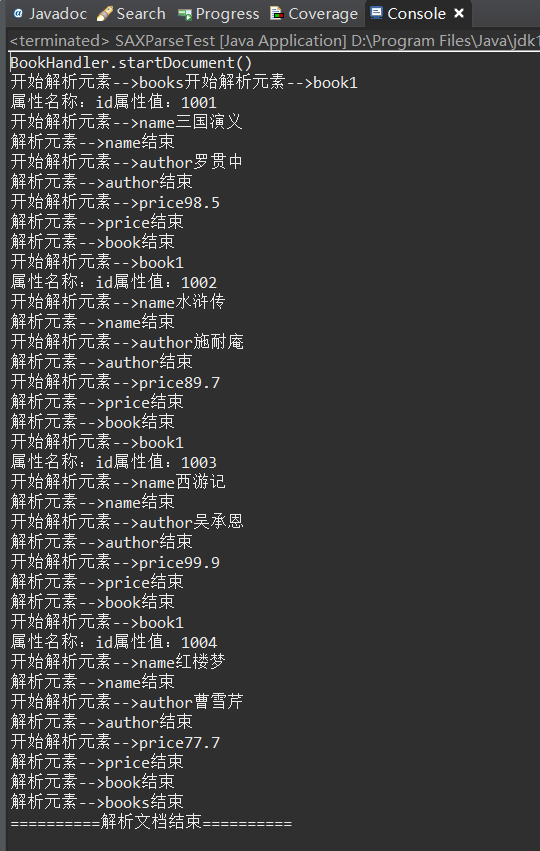
/*Called when starting to parse the xml document*/
@Override
public void startDocument() throws SAXException {
System.out.println("BookHandler.startDocument()");
}
/*Called at the end of parsing the xml document*/
@Override
public void endDocument() throws SAXException {
System.out.println("==========End of parsing document==========");
}
/*Called when starting to parse the nodes in the document*/
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
System.out.print("Start parsing element -->" + qName );
if("book".equals(qName)) {
System.out.println(attributes.getLength());
for (int i = 0; i < attributes.getLength(); i++) {
String attName = attributes.getQName(i);//Attribute name
String attValue = attributes.getValue(i);//Attribute value
System.out.println("Attribute name:" + attName + "Attribute value:" + attValue);
}
}
}
/*Called when the node in the parsing document ends*/
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
System.out.println("Analyze elements-->" + qName + "End" );
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
String values = new String(ch, start, length);
if(!"".equals(values.trim()))
System.out.println(values);
}
}
run:
3. JDOM analysis:
package com.xzlf.xml;
import java.io.File;
import java.util.List;
import org.jdom.Attribute;
import org.jdom.Document;
import org.jdom.Element;
import org.jdom.input.SAXBuilder;
/**
* JDOM parsing xml
* Need to guide package: http://www.jdom.org/downloads/index.html
* @author xzlf
*
*/
public class JDOMParseTest {
public static void main(String[] args) throws Exception{
// 1. Create a SAXBuilder object
SAXBuilder sb = new SAXBuilder();
// 2. Call the build method to get the Document object (via IO stream)
Document doc = sb.build(new File("src/book.xml"));
// 3. Get the root node
Element rootEle = doc.getRootElement();//books
// 4. Get the collection of direct children of the root node
List<Element> children = rootEle.getChildren();
// 5. Traverse the collection
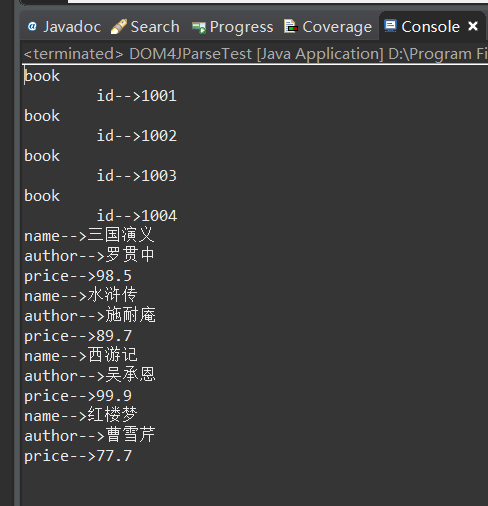
for (int i = 0; i < children.size(); i++) {
Element ele = children.get(i);
// Get the attribute collection
List<Attribute> attributes = ele.getAttributes();
// Traverse the collection of attributes to get each attribute
for (Attribute attr : attributes) {
System.out.println(attr.getName() + "-->" + attr.getValue());
}
}
// Get every child node
System.out.println("===========Child node==============");
for (int i = 0; i < children.size(); i++) {
Element book = children.get(i);
List<Element> ele = book.getChildren();
for (Element e : ele) {
System.out.print(e.getName() + "-->" + e.getValue() + "\t");
}
System.out.println();
}
}
}
run:

4. DOM4J analysis:
package com.xzlf.xml;
import java.io.File;
import java.util.Iterator;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
/**
* DOM4J parses XML
* Need to guide package: https://dom4j.github.io/#looping
* @author xzlf
*
*/
public class DOM4JParseTest {
public static void main(String[] args) throws DocumentException {
// 1. Create a SAXReader object
SAXReader reader = new SAXReader();
// 2. Call the read method
Document doc = reader.read(new File("src/book.xml"));
// 3. Get the root element
Element root = doc.getRootElement();//books
// 4. Traverse the direct node through the iterator
for(Iterator<Element> iterator = root.elementIterator(); iterator.hasNext();) {
Element book = iterator.next();
System.out.println(book.getName());
//Get the attributes of book
for (Iterator<Attribute> iter = book.attributeIterator(); iter.hasNext();) {
Attribute attr = iter.next();
System.out.println("\t" + attr.getName() + "-->" + attr.getValue());
}
}
// Iterate over each book element
for (Iterator<Element> iterator = root.elementIterator(); iterator.hasNext();) {
Element book = iterator.next();
//Get every child element
for (Iterator<Element> iter = book.elementIterator(); iter.hasNext();) {
Element ele = iter.next();
System.out.println(ele.getName() + "-->" + ele.getText());
}
}
}
}
run:
Intelligent Recommendation
[Switch] Java operation (DOM, SAX, JDOM, DOM4J) four ways of comparison and detailed xml
DOM (JAXP Crimson parser) DOM is the official W3C standard for representing XML documents in a platform- and language-independent manner. A DOM is a collection of nodes or pieces of information ...
Java parsing xml -- DOM4J JDOM DOM SAX comparison
2019 Unicorn Enterprise Heavy Gold Recruitment Python Engineer Standard >>> DOM4J http://dom4j.sourceforge.net Although DOM4J represents a completely independent development result, init...
Java XML parsing methods (DOM, SAX, JDOM, DOM4J)
Java XML parsing method 1. Introduction to XML 2. XML parsing 2.1 DOM analysis 2.2 SAX analysis 2.3 JDOM analysis 2.4 DOM4J analysis 1. Introduction to XML XML Value Extensible Markup Language is used...

XML analysis (SAX, DOM, JDOM, DOM4J)
content 1, interview questions: 2, DOM4J parsing XML file 3, XPath Analysis XML file 1, interview questions: ask: JavaThere are severalXMLAnalytical way? What is it?? What kind of advantages and disad...
Java parsing xml file (three ways - (dom, jdom, dom4j)
Test.xml file The first one, use dom to parse xml files without jar package The output is: Second, to parse the xml file using the Jdom method, you need to downl...
More Recommendation
[XML] XML parsing method (dom+sax) and parser (dom4j+jaxp+jdom)
1.xml parsing method (technical): dom and sax >>dom way to parse: Allocate a tree structure in memory according to the hierarchical structure of xml, and encapsulate the tags, attributes and tex...
DOM, SAX, DOM4J, JDOM, StAX generate an XML string and returns XML
used herein, DOM, SAX, DOM4J, JDOM and in JDK1.6 StAX generate new XML data format, and returns an XML string. Said here about StAX way. New features JDK6 of StAX (JSR 173) API JDK6.0 is in addition t...
Java parsing xml, parsing xml four methods, DOM, SAX, JDOM, DOM4j, XPath
【introduction】 At present, there are many techniques for parsing XML in Java. The mainstream ones are DOM, SAX, JDOM, and DOM4j. The following mainly introduces the use, advantages, disadvantages, and...
DOM4J and JDOM parse XML
DOM4J parsing: JDOM parsing: Generate an XML file:...
Comparison of XML methods DOM, SAX, DOM4J, JDOM, StAX
Detailed explanation and comparison of JAM parsing XML methods DOM, SAX, DOM4J, JDOM, StAX 1. Detailed explanation of various ways 1) DOM (JAXP Crimson parser) DOM is the official W3C standard for rep...