DOM, SAX, JDOM, DOM4J four ways to parse xml
First create an xml document, the content of the document is as follows
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book id="1">
<name>Programming Beauty</name>
<price>34.0</price>
<author> "The Beauty of Programming" group</author>
</book>
<book id="2">
<name>Ordinary World</name>
<price>56.0</price>
<author> </author>
<language> </language>
</book>
</bookstore>Because the xml definition is the book's book details, after parsing the xml, I want to save the parsed data, so I define a Book Entity and define each attribute
package com.ikok.parsexml;
public class Book {
private String id;
private String name;
private String price;
private String author;
private String language;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPrice() {
return price;
}
public void setPrice(String price) {
this.price = price;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getLanguage() {
return language;
}
public void setLanguage(String language) {
this.language = language;
}
}
DOM parsing:
package com.ikok.parsexml;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class domXml {
private static List<Book> booksList = new ArrayList<Book>();
public static void main(String[] args) {
// Create a DocumentBuilderFactory object
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
try {
// Create a DocumentBuilder object
DocumentBuilder db = dbf.newDocumentBuilder();
// Load the xml file into the current project via the parse method of the DocumentBuilder object
Document document = db.parse("books.xml");
/ / Get a collection of all book nodes
NodeList bookList = document.getElementsByTagName("book");
// Traverse each book node and know the length of the collection via the bookList.getLength() method
System.out.println("a total" + bookList.getLength() + "book");
for (int i = 0; i < bookList.getLength(); i++) {
Book bookItem = new Book();
System.out.println("----------- Start traversing the first" + (i+1) + "The contents of this book ---------");
// Get a book node by the item(i) method, the index value of the NodeList starts from 0
Node book = bookList.item(i);
/ / Get all the property collection of the book node
NamedNodeMap attrs = book.getAttributes();
System.out.println(" " + (i+1) + "This book has " + attrs.getLength() + " attributes");
// traverse the properties of the book
for (int j = 0; j < attrs.getLength(); j++) {
// Get a property of a book node by the item(i) method
Node attr = attrs.item(j);
/ / Get the property name
System.out.print("property name:" + attr.getNodeName());
/ / Get the attribute value
System.out.println("----property value:" + attr.getNodeValue());
if(attr.getNodeName().equals("id")){
bookItem.setId(attr.getNodeValue());
}
}
// When you know that a node has one and only one attribute, perform a cast, and get the attribute value via the getAttribute() method.
// Element book = (Element) bookList.item(i);
// String attrValue = book.getAttribute("id");
// System.out.println("id :" + attrValue);
/ / Analyze the child nodes of the book node
NodeList childList = book.getChildNodes();
System.out.println(" " + (i+1) + "This book has " + childList.getLength() + " child nodes");
for (int k = 0; k < childList.getLength(); k++) {
/ / Distinguish between node type of text type and element type node
if (childList.item(k).getNodeType() == Node.ELEMENT_NODE) {
/ / Get the node name of the element type node
System.out.print(" " + (i+1) + " The child node name of the book: " + childList.item(k).getNodeName() + "----");
// If there are still nodes in the current node, the attribute value is null. For example, <name><a>aa</a><b>bb</b> first line of code</name>
System.out.println(" Property Value: " + childList.item(k).getFirstChild().getNodeValue());
// This will output the contents of all child nodes and nodes. Will output the first line of aabb code
// System.out.println(childList.item(k).getTextContent());
if(childList.item(k).getNodeName().equals("name")){
bookItem.setName(childList.item(k).getFirstChild().getNodeValue());
} else if(childList.item(k).getNodeName().equals("price")){
bookItem.setPrice(childList.item(k).getFirstChild().getNodeValue());
} else if(childList.item(k).getNodeName().equals("author")){
bookItem.setAuthor(childList.item(k).getFirstChild().getNodeValue());
} else if(childList.item(k).getNodeName().equals("language")){
bookItem.setLanguage(childList.item(k).getFirstChild().getNodeValue());
}
}
}
System.out.println("-----------End traversal" + (i+1) + "Content of the book -----------");
System.out.println();
booksList.add(bookItem);
bookItem = null;
}
for (Book item : booksList) {
System.out.println("book id :" + item.getId());
System.out.println("book name:" + item.getName());
System.out.println("book price:" + item.getPrice());
System.out.println("book author :" + item.getAuthor());
System.out.println("book language :" + item.getLanguage());
System.out.println("---------------------------------");
}
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
Result:
A total of 2 books
----------- Begin to traverse the contents of the first book -----------
Book 1 has 1 attribute
The attribute name is: id----The attribute value is: 1
Book 1 has 7 sub-nodes
The name of the child of the first book: name---- Attribute value: the beauty of programming
Subnode name of Book 1: price---- Attribute value: 34.0
The name of the child of the first book: author---- Attribute value: "The beauty of programming" group
----------- End the traversal of the contents of the first book -----------
----------- Begin to traverse the contents of the second book -----------
Book 2 has 1 attribute
The property name is: id----The attribute value is: 2
Book 2 has 9 child nodes
Subnode name of Book 2: name---- Attribute value: Ordinary world
Subnode name of Book 2: price---- Attribute value: 56.0
Subnode name of Book 2: author---- Attribute value: Lu Yao
Subnode name of Book 2: language---- Attribute value: Chinese
----------- End the traversal of the contents of the second book -----------
Book id :1
Book name: the beauty of programming
Book price: 34.0
Book author: "The Beauty of Programming" group
Book language :null
---------------------------------
Book id : 2
Book name: ordinary world
Book price: 56.0
Book author: Lu Yao
Book language : Chinese
---------------------------------
SAX parsing:
package com.ikok.parsexml;
import java.io.IOException;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.SAXException;
public class SAXXml {
public static void main(String[] args) {
// Create an instance of SAXParserFactory
SAXParserFactory saxpf = SAXParserFactory.newInstance();
try {
// Get an instance of SAXParser from an instance of SAXParserFactory
SAXParser parser = saxpf.newSAXParser();
SAXParserHandler handler = new SAXParserHandler();
parser.parse("books.xml", handler);
System.out.println("Total" + handler.getBookList().size() + "Book");
for (Book book : handler.getBookList()) {
System.out.println("book id :" + book.getId());
System.out.println("book name:" + book.getName());
System.out.println("book price:" + book.getPrice());
System.out.println("Book Author:" + book.getAuthor());
System.out.println("book language :" + book.getLanguage());
System.out.println("---------------------------------");
}
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
Because the SAX parsing xml parsing method requires a DefaultHandler parameter, I defined a SAXParserHandler to inherit this class, rewriting some methods
package com.ikok.parsexml;
import java.util.ArrayList;
import java.util.List;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SAXParserHandler extends DefaultHandler {
// The serial number of the book
int bookIndex = 0;
/**
* An attribute value
* Because the property name is obtained in the startElement() method, but the property value is obtained in the characters() method.
* In order to add the attribute name and attribute value to the book instance, the other two methods are executed before the endElement() method, so it is processed here.
*/
String value = null;
Book book = null;
private List<Book> bookList = new ArrayList<Book>();
public List<Book> getBookList() {
return bookList;
}
/ / used to traverse the start tag of the xml file
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
super.startElement(uri, localName, qName, attributes);
// Start parsing the attributes of the book element
if(qName.equals("book")){
// Create a book object
book = new Book();
bookIndex++;
System.out.println("----------- Start traversing the first" + bookIndex + "The contents of the book -----------");
// // Know the name of the attribute under the book element, get the attribute value based on the attribute name
// String value = attributes.getValue("id");
// System.out.println("id:" + value);
/ / Do not know the name and number of attributes under the book element, get the attribute name and attribute value
// number of attributes
int num = attributes.getLength();
for (int i = 0; i < num; i++) {
System.out.print(" " + (i+1) + "Attribute Name: " + attributes.getQName(i));
System.out.println(" Attribute Value: " + attributes.getValue(i));
if (attributes.getQName(i).equals("id")) {
book.setId(attributes.getValue(i));
}
}
} else if(!qName.equals("book") && !qName.equals("bookstore")){
System.out.print("node name:" + qName + "node value:");
}
};
/ / used to traverse the end tag of the xml file
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
super.endElement(uri, localName, qName);
// Whether the content of a book ends in traversal
if (qName.equals("book")) {
// empty the book to facilitate the next one
bookList.add(book);
book = null;
System.out.println("-----------End traversal" + bookIndex + "Content of the book -----------");
} else if(qName.equals("name")){
book.setName(value);
} else if(qName.equals("price")){
book.setPrice(value);
} else if(qName.equals("author")){
book.setAuthor(value);
} else if(qName.equals("language")){
book.setLanguage(value);
}
};
/ / used to mark the beginning of parsing
@Override
public void startDocument() throws SAXException {
// TODO Auto-generated method stub
super.startDocument();
System.out.println("SAX parsing starts");
}
/ / used to mark the end of parsing
@Override
public void endDocument() throws SAXException {
// TODO Auto-generated method stub
super.endDocument();
System.out.println("SAX parsing ends");
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
// TODO Auto-generated method stub
super.characters(ch, start, length);
/ / Get the attribute value
value = new String(ch, start, length);
// By default, the newline in xml will be counted, the output format is incorrect, and the newline is removed.
if (!value.trim().equals("")) {
System.out.println(value);
}
}
}
Result:
SAX analysis begins
----------- Begin to traverse the contents of the first book -----------
The first attribute name: id attribute value: 1
Node name: name Node value: the beauty of programming
Node name: price node value: 34.0
Node name: author node value: "Programming Beauty" group
----------- End the traversal of the contents of the first book -----------
----------- Begin to traverse the contents of the second book -----------
First attribute name: id attribute value: 2
Node name: name Node value: ordinary world
Node name: price node value: 56.0
Node name: author node value: Lu Yao
Node name: language node value: Chinese
----------- End the traversal of the contents of the second book -----------
End of SAX parsing
2 books in total
Book id :1
Book name: the beauty of programming
Book price: 34.0
Book author: "The Beauty of Programming" group
Book language :null
---------------------------------
Book id : 2
Book name: ordinary world
Book price: 56.0
Book author: Lu Yao
Book language : Chinese
---------------------------------
JDOM parsing:
--------- Start to analyze the first book -----------------
Attribute name: id----Attribute value: 1
Subnode name: name----child node attribute value: the beauty of programming
Subnode name: price----child node attribute value: 34.0
Subnode name: author----child node attribute value: "Programming Beauty" group
--------- End of the analysis of the first book -----------------
--------- Start to analyze the second book -----------------
Attribute name: id----Attribute value: 2
Subnode name: name----child node attribute value: ordinary world
Child node name: price----child node attribute value: 56.0
Subnode name: author----child node attribute value: Lu Yao
Subnode name: language----child node attribute value: Chinese
--------- End of the analysis of the second book -----------------
Book id :1
Book name: the beauty of programming
Book price: 34.0
Book author: "The Beauty of Programming" group
Book language :null
---------------------------------
Book id : 2
Book name: ordinary world
Book price: 56.0
Book author: Lu Yao
Book language : Chinese
---------------------------------
DOM4J parsing:
package com.ikok.parsexml;
import java.io.File;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class dom4jXml {
private static List<Book> bookList = new ArrayList<Book>();
// The serial number of the book
static int bookIndex = 0;
public static void main(String[] args) {
// Create an SAXReader object
SAXReader reader = new SAXReader();
try {
/ / Load the xml file through the reader's read () method, get the document object
Document document = reader.read(new File("books.xml"));
/ / Get the root node
Element rootElement = document.getRootElement();
// Get the iterator
Iterator iterator = rootElement.elementIterator();
// Traverse the iterator to get the information in the root node
while (iterator.hasNext()) {
bookIndex++;
Book bookItem = new Book();
System.out.println("---------- start traversing the first" + bookIndex + "book ------------");
Element book = (Element) iterator.next();
/ / Get the property name and property value
List<Attribute> attrList = book.attributes();
for (Attribute attr : attrList) {
if(attr.getName().equals("id")){
bookItem.setId(attr.getValue());
}
System.out.println("property name:" + attr.getName() + "----property value: " + attr.getValue());
}
Iterator it = book.elementIterator();
while (it.hasNext()) {
Element element = (Element) it.next();
if(element.getName().equals("name")){
bookItem.setName(element.getStringValue());
} else if(element.getName().equals("price")){
bookItem.setPrice(element.getStringValue());
} else if(element.getName().equals("author")){
bookItem.setAuthor(element.getStringValue());
} else if(element.getName().equals("language")){
bookItem.setLanguage(element.getStringValue());
}
System.out.println("Subnode Name:" + element.getName() + "----Subnode Property Value:" + element.getStringValue());
}
System.out.println("----------End traversal" + bookIndex + "Book ------------");
bookList.add(bookItem);
bookItem = null;
}
for (Book item : bookList) {
System.out.println("book id :" + item.getId());
System.out.println("book name:" + item.getName());
System.out.println("book price:" + item.getPrice());
System.out.println("book author :" + item.getAuthor());
System.out.println("book language :" + item.getLanguage());
System.out.println("---------------------------------");
}
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
Results:
---------- Start traversing the first book ------------
Attribute name: id----Attribute value: 1
Subnode name: name----child node attribute value: the beauty of programming
Subnode name: price----child node attribute value: 34.0
Subnode name: author----child node attribute value: "Programming Beauty" group
---------- End traversing the first book ------------
---------- Start traversing the second book ------------
Attribute name: id----Attribute value: 2
Subnode name: name----child node attribute value: ordinary world
Child node name: price----child node attribute value: 56.0
Subnode name: author----child node attribute value: Lu Yao
Subnode name: language----child node attribute value: Chinese
---------- End traversing the second book ------------
Book id :1
Book name: the beauty of programming
Book price: 34.0
Book author: "The Beauty of Programming" group
Book language :null
---------------------------------
Book id : 2
Book name: ordinary world
Book price: 56.0
Book author: Lu Yao
Book language : Chinese
---------------------------------
Here, JDOM I use the 2.0.5 package, DOM4J I use the 1.6.1 package.
With the current XML as the target of analysis, the analysis takes time, the SAX takes less time than the DOM, and the DOM4J takes less time than the JDOM.
Currently, the DOM4J parsing XML is also used in the hibernate framework.Intelligent Recommendation

XML analysis (SAX, DOM, JDOM, DOM4J)
content 1, interview questions: 2, DOM4J parsing XML file 3, XPath Analysis XML file 1, interview questions: ask: JavaThere are severalXMLAnalytical way? What is it?? What kind of advantages and disad...
Java Foundation Series 17: Using DOM, SAX, JDOM, DOM4J to parse XML files
Introduction In Java, there are several ways to parse XML files, the most common of which is probablyDOM、SAX、JDOM、DOM4JThese four ways. Among them, DOM and SAX are two methods for parsing XML files. T...
Java parsing xml, parsing xml four methods, DOM, SAX, JDOM, DOM4j, XPath
【introduction】 At present, there are many techniques for parsing XML in Java. The mainstream ones are DOM, SAX, JDOM, and DOM4j. The following mainly introduces the use, advantages, disadvantages, and...
(Reprinted) Java four operations (DOM, SAX, JDOM, DOM4J) xml way to explain and compare
Original link: Keywords: operation xml (dom, sax, jdom, dom4j) way to compare 1. Detailed 1) DOM (JAXP Crimson parser) DOM is the official W3C standard for representing XML documents in a platform- an...
java in four operations (DOM, SAX, JDOM, DOM4J) xml manner as in Comparative Detailed
1. Detailed 1) DOM (JAXP Crimson parser) DOM is an official W3C standard XML document with language and platform-independent way. DOM is a collection of nodes or pieces of information organized hierar...
More Recommendation
Four kinds parser (dom, sax, jdom, dom4j) principle and performance XML Comparison
Four kinds parser (dom, sax, jdom, dom4j) principle and performance XML Comparison XML parsing Configuring the internal xml file after parsing can be used to implement some of the features of the fram...
Four kinds of XML parsing dom, sax, jdom, dom4j principle and performance comparison
XML: four parsers (dom, sax, jdom, dom4j) principle and performance comparison Dom is one of the underlying interfaces for parsing xml (the other is sax). And jdom and dom4j are more advan...
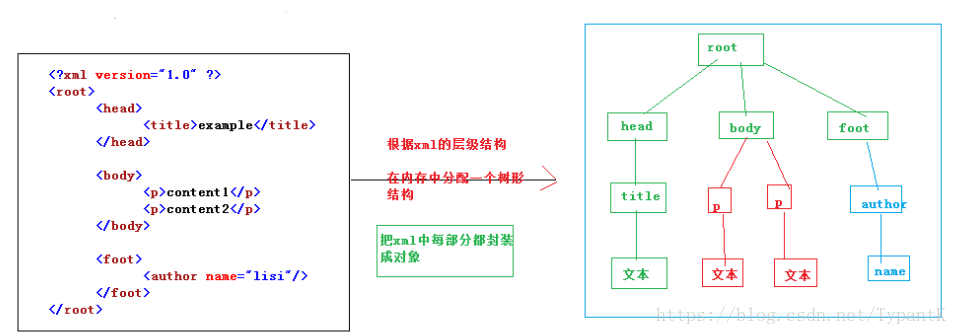
[XML] XML parsing method (dom+sax) and parser (dom4j+jaxp+jdom)
1.xml parsing method (technical): dom and sax >>dom way to parse: Allocate a tree structure in memory according to the hierarchical structure of xml, and encapsulate the tags, attributes and tex...
DOM, SAX, DOM4J, JDOM, StAX generate an XML string and returns XML
used herein, DOM, SAX, DOM4J, JDOM and in JDK1.6 StAX generate new XML data format, and returns an XML string. Said here about StAX way. New features JDK6 of StAX (JSR 173) API JDK6.0 is in addition t...
DOM4J and JDOM parse XML
DOM4J parsing: JDOM parsing: Generate an XML file:...