Reading Pytorch source code AlexNet
tags: Deep Learning
Under the Windows operating system, the model path is: C:\Python35\Lib\site-packages\torchvision\models\xxnet.py, there are many definitions of commonly used network structures, including AlexNet, ResNet, Inception, DenseNet, etc. For our direct use:
from torchvision import models
model = models.alexnet(pretrained=False)Now start reading the AlexNet source code:
First import the necessary packages, and then define the __all__ variable. This function is used to minimize the damage to the namespace, because from xx import xx will copy all the variables out, and the importer can get the part beyond what it needs (maybe (It will overwrite the variable name of the variable defined by the importer). When there is a ____all__ list, only the variable name in the list will be copied out. This is contrary to the _X convention: __all__ indicates the name of the variable to be copied, and _X indicates the name of the variable that cannot be copied. Python will look for the __all__ list in the model. If it is not defined, then from xx import xx will copy out all variable names without an underscore at the beginning.
model_urls defines a dictionary whose key is the model name (structure) and the value is the download address of the corresponding pre-trained model parameters.
import torch
import torch.nn as nn
from .utils import load_state_dict_from_url
__all__ = ['AlexNet', 'alexnet']
model_urls = {
'alexnet': 'https://download.pytorch.org/models/alexnet-owt-4df8aa71.pth',
}Next is the AlexNet class, inherited from torch.nn.Module, which is the parent class of all neural network modules.
First define the initialization __init__ method, the parameter num_classes is a few categories, the default is 1000 classes of ImageNet.
At the beginning, super(AlexNet, self).__init__() uses the initialization method of the parent class to initialize the subclass. The source code of nn.Module is as follows:
class Module(object):
dump_patches = False
_version = 1
def __init__(self):
"""
Initializes internal Module state, shared by both nn.Module and ScriptModule.
"""
torch._C._log_api_usage_once("python.nn_module")
self.training = True
self._parameters = OrderedDict()
self._buffers = OrderedDict()
self._backward_hooks = OrderedDict()
self._forward_hooks = OrderedDict()
self._forward_pre_hooks = OrderedDict()
self._state_dict_hooks = OrderedDict()
self._load_state_dict_pre_hooks = OrderedDict()
self._modules = OrderedDict()Then define the structure of the convolutional neural network: a number of conv+maxpooling and then the classic way of connecting 3 FC layers, except that the first convolutional layer has a step size of 4, the remaining convolutional layer steps are all 1, and use " same" padding, and all maxpooling filter_size is 3. AdaptiveAvgPool2d is an adaptive average pooling. This method can calculate kernel_size=(input_size+target_size-1) // target_size according to the target_size and input_size of the parameter, the number of output channels remains unchanged, and the size becomes the target_size set by the parameter . The last is the fully connected layer, p=0.5 Dropout.
Next is the forward method, which defines the calculations performed at each call (the flow of x between layers), torch.flatten(x, 1) flattens all feature maps through the AdaptiveAvgPool2d layer, and then connects to the FC layer.
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return xFinally, define the alexnet method for others to use. The pretrained parameter determines whether to load the pre-trained model. The progress parameter determines whether to display the download progress bar. **kwargs is only valid for keyword parameters. For example, you can enter num_classes=10.
def alexnet(pretrained=False, progress=True, **kwargs):
r"""AlexNet model architecture from the
`"One weird trick..." <https://arxiv.org/abs/1404.5997>`_ paper.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
model = AlexNet(**kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls['alexnet'],
progress=progress)
model.load_state_dict(state_dict)
return modelFinally, when inputting the images of (3, 227, 227), the output size and parameters after each layer of the model:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 56, 56] 23,296
ReLU-2 [-1, 64, 56, 56] 0
MaxPool2d-3 [-1, 64, 27, 27] 0
Conv2d-4 [-1, 192, 27, 27] 307,392
ReLU-5 [-1, 192, 27, 27] 0
MaxPool2d-6 [-1, 192, 13, 13] 0
Conv2d-7 [-1, 384, 13, 13] 663,936
ReLU-8 [-1, 384, 13, 13] 0
Conv2d-9 [-1, 256, 13, 13] 884,992
ReLU-10 [-1, 256, 13, 13] 0
Conv2d-11 [-1, 256, 13, 13] 590,080
ReLU-12 [-1, 256, 13, 13] 0
MaxPool2d-13 [-1, 256, 6, 6] 0
AdaptiveAvgPool2d-14 [-1, 256, 6, 6] 0
Dropout-15 [-1, 9216] 0
Linear-16 [-1, 4096] 37,752,832
ReLU-17 [-1, 4096] 0
Dropout-18 [-1, 4096] 0
Linear-19 [-1, 4096] 16,781,312
ReLU-20 [-1, 4096] 0
Linear-21 [-1, 1000] 4,097,000
================================================================
Total params: 61,100,840
Trainable params: 61,100,840
Non-trainable params: 0
----------------------------------------------------------------
Intelligent Recommendation
Intensive reading of PSENet-pytorch source code (1)
Intensive reading of PSENet-pytorch source code PSENet's network structure PSENet's network structure PSENet is implemented on the basis of FPN, using ResNet as the backbone network. First, obtain fou...
Pytorch interface source code reading notes (1)
Foreword:I have used Tensorflow for a long time, and I feel that it is really uncomfortable. Although the function is very powerful, it is very troublesome to debug, and the API is mixed with several ...
FCN-Pytorch implementation source code reading notes
Code reference Github:https://github.com/wkentaro/pytorch-fcn 1. _fast_hist params: label_true represents the label, label_pred represents the predicted value, and n_class represents the number of pix...
Mask rcnn pytorch source code reading analysisOne
About build_rpn_targets function analysis Here input all the generated anchors (about 60,000), gt_class_ids label the grand truth class ids and its corresponding bbox. 1, if there is no occlusion crow...
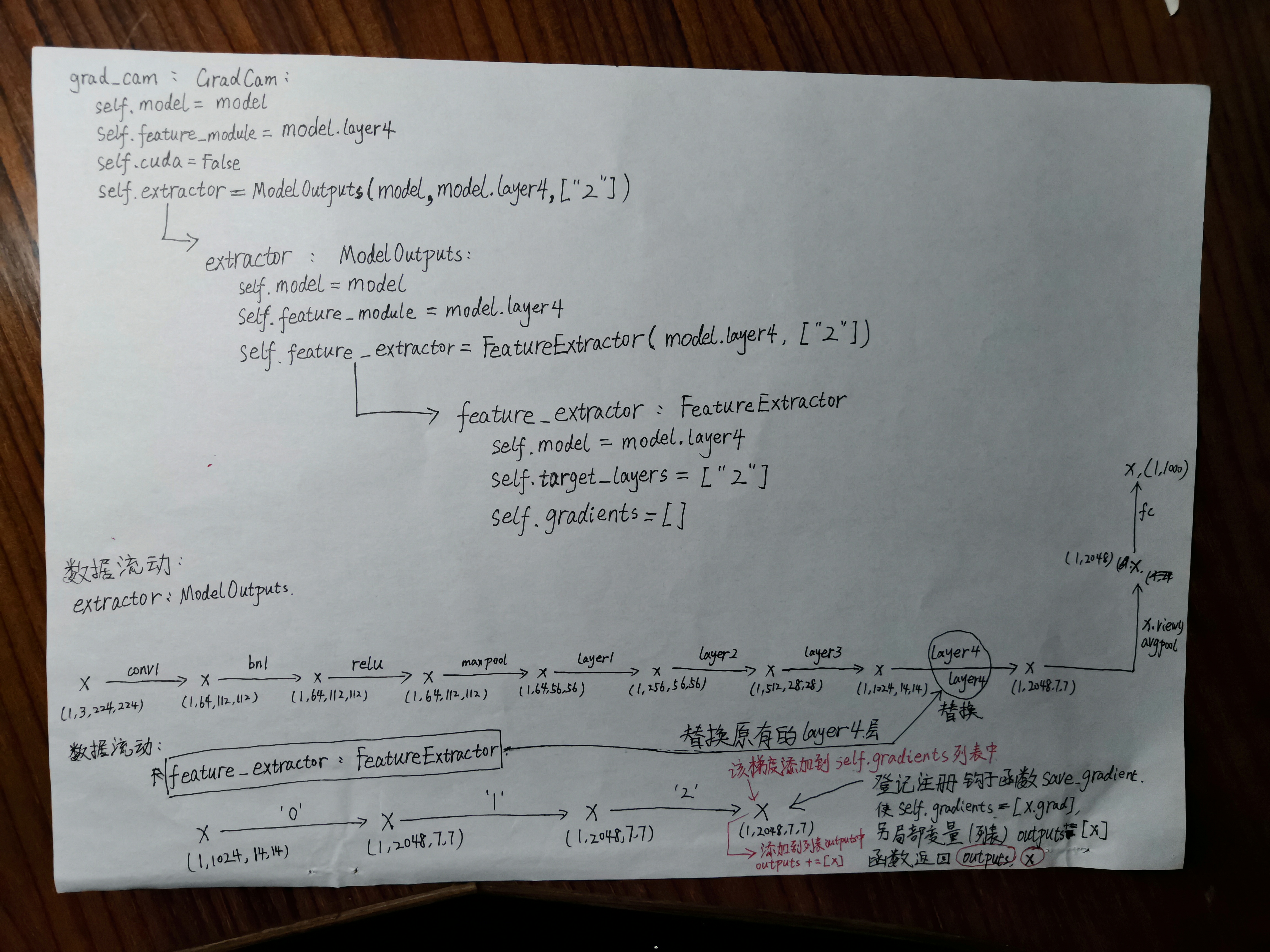
Pytorch-grad-cam source code reading and debugging
Source code link: jacobgil/pytorch-grad-cam Algorithm hand drawing display: Code Experiment Display (Detailed note): Running Effect Screenshot Display (Enter the command under CMD: python gradcam.py -...
More Recommendation
Pytorch-yolvv3 source code reading - DataSet
Official source code:https://github.com/eriklindernoren/PyTorch-YOLOv3 ...
Text-Classification-Models-Pytorch Source Code Reading
https://github.com/AnubhavGupta3377/Text-Classification-Models-Pytorch Article catalog Model_TextCNN Model_CharCNN Model_TextRNN Model_TextCNN Words using glove vector Word vector that dimension is th...
Pytorch TTA (predictive enhancement) source code reading
Pytorch TTA Source Code Reading 1.ttach/wrappers.py TTA mainly called interface Inherited pytorch's nn.module 1.1 Merger 1.2 Compose 1.2.1 BaseTransform 1.2.2 Transformer 1.2.4 Chain In fact, the main...
Pytorch version TTA source code reading 2
TTA Source Code Read 2 1. Transforms.py Mainly the file of the picture enhancement method First of all, it is, it's here that Transform's class inheritsDualTransformAnd this class is completely inheri...
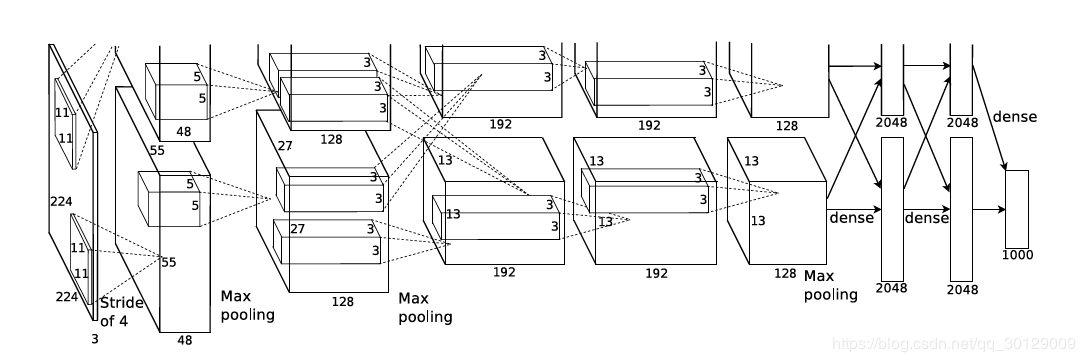
AlexNet network structure analysis and pytorch code
This paper was published in 2012. The model AlexNet in the article participated in the competition ImageNet LSVRC-2010. The ImageNet dataset has 1.2 million high-resolution images and a total of 1,000...