Sudoku
Sudoku
Personal Projects for the Software Engineering Foundation Course in the Fall of 2018

Sudoku final generation and solver, runs on the Windows platform and is developed in C++.
Github project address:https://github.com/lytning98/sudoku
Article directory
- Sudoku
- First, the PSP form
- Second, the topic analysis and problem solving ideas
- Third, design, implementation brief and unit test design
- Fourth, the project improvement process
- Code quality analysis
- 2. Performance analysis and improvement
- 2.1 Bitset implementation issues
- 2.2 C++ STL is too slow
- 2.3 Spin Waiting to Consume CPU Resource Problems
- 3. Concurrency control issues and improvements
- V. Partial implementation of the specific code description
- Instructions and appendices
First, the PSP form
| PSP2.1 | Personal Software Process Stages | Estimated time (minutes) | Actual time (minutes) |
|---|---|---|---|
| Planning | plan | 10 | 5 |
| - Esitimate | Estimated mission time | 10 | 5 |
| Development | Development | 1,065 | 1,170 |
| - Analysis | demand analysis | 45 | 30 |
| - Design Spec | Generate design documents | 40 | 40 |
| - Design Review | Design review | 20 | 10 |
| - Coding Standard | Code specification | 20 | 20 |
| - Design | Specific design | 180 | 200 |
| - Coding | Specific coding | 600 | 750 |
| - Code Review | Code review | 60 | 40 |
| - Test | Testing (self-testing, modifying code, submitting changes) | 100 | 80 |
| Reporting | report | 240 | 400 |
| - Test Report | testing report | 30 | 20 |
| - Size Measurement | Calculation workload | 20 | 25 |
| - Postmortem & Process Improvement Plan | Summary and propose process improvement plan | 190 | 355 |
| total | 1,315 | 1,575 |
Second, the topic analysis and problem solving ideas
This question requires the realization of a Sudoku finalizer and Sudoku problem solving program. The requirements are more clearly divided into two parts: the final generation and the problem solving, which can be considered, designed and implemented separately.
Final generation
Sudoku end office refers to a filled number ~ of The board meets every number in each row, every column, and every nine squares. A typical Sudoku board is shown in the figure, and the thick solid line marks the boundary of the Jiugong grid.
This question requires the program to generate at most
The end of the Sudoku.

Due to the nature of Sudoku, the numbers in each line must form a 1~9 arrangement, so it is easy to think of using a permutation to generate a Sudoku final.
Take any one of the arrangements first Fill in the first line of Sudoku. Then observe the second line. In order to meet the requirement that each number on each column only appears once, the second line should be the first line.Misaligned arrangementFor the sake of simplicity, you can simply do the first lineCyclic movementTo get some typical misalignment.
Here we remember Loop left shift The bit is obtained as ,Such as Time, .
Next, try to fill in each line with a circular arrangement to get the final Sudoku. In order to meet the restrictions within the same nine-square grid, the three rows belonging to the same nine-square grid, in any two rows, the difference between the following table must be A multiple of the line, otherwise another line in the nine squares will conflict with the two lines. Therefore, the second and third lines can only be filled in. with , as shown in the table below.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|
| 4 | 5 | 6 | 7 | 8 | 9 | 1 | 2 | 3 |
| 7 | 8 | 9 | 1 | 2 | 3 | 4 | 5 | 6 |
Try on the fourth line
~
,Find
Always legal, if
Fill in the fourth line, then the 4th to 6th lines will be similar to the first three lines. Similarly, the process is applied to lines 7-9, which can be arranged by the original
The resulting Sudoku final is as follows
Since the upper left corner of the board is a fixed number generated by the student number, it is arranged.
Only
Kind. Further observation can be found that the arrangement in the three rows belonging to the same nine-square grid (such as rows 4-6) is only guaranteed to be subscripted.
Congruence, the internal order can be arbitrarily changed. If the internal order of lines 4-6 and 7~9 is re-distorted for the above-mentioned final situation, the final number can be expanded to
Kind, can already meet the requirements.
2. Sudoku solution
The Sudoku solution is given a partially ended Sudoku final, filled in with numbers in all blanks to return to the legal end.
Since the constraints of Sudoku itself are very strong, and there are only three orders in this scenario, this task is very suitable for the depth-first search algorithm with pruning. The algorithm will scan each blank and try each number that can be filled in. When there is no number to fill in a position, the prune returns, and when a blank is filled, a set of solutions is found.
Under the strong restriction condition of the third-order Sudoku, the algorithm can greatly narrow the search range every time a number is tried, and the algorithm has a simple structure, which can start and end the search quickly and flexibly without excessive preparation work, and the efficiency is excellent. .
Third, design, implementation brief and unit test design
The design implementation of this project will explain the two relatively independent modules separately.
Due to the low complexity of the project, the content of this chapter combines the summary design with the detailed design and gives it directly together. At the same time, because the designed process is relatively simple and straightforward, the following content is combined with a certain brief implementation description. .
The unit tests for this project are performed using the MSTest test tool that comes with Microsoft Visual Studio. The test case descriptions for each unit are also given in the corresponding sections below. The implementation of the test case is locatedUnitTest\UnitTest.cpp In the file.
Final generation
This part of the implementation is locatedconsole\generator.cpp In the file.
The way to generate the final is described in the previous chapter, mainly by shifting the arrangement. Since the demand is only made for the final end of the SudokuNot repeatingThe requirements are not required to be random, so the final sequence generated in this program is fixed.
This part of the algorithm is relatively simple and straightforward, mainly through the following functions.
generator::step_forward() // Enumerate the arrangement required for the final game
generator::generate() // Generate a set of finals using the enumerated arrangement
generator::print() // Write the final file to the file
The details of each function will be described below.
1.1 Generate a set of finals based on the permutation
This part of the function is in the functiongenerator::generate Implemented in .
According to the generation method described in the previous chapter, the first step in generating the final line needs to enumerate the numbers in the first line.
With alignment
After that, as shown in the previous chapter
Generate a final Sudoku:
To increase the final number, generate the final game
You will also need to enumerate all the rows between rows 4-6 and 7~9. This can enumerate two arrays of length 3 by using a similar method.
Realize, for example when
When the representative rearranges the finals of lines 4-6
,among them
Representative of $L(P_0) $
Row.
unit test: A test case was designed for the unit: the legality of the generated finality, including the row, column, nine-grid conflict and digital range check. Corresponding to the test methodGeneratorTest::GeneratorConflictionTest 。
1.2 enumeration arrangement
This part of the function is in the functiongenerator::step_forward Implemented in .
Individually arranged enumerations can pass C++ STL functionsstd::next_permutation to fulfill. Here you need to enumerate three permutations at the same time.
The combined state can be enumerated by the following strategy.

This process is executed once, and the combined state of the three permutations is stepped once.
unit test The test of the unit contains three test cases, and all three branches in the process are tested, mainly to compare the state changes of the three arrays before and after enumeration of the next state. The corresponding test method isGeneratorTest::EnumerationTest1 Wait for three methods.
2. Sudoku solution
This part of the implementation is locatedconsole\solver.cpp Andconsole\solver.hpp In the file.
The Sudoku solution process repeats the process of “reading the topic—solving the problem—writing the answer into the file”, which is a process of Depth First Search (DFS, the same below).
In order to speed up the process of determining which numbers have been used in DFS, the project also needs to implement an easybitset Class, its function with C++ STLstd::bitset Similar, used to encapsulate operations on binary bits. The binary bits used in this program are only about 10 bits, so implementing the class yourself rather than directly using the STL class library can speed up.
Because when the number of topic groups is large, the number of questions is small, or the difficulty is low, the DFS solution consumes less time. Instead, it takes more time to write the solution to the file, which is easy to become a bottleneck. Therefore, the program needs to adopt multi-threading. In this way, the main thread is used to solve Sudoku, and the second thread is used for file IO operations.
The above three sections are separately described below.
2.1 Bitset class
Realized inconsole\solver.hpp middle solver::bitset class.
This class mainly encapsulates the operation of binary bits, including setting the specified bit position to “0”, setting “1”, querying the status of the specified bit, clearing the bit, and so on.
solver::bitset::set(int p); // will specify the bit position "1"
solver::bitset::erase(int p); // will specify the bit position "0"
solver::bitset::test(int p); / / Query the status of the specified bit
solver::bitset::reset(); // all bits are cleared
Since the number of bits operated in this program is only 10 bits, the data of each bit is one.int Variable storage.
Each operation is realized by an AND, OR, XOR, orbital operation to increase the speed.
unit test The test for this unit contains three test cases, and each function of the class is tested for correctness. Related test methods are locatedUnitTest::SolverBitsetTest In the class.
2.2 DFS
This part of the function is in the namespacesolver::DFS Implemented in .
Before starting the search, the program needs to first calculate all the numbers that can be filled in each position in the given situation as the candidate answer.
When solving Sudoku, the program will traverse the entire board from the upper left corner. For each position where the number is not filled, the candidate answers calculated in advance by the position will be tried in turn. If there is no conflict with the current rank and the state of the nine squares, The number at this position is drawn to the current selection and continues to traverse the board.
If the entire board is traversed, it means that a combination solution is found, and the search process ends; if a position cannot be filled in any number, the current answer is partially wrong, the program will backtrack from the current position and cancel the proposed answer. , repeat the search process after changing to other candidates.
When searching, it is judged whether it conflicts with the ranks and the nine grids. It is implemented by the Bitset class described in the previous section, which is more efficient and saves memory space than Boolean arrays.
unit test : This unit sets up two test cases. Test Methods SolverTest::SolverInitTest A set of Sudoku topics was used as the test data, and the initialization process of DFS initialization was called to pre-process it, and the correctness of the pre-processing was checked, including whether the Bitset was correctly set, whether the fill-in position was determined accurately, etc.;SolverTest::SolverAnswerTest The complete search and solve process was completed, and the correctness of the answer obtained by the solution was tested, including the legality of the filled in numbers and the consistency of the final answer with the title given to the endgame.
2.3 Multithreading and IO
This part of the function is mainly in the namespacesolver::IO Implemented in .
The implementation related to multithreading and concurrency control in this program mainly uses C++11.std::thread class.
In the Sudoku solution process, the main thread is responsible for solving Sudoku and sending the answer to the IO buffer queue. The second thread continuously fetches data from the IO buffer queue and writes the answer to the specified file. The queue is Space-time spin waiting.
IO buffer queue using C++ STLstd::queue achieve.
Note:std::queue It is not thread-safe, so this method causes a series of thread concurrency problems; spin wait also causes a certain amount of CPU computing resources to be wasted. Therefore, the final multi-threaded IO solution of the program has improved the concurrency control. For details, see Chapter 4.
On IO, the project adoptedfputc with fputs Equal functionfprintf Implementation, which improves overall efficiency, which is several times slower than the former due to the need to perform complex operations such as parsing format strings.
unit test : This unit sets up a test case, that is, the test methodSolverTest::ThreadTestThis method detects whether a thread that implements asynchronous IO can start and exit normally.
Fourth, the project improvement process
Code quality analysis
The project uses the C/C++ code quality analysis tool included with Visual Studio 2017 for code analysis. The amount of project code is not very large, and the warning results given by the code analysis are not very large, mainly due to the warning given by the Chinese encoding problem, the file encoding can be solved.
2. Performance analysis and improvement
After the first version of the project was completed, it was analyzed using the performance analysis and diagnostic tools provided with Visual Studio. Some problems were found and improved in order to improve the performance of the program.
2.1 Bitset implementation issues
The following exceptions were found in the CPU usage analysis results of the initial version of the project:

solver::dfs Is a function to implement the search, it is normal to have high CPU time; butsolver::bitset::erase The CPU time is obviously abnormal. Samesolver::bitset Class bit manipulation function,solver::bitset::set Even the CPU time of the function is not even
And the latter's number of calls in the search process is almost the same as the former, so the specific implementation of the former is further reviewed:
void erase(int p){
assert(p >= 1 && p <= 9);
if(value & masks[p])
value ^= masks[p];
}
It can be seen that in order to eliminate the "0" on a binary bit, the function first performs an operation and determines whether the bit is "1". If it is 1, an exclusive OR operation is used to eliminate the "1" on the bit. In contrastset The function only performs a bitwise OR operation, so it can be basically concluded that the efficiency is slowed down due to the extra judgment branch and the one-bit operation, and the efficiency of the XOR operation may not be as good as the hardware friendly operation or operation. Since the number of calls to this function in the DFS process can reach tens of thousands or even billions of times, this defect is infinitely magnified, seriously slowing down the overall speed of the program.
After optimizing the function by some means (mainly constructing a constant bit mask), the concrete implementation is as follows:
void erase(int p){
assert(p >= 1 && p <= 9);
value &= erase_mask[p];
}
After optimization, performance analysis is performed again, and the CPU time of the function is suddenly reduced. Below, the performance of the program has also been improved.

2.2 C++ STL is too slow
The performance analysis also found that the CPU time occupied by the classes and functions in the C++ STL (Standard Template Library) of the program is also very high, as shown in the following figure.

C++ STL is used in some places in the programstd::vector To reduce the complexity of the code, although not using high-complexity library functions, it slows down the program.
After consulting the relevant information, the performance of the STL class can be improved by turning on compiler optimization. Turn on O2 optimization in the Set Compiler option (ie add\O2 After compiling the instructions, the efficiency of the STL class and the efficiency of the entire program have been greatly improved. The performance analysis is shown in the figure below.

2.3 Spin Waiting to Consume CPU Resource Problems
When the initial version of the program uses multithreading for IO, the wait strategy used is spin wait (busy, etc.), even if the thread is always in the loop and polling the detection buffer for data to be output. Such a strategy makes the second thread occupy the CPU for calculation for a long time. Although it may not affect the running speed of the main thread when running on a multi-core machine, it is easy to consume the computing resources of the machine, which is not a good waiting strategy. On a single-core machine, it will even compete with the main thread for CPU resources to make meaningless polling.
This phenomenon is also reflected in the performance analysis. As shown in the following figure, when the CPU time of the program is displayed by the thread, the CPU time occupied by the main thread and the second thread is flat, even though the CPU of the main thread actually consumes more. It can be seen that the busy polling of the second thread consumes a lot of meaningless CPU resources.

After discovering the problem, the project finally used the concurrency control related library function in C++11 to change the spin wait to blocking wait, that is, wait without consuming CPU resources, and the thread is passive when adding new data to the buffer. Wake up instead of actively querying.
This improvement is mainly passedstd::condition_variable Implementation, which is a condition variable class implemented in the C++ standard library, which can be passedwait Function causes the thread to wait for blocking and passnotify_all Wait for the function to wake up the thread in the block.
The improved performance analysis results are shown in the figure below. It can be seen that the CPU time of each thread of the improved program is no longer an even distribution, but is allocated on demand. The simpler the Sudoku problem, the shorter the DFS take-up time, and the shorter the CPU time occupied by the main thread.

3. Concurrency control issues and improvements
Because the class libraries in C++ STL are not thread-safe, and are used in programs.std::queue At the same time, the two threads perform read and write operations. In the actual multi-thread concurrent operation, there is a probability of a series of thread conflicts, causing the program to crash and exit.
In order to solve the concurrency control problem, the project introduced some new concurrency control libraries in C++11, includingstd::mutex with std::unique_lock , mainly used to lock critical resources to ensure that the operation of the STL container is mutually exclusive;std::condition_variable Implement blocking waits to avoid a lot of CPU resources, such as busy.
The specific implementation of this part is detailed in Section 3.2 of Chapter 5.
V. Partial implementation of the specific code description
This chapter will explain some of the key codes.
Final generation
The arrangement enumeration corresponds to Section 1.2 of Chapter 3, which is a simple coding of the program flow chart. The code is relatively simple and straightforward, and the flow chart of the program is easier to understand.
void step_forward(int* p, int shift[3][3]) {
using namespace std;
if (!next_permutation(shift[2], shift[2] + 3)) {
if (!next_permutation(shift[1], shift[1] + 3)) {
next_permutation(p + 1, p + 9);
memcpy(p + 10, p + 1, sizeof(int) * 8);
for (int i = 0; i < 3; i++)
shift[1][i] = shift[2][i] = i;
}
for (int i = 0; i < 3; i++)
shift[2][i] = i;
}
}
step_forward Each time the function is executed, it will makep[] with shift[][] The combined arrangement state changes once and is called
Within the second time, it is guaranteed that the new state generated each time is not repeated. The specific principle is as described in Section 2 of Chapter 2.
According to the enumerated state, a set of finals can be generated, and the final state generated by the different arrangement states is different, thereby ensuring that the program can generate More than the above data.
The code fragment that generates the final according to the arrangement is as follows, according top[] The arrangement in the row determines the relative order of the numbers in each row, and according to the row andshift[][] The alignment in the row determines the offset of the alignment in each row, as described in Section 2 of Chapter 2.
int offset = 0;
for (int i = 0; i < 3; i++)
for (int j = 0; j < 3; j++) {
memcpy(map[i * 3 + shift[i][j]], p + offset, sizeof(int) * 9);
if (j == 2)
offset = (offset + 1) % 9;
else
offset = (offset + 3) % 9;
}
This part of the code is in the functiongenerator::generate() in.
2. DFS process
The DFS search in this program is implemented using the normal recursive method. The following is a key part of the code snippet.
for (int i : valid[x][y]) / / Loop through all the numbers that can be filled in
{
// If the number is not currently in the row, column, or square
if (!(row_bit[x].test(i) || col_bit[y].test(i) || cell_bit[cell_id].test(i)))
{
// fill the number in the current location
map[x][y] = i;
// Mark the number in the row, column, and nine grids.
row_bit[x].set(i);
col_bit[y].set(i);
cell_bit[cell_id].set(i);
// Continue to search for the next location, exit if a solution is found
if (dfs(x, y + 1))
return true;
// If the solution is not found, the undo operation continues to try the next number
row_bit[x].erase(i);
col_bit[y].erase(i);
cell_bit[cell_id].erase(i);
}
}
This part of the code is in the functionsolver::DFS::dfs in.
3. Multi-threaded IO and concurrency control
3.1 Mutual exclusion protection
As mentioned above,std::queue It is not thread-safe, so multi-threaded concurrent operations require locking to ensure mutual exclusion. This project mainly uses the C++11 concurrency control library to complete related operations.
The code fragment that sends the solved Sudoku finalization to the IO queue is as shown in the following figure: (For the convenience of the display, the actual code has been modified and omitted, the same below):
void push_queue() {
// ...
// use mutex lock for critical section
std::unique_lock<std::mutex> lk(qMutex);
Q.push(store);
}
Take the code snippet of the queue data:
while (going) {
std::unique_lock<std::mutex> lk(qMutex);
// ...
while (!Q.empty()) {
// fetch data from IO queue
int* store = Q.front(); Q.pop();
// ...
}
}
among them std::unique_lock Guaranteed possession during its life cycleqMutex Mutex, the latter isstd::mutex Type, only at the same time can be occupied by a program.
The above two pieces of code are located separatelysolver::IO::push_queue with solver::IO::write_result in.
3.2 blocking waiting
C++ conditional variable class introduced by the projectstd::condition_variable Effectively solve the problem of spin waiting to consume CPU resources, its use is mainly divided into two parts, the first part is calledwait The function is waiting for the thread to wait. This project is used to wait for the main thread to add data to the IO queue, as shown in the following code snippet:
while (going) {
std::unique_lock<std::mutex> lk(qMutex);
// wait and block
cond_var.wait(lk);
while (!Q.empty()) {
// fetch data and do something...
}
}
The second part is callednotify_all The function sends a message to all threads blocking on the current condition variable, waking up the process blocked by the condition variable. This function is called after the main thread adds new data to the queue in the project, as shown in the following code snippet:
void push_queue() {
// ...
std::unique_lock<std::mutex> lk(qMutex);
Q.push(store);
// notify the second thread for new data
cond_var.notify_all();
}
The above two pieces of code are located separatelysolver::IO::write_result with solver::IO::push_queue In the function.
3. Multi-threaded IO logic
When the main thread starts, the following function will be called (locatedsolver::IO Namespaces):
inline void start_IO(FILE* fout) {
IO_thread = new std::thread(write_result, fout);
going = true;
}
This function starts the IO thread and willsolver::IO::going The variable is set totrue , on behalf of Sudoku solution has not been completed, there will be new data generated. IO thread atsolver::IO::going Fortrue The process of "blocking wait, wake up, processing data, and continuing to block wait" is repeated cyclically, where "wake up" occurs when the main thread resolves a new set of Sudoku and adds data to the IO queue.
When the main thread solves all the problems, the following function will be called (locatedsolver::IO Namespaces):
inline void join_IO() {
going = false;
cond_var.notify_all();
// wait until IO finishes
IO_thread -> join();
}
Calling an IO threadstd::thread::join() The function, similar to the effect of merging the main thread with the child thread, the main thread will block and wait for the child thread to complete execution. Before this, the function willsolver::IO::going Set as false And callednotify_all The function is to wake up the child thread and cause the child thread to finish processing the data directly, instead of blocking the wait again.
Instructions and appendices
1. Description of test branch coverage
The community version of Visual Studio does not provide detection of code branch coverage, only available in the Enterprise Edition; at the same time Visual Studio's NUnit, XUnit and other plug-ins are test tools developed for the .NET Framework, not for C++ projects; and common units for C++ projects. Test tools (such as lcov, gcov) run under Linux and cannot test Windows projects; the Studio Profiling Tools mentioned in the job description document are used to monitor the performance of resources such as CPU and network and data transfer. And analysis tools, not related to unit testing; the remaining plug-ins or tools have very little documentation and high learning costs. Therefore, the project ultimately did not detect the branch coverage of the unit test case.
Intelligent Recommendation
Scala's implicit conversion function (10)
Implicit conversion function Definition: declare with implicit keyword Role: Enrich the functions of existing class libraries and enhance class methods...
Remember the MySQL-CDC read multi-table diversion, etc.
This time is an experimental operation. The Flink version is 1.13.3, the MySQL-CDC version is 2.0.2, and the MySQL version is 8.0.25. Step 1: Use CDC to read the two tables in the library. One detail ...
Ubuntu mounted disk
First check the disk information lsblk It can be seen that SDA3 under SDA is now mounted under / DATA1, and other disks under SDA have not been mounted in Ubuntu. Temporary mount (restart will cancel ...
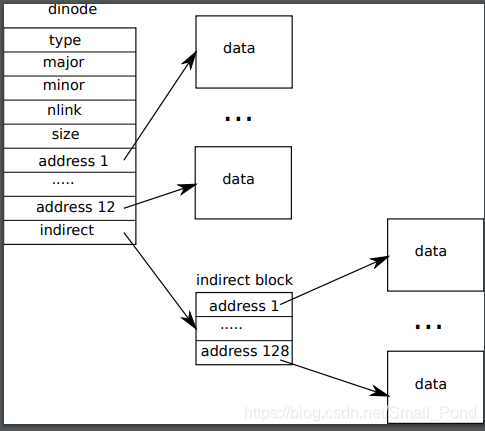
MIT6.828_HW10_Bigger file for xv6
MIT6.828_HW10_Bigger file for xv6 The current xv6 file size is limited to 140 sectors. There are 12 direct index nodes, and a first-level index node, which points to a sector, which can contain 512/4 ...
More Recommendation
Vue project Vue + restfulframework
Vue project Vue + restfulframework Login achieve certification - django views setting urls - Vue Installation package cnpm install --save axios vuex npm install vue-cookie --save route.js store.js mai...
Hadoop2.10.0 environment construction (single-machine pseudo-distribution)
Hadoop2.10.0 environment construction (single-machine pseudo-distribution) First prepare a virtual machine with centos7, and then download and install it. Download Hadoop and configure jdk Let’s...
[Android] ADB common command
Android adb common command ADB Start Activity: $ adb shell am start -n {package (package) name} / {activity (Activity) name} Such as: start the browser adb shell am start -n com.android.browser/com.an...
Built a web cluster using Haproxy + Nginx
Haproxy is currently a popular cluster scheduling tool, in the same cluster scheduling tool, comparison with LVS, the performance of LVS, but the relatively complex, NGINX's UPSTREAM module supports c...
Python finds all the combinations of m in an array
According to this algorithm, it is rewritten as Python code."Improved, find N numbers from one array, and all possible" Python code is as follows operation result: It is running very slow, a...