Deep learning algorithm | LSTM algorithm principle introduction and Tutorial
December 23-24

The text contains 4880 words and 17 pictures, and the estimated reading time is 13 minutes.

LSTM (Long Short-Term Memory) algorithm is a kind of deep learning method. Before introducing the LSTM algorithm, it is necessary to introduce some basic backgrounds of deep learning.
At present, in the field of machine learning, the biggest hot spot is undoubtedly deep learning, from the Google Brain (Google Brain) cat face recognition, to the victory of the Deep Convolutional Neural Network in the ImageNet competition, and then to the victory of Alphago Li Shishi. The media, scholars and related researchers are more and more popular. The reason behind this is nothing more than the effect of deep learning methods indeed surpassing the traditional machine learning methods.
Since the Geoffrey E. Hinton team won the deep learning method in the ImageNet competition (one of the most influential competitions in image recognition) in 2012, the research on deep learning has been blown out; before 2012, the The accuracy of the game results has been slowly improving. This year, there was a sudden qualitative fly-by. Since then, deep learning methods have become the only choice in the ImageNet competition.
At the same time, the impact of deep learning is not only limited to image recognition competitions, but also profoundly affects academia and industry. There are more and more researches on deep learning in top academic conferences, such as CVPR, ICML, etc. It has made contributions to deep learning and contributed more and more computing support or frameworks, such as Nivdia's cuda, cuDnn, Google's tensorflow, Facebook's torch and Microsoft's DMTK, etc.
Behind the development of deep learning technology is the contribution of researchers. The most famous researchers in this field are Yoshua Bengio, Geoffrey E. Hinton, Yann LeCun and Andrew Ng. Recently, Yoshua Bengio and others published "Deep Learning", which made a systematic discussion on the historical development of deep learning and the main technologies in the field. Its summary of the historical development trend of deep learning is very insightful. Several key points of the historical development trend of deep learning are:
a) Deep learning itself has a rich and long history, but there are many different names from different perspectives, so its popularity has decayed in history.
b) As the amount of training data that can be used gradually increases, the application space of deep learning is bound to become larger and larger.
c) With the improvement of computer hardware and deep learning software infrastructure, the scale of deep learning models is bound to increase.
d) As time goes by, the accuracy of deep learning to solve complex applications is bound to be higher and higher。
The history of deep learning can be roughly divided into three stages. One is from the 1940s to the 1960s, when deep learning was called cybernetics; the second was from the 1980s to the 1990s, during which deep learning was hailed as connected learning; and the third was from 2006. Learning the name began to recover (the starting point was in 2006, Geoffrey Hinton found that deep belief networks can be effectively trained through a layer-by-layer greedy pre-training strategy).
All in all, deep learning, as a method of machine learning, has made great strides in the past few decades. With the improvement of basic computing architecture performance, larger data sets and better optimization training techniques, it is foreseeable that deep learning will definitely achieve more results in the near future.

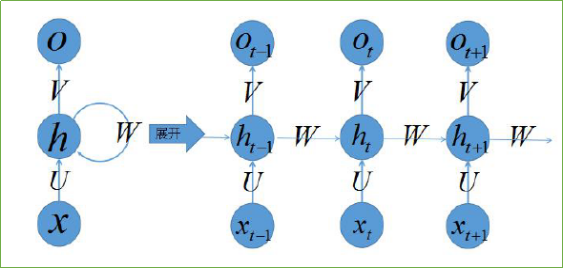
The LSTM algorithm is called Long short-term memory. It was first proposed by Sepp Hochreiter and Jürgen Schmidhuber in 1997 [6]. It is a specific form of RNN (Recurrent neural network, recurrent neural network), and RNN is a series of capable of processing sequences. Generic term for neural networks of data. Here we should pay attention to the difference between recurrent neural network and recursive neural network (Recursive neural network).
Generally, RNN contains the following three characteristics:
a) The recurrent neural network can produce an output at each time node, and the connection between hidden units is cyclic;
b) The recurrent neural network can produce an output at each time node, and the output on the time node is only cyclically connected to the hidden unit of the next time node;
c) The cyclic neural network contains hidden units with cyclic connections, and can process sequence data and output a single prediction.
There are many variations of RNN, such as bidirectional RNN (Bidirectional RNN). However, RNN will encounter huge difficulties when dealing with long-term dependencies (nodes that are far away in time series), because calculating the connection between nodes that are far away will involve multiple multiplications of the Jacobian matrix, which will The problem of gradient disappearance (which often occurs) or gradient expansion (rarely occurs) is observed by many scholars and studied independently。
To solve this problem, researchers have proposed many solutions, such as ESN (Echo State Network), adding leaky units (Leaky Units) and so on. Among them, the most widely used is the threshold RNN (Gated RNN), and LSTM is the most famous one among the threshold RNN. Leaky cells allow the RNN to accumulate long-term connections between nodes at greater distances by designing the weight coefficients between connections; the threshold RNN generalizes this idea, allows the coefficient to be changed at different times, and allows the network to forget that it has accumulated Information.
LSTM is such a threshold RNN, and its single node structure is shown in Figure 1 below. The ingenious point of LSTM is that by increasing the input threshold, forgetting the threshold and outputting the threshold, the weight of the self-loop is changed, so that when the model parameters are fixed, the integration scale at different times can be dynamically changed, thereby avoiding the gradient The problem of disappearance or gradient expansion.

Figure 1 CELL diagram of LSTM
According to the structure of the LSTM network, the calculation formula of each LSTM unit is shown in Figure 2, where Ft represents the forget threshold, It represents the input threshold, ̃Ct represents the cell state at the previous moment, and Ct represents the cell state (here is where the loop occurs) , Ot represents the output threshold, Ht represents the output of the current unit, and Ht-1 represents the output of the unit at the previous time.

Figure 2 LSTM calculation formula
After introducing the principles of the LSTM algorithm, it is natural to understand how to train the LSTM network. Similar to the feedforward neural network, the LSTM network training also uses the error back propagation algorithm (BP), but because LSTM processes sequence data, it is necessary to propagate the error over the entire time series when using BP . LSTM itself can be expressed as a graph structure with cycles, which means that when back propagation is used on this graph with cycles, we call it BPTT (back-propagation through time).
Below we explain the calculation process of BPTT through Figure 3 and Figure 4. As can be seen from the structure of LSTM in Figure 3, the current cell state will be affected by the state of the previous cell, which reflects the recurrent characteristics of LSTM. At the same time, in the calculation of error back propagation, it can be found that the error of h (t) includes not only the error of the current time T, but also the error of all times after the time T, that is, the meaning of back-propagation through time. Both errors can be calculated iteratively via h (t) and c (t + 1).

Figure 3 Schematic diagram of LSTM network
In order to visually represent the entire calculation process, based on the reference neural network calculation diagram, the calculation diagram of LSTM is shown in Figure 4. From the calculation diagram, the forward propagation and back propagation processes of LSTM can be clearly seen. As shown in the figure, the error of H (t-1) is determined by H (t), and the gradients propagated back from all gate layers are to be summed, c (t-1) is determined by c (t), and c (t) The error consists of two parts, one part is h (t) and the other part is c (t + 1). Therefore, when calculating the back propagation error of c (t), h (t) and c (t + 1) need to be passed in, and h (t) needs to be added when updating (h + 1). In this way, the gradient at any time can be calculated backward from time T, and the weight coefficient can be updated by stochastic gradient descent.

Figure 4 Schematic diagram of BPTT
There are many variations of the LSTM algorithm, the most important of which are two, as follows:
a)GRU
Among the variants of the LSTM algorithm, GRU (Gated Recurrent Unit) is the most widely used one, which was first proposed by Cho et al. In 2014 [7]. The difference between GRU and LSTM is that the same threshold is used to replace the input threshold and the forget threshold. That is, the state of the cell is controlled by an "update" threshold. The advantage of this approach is that the calculation is simplified, and the model's expressive power is also very strong, so GRU has become more and more popular.
b)Peephole LSTM
Peephole LSTM was proposed by Gers and Schmidhuber in 2000 [8]. The meaning of Peephole is to allow the current threshold Gate to "see" the state of the cell at the previous moment, so that it needs to be added when calculating the input threshold, forgetting the threshold and outputting the threshold. The variable representing the state of the cell at the previous moment. At the same time, some other Peephole LSTM variants will allow different thresholds to "see" the state of the cell at the previous moment.
Different researchers have proposed many improvements to LSTM, but there is no specific type of LSTM that can achieve the best results on some specific tasks due to other variants on any task. For more LSTM algorithm improvements, please refer to Chapter 10.10 in the book "Deep Learning".
This article reviews the background and reasons for the birth of the LSTM algorithm, analyzes the details of using BPTT in the LSTM network training process, and introduces the application of the LSTM algorithm in *. Judging from the performance of the current model after it goes online, the performance of the LSTM algorithm surpasses the traditional algorithms (SVM, RF, GBDT, etc.), and it also proves the power of deep learning from the side, which is worth exploring by algorithm students. Admittedly, deep learning is an all-encompassing field of machine learning. The above understanding is just some personal experience and experience. If there are any lapses, it is inevitable. Students who are interested in deep learning are welcome to discuss and improve together.
This article mainly refers to the following information, thank you very much:
a)Understanding LSTM Networks,http://colah.github.io/posts/2015-08-Understanding-LSTMs/;
b)Deep Learning,Ian Goodfellow Yoshua Bengio and Aaron Courville,Book in preparation for MIT Press,2016;
c)Simple LSTM,http://nicodjimenez.github.io/2014/08/08/lstm.html。
GIHUB address: https://github.com/xuanyuansen/scalaLSTM
【1】https://googleblog.blogspot.com/2012/06/using-large-scale-brain-simulations-for.html;
【2】http://image-net.org/challenges/LSVRC/2012/supervision.pdf;
【3】https://en.wikipedia.org/wiki/AlphaGo;https://deepmind.com/research/alphago/;http://sports.sina.com.cn/go/2016-09-13/doc-ifxvukhx4979709.shtml;
【4】https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf;
【5】http://www.deeplearningbook.org/;
【6】http://www.mitpressjournals.org/doi/abs/10.1162/neco.1997.9.8.1735#.V9fMNZN95TY;
【7】http://arxiv.org/pdf/1406.1078v3.pdf;【8】ftp://ftp.idsia.ch/pub/juergen/TimeCount-IJCNN2000.pdf.
Original link: http://blog.csdn.net/xuanyuansen/article/details/61913886
For more concise and convenient classified articles and the latest courses and product information, please move to the newly presented "LeadAI Academy Official Website"
www.leadai.org
Please pay attention to the artificial intelligence LeadAI public number, see more professional articles

Everyone is watching

Application of LSTM model in question answering system
Neural network based on TensorFlow solves the problem of user churn overview
The most common algorithm engineer interview questions finishing (1)
The most common algorithm engineer interview questions finishing (2)
TensorFlow from 1 to 2 | Chapter 3 The beginning of the deep learning revolution: Convolutional Neural Networks
Decorator | Advanced Python Programming
Today it is better to review the basics of Python


Click "Read Original" to open the registration link directly
Intelligent Recommendation
Deep learning--recurrent neural network--LSTM / GRU algorithm theory
table of Contents A recursive neural network foundation 1 The connection and difference between recurrent neural network and feedforward neural network 1) Network structure 2) Input angle 3) Output an...
Deep learning ---- Using the LSTM algorithm to predict transformer casing temperature
1, summary I would like to use Julia's FLUX depth learning framework, but the support of FLUX for time series data analysis is not too good, I have to use Keras + Tensorflow. There is no stacked LSTM ...

Deep learning algorithm Q-learning principle
Q-learning Q-learning is a value-based method. In this method, instead of training a policy, we need to train a critic network. The critic does not take actions directly, but evaluates the quality of ...
Principle of neural network algorithm for deep learning
Principle of neural network algorithm for deep learning What is a neural network algorithm? Junior high school mapping Neural network seeking mapping? Solving parameters Graphical request references W...

The principle of LSTM (variant RNN) of tensorflow deep learning
inDescription of tensorflow deep learning cycle calculation layer and cycle calculation process (super detailed)In, we have learned the principle of traditional recurrent network RNN. Disadvantages of...
More Recommendation
Combining the Stanford Deep Learning Tutorial for the Derivation Process of the BP Back Propagation Algorithm Principle
Recently, during the learning of the Convolutional Neural Network (CNN), I found that my previous understanding of the backpropagation algorithm was not thorough enough. So today I wrote a blog to rec...
GRPC python package deep learning algorithm tutorial
Recently, I need to provide a python code containing multiple neural network inferences for gRPC to call, that is, I need to encapsulate a server that supports gRPC on the basis of this main program. ...
Introduction to Deep Learning - Simple Implementation of BP Algorithm
Foreword The process of algorithm implementation, I feel the process of translating the mathematical derivation formula into code. The introduction of detailed algorithm ideas has been written in the ...
Introduction and installation of python tensorflow deep learning algorithm
About Tenso Flow Tenso Flow is an open source learning library for programming based on data flow, TensorFlow. It was originally developed by researchers and engineers from the Google Brain Group (par...

Based on deep learning - introduction of YoLov5 algorithm
1. YoLov5 image recognition technology Introduction to Yolov5 image recognition technology YOLOv5 is a single-stage target detection algorithm. The algorithm adds some new improvement ideas based on Y...