OCR text recognition, that is, STR scene text detection network model development overview
With the development of deep learning, many end-to-end models have emerged in the field of computer vision, and image and scene text detection and recognition models have also had a long-term development on this basis.
1. Basic network framework
In the field of CV, the basis of image recognition and detection is feature extraction. Classic image classification models includeVGGNet,ResNet、InceptionNet(GoogleNet)、DenseNet、Inside-Outside Net、Se-NetThese networks can be used as a basic network (universal network model) to extract features from input images.
(1) FCN network: Fully convolutional network, Fully convolution network, good at extracting detailed features of images
Fully convolutional network is a basic network that does not make the fc fully connected layer, and was originally used for semantic segmentation. A
Features: de-convolution, up-pooling, sub-pixel convolutional layer and other means for upsampling operations to restore the feature matrix.
The pixel resolution of the last feature map of the FCN network is high. In scene text recognition, it is necessary to rely on clear text strokes to distinguish different characters (especially Chinese characters). The FCN network is very suitable for extracting text features on pictures. When FCN is used for text recognition, each pixel of the last feature map is divided into two categories: text lines (foreground) and non-text lines (background).
(2) STN network: Spatial Transformer Networks, Spatial Transformer Networks, good at doing graphic correction
The input feature map is spatially corrected to obtain the output feature map, which will not be expanded in detail here.
2. Detection network framework
The detection network can be divided into one-stage and two-stage methods according to the training process, and can be divided into anchor-based and anchor-free methods according to whether the anchor is needed.
(1) Faster RCNN network-two-stage:
The RPN network looks for the proposal suggestion box, ROI pooling generates normalized fixed-size region features for multiple size reference boxes, classifies, and returns the network.
Loss function: multi-objective loss function, RPN classification (background and foreground), regression loss function, final classification (type) and coordinate regression loss.
Optimization goal: Through loss back propagation, adjust the coordinates of the candidate box, and increase and label the IOU of the object bbox.
(2) SSD network -One stage
The full name of SSD is Single Shot MultiBox Detector, which was proposed in 2016 and is a fully convolution target detection algorithm.
Features: Multi-scale fusion, anchors are generated on feature maps of different scales, classification and regression are performed, and the maximum result of NMS suppression is obtained.
(3)YoloV3 - One stage
(4)CenterNet - anchor free
3. Text detection model
Purpose: To accurately find out the area of the text in the picture.
Existing problems: Direct application of general methods of target detection such as Faster RCNN series, SSD series, Yolo series, etc., the text detection effect is not good.
Reasons: (1) Large aspect ratio: Compared with conventional target detection objects, the length of the text detection line is large and the aspect ratio range is large.
(2) The text line is directional: the description of the regular object bbox quaternion (x, y, w, h) or (x1, y1, x2, y2) is insufficient.
(3) Natural scenes are complex. For example, some local images are similar to the shape of letters, so you need to refer to the global information of the images to avoid false alarms.
(4) The text line is curved, and there are many handwriting font change modes.
(5) There is much background interference.
Direction of improvement: In recent years, many methods based on deep learning have been proposed. From the perspective of feature extraction, regional recommendation network (RPN), multi-objective collaborative training, Loss improvement, non-maximum suppression (NMS), semi-supervised learning, etc., the conventional object detection method is modified, which greatly improves the text in natural scene images The accuracy of detection.
ways to improve:
(1) CTPN: Use the BLSTM module to extract the contextual features of the image where the characters are located to improve the recognition accuracy of the text block.
(2) In the RRPN and other schemes, the text box labeling adopts the form of BBOX + direction angle value, and a rotatable text area candidate box is generated in the model, which is found in the frame regression calculation process The tilt angle of the line of text to be tested.
(3) In programs such as DMPNet, use quadrilateral (non-rectangular) to mark the text box to more compactly surround the text area.
(4) SegLink cuts the word into small blocks of text that are easier to detect, and then predicts the adjacent connections to connect the small blocks of text into words.
(5) In TextBoxes and other solutions, the length-width ratio of the reference frame of the text area is adjusted, and the feature layer convolution kernel is adjusted to a rectangle, which is more suitable for detecting elongated text Row.
(6) In the FTSN scheme, the author uses Mask-NMS instead of the traditional BBOX NMS algorithm to filter candidate boxes.
(7) In the WordSup scheme, a semi-supervised learning strategy is adopted, and word-level annotation data is used to train a character-level text detection model.
4. Text detection (detection) representative model details
(1) CTPN model Detecting Text in Natural Image with Connectionist Text Proposal Network
At present, the most widely spread and most influential open source text detection model can detect horizontal or slightly inclined text lines.
Front end: VGG16 is used as a backbone to extract partial image features of characters
In the middle: BLSTM extracts the context features of the character sequence
Back-end: FC fully connected layer, which outputs the bbox coordinate value of each text block and the probability value (confidence level) of the classification result through the prediction branch.
Data post-processing: merge adjacent small text blocks into text lines.
(2) RRPN model Arbitrary-Oriented Scene Text Detection via Rotation Proposals
RRPN, Rotation Region Proposal Networks scheme based on rotating region candidate network.
The text line rotation factor (angle tilt) is embedded in the regional candidate network, such as Faster RCNN.
Label: The ground truth of the text area is (x, y, w, h, θ) rotating border, and (x, y) is the center of the text box.
Training: First generate a slanted box containing the text direction angle; bbox regression to learn the text direction angle.
Innovation: Propose RROI, rotate the region of interest pooling layer, divide the region in any direction into sub-regions, then do max pooling on these sub-regions, and project the results onto a small feature map with a fixed spatial size.
(3) FTSN model Fused Text Segmentation Networks for Multi-oriented Scene Text Detection
The FTSN (Fused Text Segmentation Networks) model uses segmentation networks to support skewed text detection.
Backbone: ResNet-101, multi-scale fusion
Tags: text area bbox, pixel mask
Training: Joint training of pixel prediction and border prediction multi-target.
Innovative point: Propose Mask-NMS, based on pixel-level coincidence between text instances, instead of traditional NMS method based on bbox coincidence.
(4) DMPNet model Deep Matching Prior Network: Toward Tighter Multi-oriented Text Detection
DMPNet (Deep Matching Prior Network) uses a quadrilateral (non-rectangular) to mark the boundary of the text area more compactly, and it is better for detecting oblique text blocks.
① The creation of anchor: text area proposal, in addition to squares, and inclined quadrilaterals.
Monte-Carlo method based on pixel sampling: quickly calculate the area coincidence between the quadrilateral candidate frame and the labeled frame
③ Calculate the distance between the coordinates of the four vertices and the center point of the quadrangle, and compare them with the labeled values to calculate the target loss. Recommended in the articleLn loss?To replace L1, L2 loss, so that the size of the text box has a faster training regression (regress) speed.
(5) EAST model An Efficient and Accurate Scene Text Detector
Multi-scale fusion, pixel-level text block prediction
Tags: support two types, rotating rectangular frame (x, y, w, h, θ) and arbitrary quadrilateral
Training: For rotating rectangular frame labels, the distance to the four sides of the rectangular frame and the direction angle of the rectangular frame are predicted for each pixel in the feature map during training.
For quadrilateral annotation, the difference in coordinates to four vertices is predicted for each pixel in the feature map during training.
According to the test of the pre-training model in the open source project, the model has a good effect on detecting English words and a poor effect on detecting long lines of Chinese text. Perhaps, after targeted training based on the characteristics of Chinese data, there is room for improvement in the detection effect.
(6) Seglink model Detecting Oriented Text in Natural Images by Linking Segments
First, each word is cut into more directional small text segments that are easier to detect, and then each small text block is connected into a word with a neighboring link.
(7) Pixel Link model Detecting Scene Text via Instance Segmentation
FCN fully convolutional network, backbone VGG16.
First, two pixel-level predictions are performed with the help of the CNN module: a text binary classification prediction and a link binary classification prediction. Next, the positive links are used to connect the neighboring positive text pixels to obtain the segmentation result of the text block instance. Then, the frame of the text block is directly obtained from the segmentation result, and it is allowed to generate the inclined frame.
(8) Textboxes / Textboxes ++ model TextBoxes: A Fast Text Detector with a Single Deep Neural Network
TextBoxes++: A Single-Shot Oriented Scene Text Detector
Textboxes are based on SSD, end-to-end and fast.
Use the initial value of anchor with a large aspect ratio; strip-shaped convolution kernels instead of common square convolution kernels; add candidate boxes in the vertical direction to prevent missed text lines; parallel prediction of text boxes on multi-scale feature maps to detect different Character blocks of large or small size; NMS filtering.
Textboxes ++ is an upgraded version of Textboxes, the purpose is to add support for slanted text.
Annotation: The original text box annotation method is changed to rotating rectangular frame and irregular quadrilateral.
Make adjustments to set the anchor aspect ratio and the convolution kernel shape of the feature map.
(9) WordSup model WordSup: Exploiting Word Annotations for Character based Text Detection
There are problems: in the application of mathematical formulas and text recognition, irregular deformation text line recognition and other applications, the character-level detection model is a key basic module. Due to the high cost of character-level natural scene image labeling and the scarcity of related public data sets, most current image and text detection models can only train on text line and word-level labeling data.
Solution: WordSup proposes a weakly supervised training framework that can train character-level detection models on text line and word-level annotation data sets.
5. Text recognition (Rcognition) model
Goal: Recognize text content from the segmented text area
(1) CRNN model An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
CRNN, Convolutional Recurrent Neural Network, is currently a more popular text recognition model.
Features: CNN feature extraction layer, BLSTM sequence feature extraction layer, end-to-end joint training, BLSTM and CTC to learn the contextual relationship in character images.
(2) RARE model Robust Scene Text Recognition with Automatic Rectification
It works well when identifying distorted image text.
In model prediction, the input image is first sent to a spatial transformation network for processing, and the corrected image is then sent to the sequence recognition network to obtain the text prediction result.
6. End-to-end end-to-end model
Train a network and complete text detection and recognition at the same time, Detection + Recognition
(1)FOTS Rotation-Sensitive Regression:FOTS: Fast Oriented Text Spotting with a Unified Network
Detection and recognition of shared convolutional feature layers; introduction of rotating objects of interest in RROI (ROIRotate); directional text regions can be generated from convolutional feature maps, supporting tilt text line detection recognition.
(2) STN-OCR model STN-OCR: A single Neural Network for Text Detection and Text Recognition
In its detection part, a spatial transformation network (STN) is embedded to perform affine transformation on the original input image. Using this spatial transformation network, image correction actions such as rotation, zooming, and tilting can be performed on the detected multiple text blocks, respectively, thereby obtaining better recognition accuracy in the subsequent text recognition stage. STN-OCR is a semi-supervised learning method in training. It only needs to provide text content annotation, and does not require text positioning information. The author also mentioned that if you start training from the beginning, the network convergence speed is slow, so it is recommended to gradually increase the training difficulty. STN-OCR has opened the engineering source code and pre-training model.
reference:
Intelligent Recommendation
For plain text text recognition (ocr), no text detection is required at all
As long as the horizontal line of the text is the same as the horizontal line of the picture when the screenshot is taken...
OCR text recognition tutorial series 1: CRNN text detection and recognition
title: OCR text recognition tutorial series 1: CRNN text detection and recognition date: 2020-07-17 15:11:37 category: Default category This article introduces OCR text recognition tutorial series 1: ...
OCR in the Wild: SOTA for text detection and recognition
Click on "AI Park" above, follow the official account, and choose to add "star" or "top" Author: Noé Compile: ronghuaiyang Guide I reviewed 3 papers in the field o...
[OpenCV] Text recognition detection based on Tesseract-OCR
[OpenCV] Text recognition detection based on Tesseract-OCR...
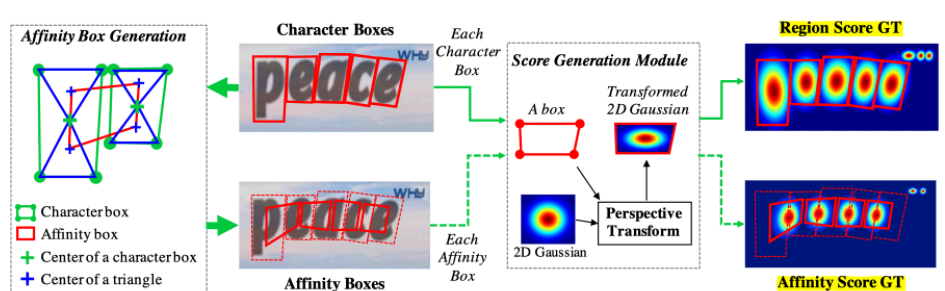
Design of STR skeleton information text recognition model
In the process of text recognition, because Chinese characters have skeleton information (radical radicals), I think that the detection-related algorithms for face recognition can better solve the abo...
More Recommendation
Survey natural scene text detection and recognition
forward from Green Snake special episode: sister, image text detection and identification of areas of what is now the hot topic? White Snake: black and white scanned document recognition technology ha...

A Summary of Natural Scene Text Detection and Recognition Technology
Fanwai Green Snake: Sister, what is the current research hotspot in the field of image text detection and recognition? White Snake: The scanning document recognition technology of white and black char...
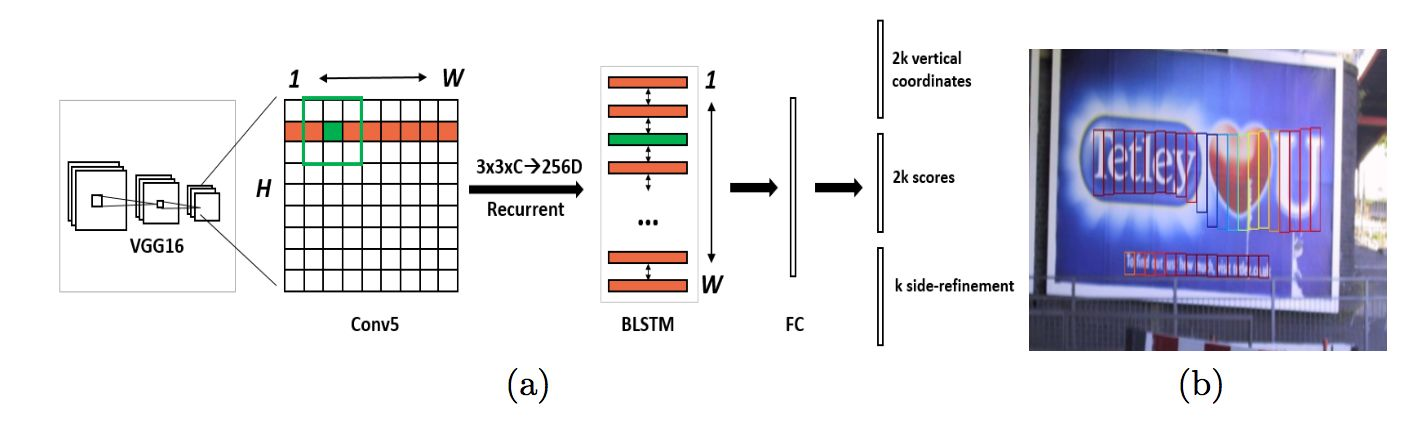
OCR text detection algorithm - CTPN model
Introduction: CTPN is a text detection algorithm proposed in ECCV 2016, which is currently currently transmitted, and the maximum open source text detection model can detect a horizontal or microarchi...

Android Baidu OCR text recognition development summary
Recently, I often go to Xiamen City Library to read books, and I still prefer to read paper books. Although the functions of e-book search, labeling, sharing, etc. are very convenient, there are sever...
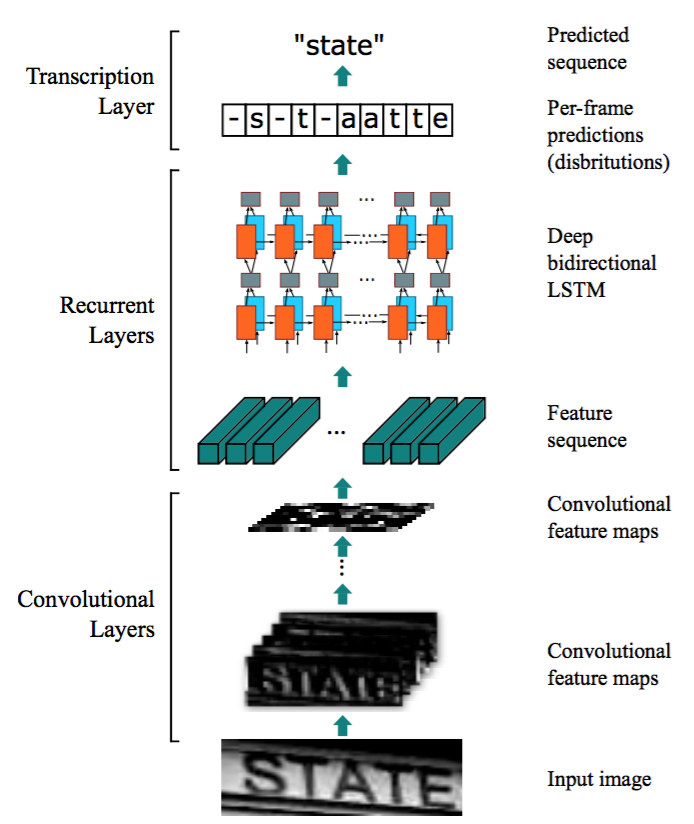
CTPN / CRNN an OCR text recognition natural scene understanding (II)
CRNN 1) end-to-trainable (CNN and the RNN joint training) 2) (image width of any arbitrary length, arbitrary word length) 3) there is no need to calibrate the training set of characters 4) with a dict...