A Summary of Natural Scene Text Detection and Recognition Technology
tags: OCR Machine learning artificial intelligence SIGAI

Fanwai Green Snake: Sister, what is the current research hotspot in the field of image text detection and recognition?
White Snake: The scanning document recognition technology of white and black characters is very mature, but the effect of text recognition of natural scene images is not satisfactory. The technical difficulties faced by landing applications such as slanted characters, artistic characters, distorted characters, ambiguous characters, shape-like characters, incomplete characters, shadowing, and multi-language mixed text have not yet been completely solved.
Green Snake: Why is VGG16 selected as the basic network in the text detection model CTPN?
White Snake: CTPN was launched in 2016, and VGG16 was the popular basic network for feature extraction that year. If you implement text detection this year, you can try Resnet, FCN, Densenet and other rising stars as the basic network, maybe there are surprises.
SummaryThis article introduces the latest technological developments in the field of image text recognition (OCR). First introduce the application background, including the technical challenges faced, typical application scenarios, system implementation framework, etc. Next, we introduce the various feature extraction basic networks and object detection network frameworks that are often cited in the process of building graphic recognition models, and the scene adaptation problems they face when they are applied to graphic recognition tasks. Then introduce the various text frame detection models, text content recognition models, and end-to-end graphic recognition models that have appeared in the past three years. Finally, a large public data set in the field of graphic recognition is introduced.
Application Overview
OCR (Optical Character Recognition, optical character recognition) traditionally refers to analyzing and processing the input scanned document image to identify the text information in the image. Scene text recognition (Scene Text Recognition, STR) refers to the recognition of text information in pictures of natural scenes. The character recognition in the natural scene image is much more difficult than the character recognition in the scanned document image, because its text display form is extremely rich:
·Allows multiple languages and texts to be mixed, characters can have different sizes, fonts, colors, brightness, contrast, etc.
·Text lines may have horizontal, vertical, curved, rotated, twisted and other styles.
· The text area in the image may also be deformed (perspective, affine transformation), incomplete, blurred, etc.
·The background of natural scene images is extremely diverse. For example, the text can appear on a flat surface, a curved surface, or a wrinkled surface; there is a complex interference texture near the text area, or a texture similar to the text in the non-text area, such as sand, grass, fence, brick wall, etc.Some people also use OCR technology to refer to all image text detection and recognition technologies, including traditional OCR technology and scene text recognition technology. This is because the scene text recognition technology can be regarded as the natural evolution and upgrading of the traditional OCR technology.
Image text detection and recognition technology has a wide range of application scenarios. Related applications that have been landed by Internet companies involve identifying business cards, identifying menus, identifying couriers, identifying ID cards, identifying business cards, identifying bank cards, identifying license plates, identifying street signs, identifying product packaging bags, identifying conference whiteboards, identifying advertising backbones Words, identification test papers, identification documents, etc.
Many service providers are already providing image text detection and recognition services. These service providers include not only large cloud service enterprises such as Tencent, Baidu, Ali, Microsoft, Amazon, Google, but also some active in logistics, education, security, Service companies in vertical subdivision industries such as live video, e-government, e-commerce, and travel navigation. These companies can use the pre-trained model to directly provide cloud services such as scene graphic recognition, card identification, scanned document recognition, etc., or they can use the data sets provided by customers to train customized models (such as bill recognition models) and provide customization. AI service system integration, etc.
As shown in the following figure, in the traditional technical solution, two models of text detection and text recognition are trained separately, and then these two models are connected to the data pipeline in the service implementation stage to form a graphic recognition system.
As shown in the figure below, in a recent popular technical solution, an end-to-end model is directly trained with a multi-objective network. In the training stage, the input of the model is the training image and the text coordinates and text content in the figure, and the model optimization goal is the weighted sum of the prediction error of the output frame coordinates and the text content prediction error. In the service implementation stage, the original picture flows through the model and directly outputs predicted text information. Compared with the traditional scheme, the model has higher model training efficiency and less resource overhead in the service operation phase.
Text detection and recognition technology is at an interdisciplinary intersection, and its technological evolution has continuously benefited from technological advances in computer vision processing and natural language processing. It not only needs to use visual processing technology to extract the image feature vector of the text area in the image, but also needs to use natural language processing technology to decode the image feature vector as the text result.
Model basics
As can be seen from the public papers, various basic networks originating from visual processing tasks such as image classification, detection, and semantic segmentation have been used to extract feature vectors of text regions in images. At the same time, multiple network frameworks originating from object detection and semantic segmentation tasks have also been transformed to improve the accuracy and execution speed of graphic recognition tasks. This chapter will briefly review the implementation principles of these basic networks and network frameworks, and introduce the various scene adaptation problems faced when applying them in graphic recognition tasks.
Basic network
The basic network used as the feature extraction module in the graphic recognition task can be derived from the image classification model of the general scene. For example, VGGNet, ResNet, InceptionNet, DenseNet, Inside-Outside Net, Se-Net, etc.
The basic network in the task of graphic recognition can also be derived from a dedicated network model for specific scenarios. For example, an FCN network that is good at extracting detailed features of an image, and an STN network that is good at doing image correction.
Since everyone is already familiar with the common network model, this section only briefly introduces the above dedicated network model.
FCN network
Fully convolutional network (FCN, fully convolutional network) is a basic network with a fully connected (fc) layer removed. It was originally used to implement semantic segmentation tasks. The advantage of FC lies in the use of deconvolution, unpooling and other upsampling operations to restore the feature matrix to the size of the original image, and then make a category prediction for the pixels at each position, so that Identify clearer object boundaries. The FCN-based detection network no longer returns to the object frame through the candidate area, but directly predicts the object frame based on the high-resolution feature map. Because it is not necessary to define the length and width ratio of the candidate box before training like Faster-RCNN, FCN is more robust when predicting the boundary of irregular objects. Because the pixel resolution of the last feature map of the FCN network is high, and the text recognition task needs to rely on clear text strokes to distinguish different characters (especially Chinese characters), the FCN network is very suitable for extracting text features. When FCN is used for image recognition tasks, each pixel in the last feature map will be divided into two categories: text lines (foreground) and non-text lines (background).
STN network
The function of Spatial Transformer Networks (STN, Spatial Transformer Networks) is to correct the spatial position of the input feature map to obtain the output feature map. This correction process can be gradient-conducted to support end-to-end model training.
As shown in the figure below, the STN network consists of a localization network, a grid generator, and a sampler. The positioning network calculates a set of control parameters based on the original feature map U. The set of control parameters of the grid generator generates a sampling grid. The sampler samples the pixels in the original map U to the target map according to the sampling grid kernel function. V.
The control parameters of the spatial transformation are dynamically generated according to the original feature map U, and the meta-parameters for generating the spatial transformation control parameters are learned during the model training phase and stored in the weights matrix of the positioning network.
From arXiv: 1506.02025,’Spatial Transformer Networks
Detection network framework
Faster RCNN as a detection network framework, its goal is to find a compact frame (BBOX, Bounding Box) surrounding the detected object. As shown in the following figure, it introduces a region proposal network (RPN, Region Proposal Network) based on the Fast RCNN detection framework to quickly generate multiple candidate region reference frames (anchor) close to the length-width ratio of the target object; it passes the ROI ( Region of Interest) The Pooling layer generates normalized fixed-size regional features for multiple size reference frames; it uses a shared CNN convolutional network to simultaneously input feature maps to the above RPN network and ROI Pooling layer, thereby reducing Convolutional layer parameters and calculations. The multi-objective loss function was used in the training process, including RPN network, ROI Pooling layer frame classification loss and coordinate regression loss. Through the back propagation of the gradient of these losses, the coordinates of the candidate frame can be adjusted, and the overlap/intersection ratio (IOU, Intersection over Union) of the candidate frame can be increased. The initial value of the candidate frame generated by the RPN grid has a fixed position and a ratio of length to width. If the initial length-to-width ratio of the candidate frame is set to be very different from the shape of the object in the image, it is difficult to find a compact frame surrounding it through regression.
Excerpt from arXiv: 1506.01497, ‘Faster R-CNN: Towards Real-Ti
SSD (Single Shot MultiBox Detector) is a full-convolution target detection algorithm proposed in 2016. Up to now, it is still one of the main target detection frameworks, which has obvious speed advantages compared to Faster RCNN. As shown in the figure below, SSD is a one stage algorithm that directly predicts the frame and score of the detected object. In the detection process, the SSD algorithm uses multi-scale thinking to detect, and generates multiple default boxes on the feature maps of different scales that are close to the length-width ratio of the target object for regression and classification. Finally, non-maximum suppression is used to obtain the final detection result. During the training process, SSD adopts Hard negative mining strategy for training, keeping the ratio of positive and negative samples at 1:3, and using multiple data augmentation (Data augmentation) methods for training to improve model performance.
Excerpt from arxiv: 1512.02325, “SSD: Single Shot MultiBox
Text detection model
The goal of the text detection model is to find the area of the text as accurately as possible from the picture.
However, the conventional object detection methods in the visual field (SSD, YOLO, Faster-RCNN, etc.) directly applied to the text detection task are not ideal. The main reasons are as follows:
·Compared with conventional objects, the length of text lines and the ratio of length to width vary greatly.
·The text line is directional. The amount of information about the description method of the four-tuple of the regular object frame BBox is insufficient.
· The partial images of some objects in natural scenes are similar to the shape of letters, and there will be false alarms if the global information of the images is not referenced.
·Some artistic fonts use curved lines of text, and there are many variations of handwriting fonts.
· Due to the rich background image interference, hand-designed features are not robust enough in natural scene text recognition tasks.
In response to the causes of the above problems, various technical solutions based on deep learning have emerged in recent years. They have modified conventional object detection methods from the perspective of feature extraction, regional recommendation network (RPN), multi-objective collaborative training, Loss improvement, non-maximum suppression (NMS), semi-supervised learning, etc., which greatly improves the natural scene image Chinese The accuracy of this test. E.g:
· In the CTPN scheme, the BLSTM module is used to extract the contextual features of the image where the characters are located to improve the recognition accuracy of the text block.
In RRPN and other schemes, the text box labeling adopts the form of BBOX + direction angle value, and a rotatable text area candidate box is generated in the model, and the inclination angle of the text line to be measured is found in the frame regression calculation process.
· In programs such as DMPNet, quadrilateral (non-rectangular) text boxes are used to more compactly enclose the text area.
·SegLink cuts the word into small blocks of text that are easier to detect, and then predicts the adjacent connections to connect the small blocks of text into words.
In the TextBoxes and other solutions, the length-width ratio of the reference frame of the text area is adjusted, and the convolution kernel of the feature layer is adjusted to a rectangle, which is more suitable for detecting elongated text lines.
In the FTSN scheme, the author uses Mask-NMS instead of the traditional BBOX NMS algorithm to filter candidate boxes.
· In the WordSup scheme, a semi-supervised learning strategy is adopted, and word-level annotation data is used to train a character-level text detection model.
The following uses multiple model cases that have appeared in recent years to introduce how to apply the above methods to improve the effect of image text detection.
CTPN model
CTPN is currently the most widely spread and most influential open source text detection model, which can detect horizontal or slightly oblique text lines. The text line can be regarded as a character sequence, rather than a single independent target in general object detection. Each character image on the same text line can be a context with each other. In the training phase, let the detection model learn this kind of context statistics contained in the image, which can effectively improve the prediction accuracy of the text block in the prediction phase. In the image prediction process of the CTPN model, the front end uses the popular VGG16 as the basic network to extract the local image features of each character, and the BLSTM layer is used to extract the context features of the character sequence in the middle, and then through the FC fully connected layer, each text is output through the prediction branch at the end The coordinate value of the block and the probability value of the classification result. In the data post-processing stage, the adjacent small text blocks will be merged into text lines.
From arXiv: 1609.03605,’Detecting Text in Natural Im
RRPN model
Based on the scheme of Rotation Region Proposal Networks (RRPN, Rotation Region Proposal Networks), the rotation factors are incorporated into classical region candidate networks (such as Faster RCNN). In this scheme, the ground truth of a text area is expressed as a rotating border with 5 tuples (x, y, h, w, θ), the coordinates (x, y) represent the geometric center of the border, and the height h is set to The short side of the frame, the width w is the long side, and the direction is the direction of the long side. During training, first generate a skew candidate box containing the text direction angle, and then learn the text direction angle during the frame regression process.
From arXiv: 1703.01086,’Arbitrary-Oriented Scene Tex
In the scheme of RRPN, a Rotation Region-of-Interest (RRoI) pooling layer is proposed. It is recommended to divide the area in any direction into sub-regions, and then perform max pooling on these sub-regions and project the results to With a fixed space size on a small feature map.
From arXiv: 1703.01086,’Arbitrary-Oriented Scene Tex
FTSN model
The FTSN (Fused Text Segmentation Networks) model uses segmentation networks to support slanted text detection. It uses Resnet-101 as the basic network and uses multi-scale fusion feature maps. Annotated data includes pixel masks and borders of text instances, and uses pixel prediction and border detection for multi-target training.
From arXiv: 1709.03272,’Fused Text Segmentation Netw
Mask-NMS based on the pixel-level coincidence between text instances replaces the traditional NMS algorithm based on the coincidence between horizontal borders. The sub-picture on the left of the figure below is the result of the traditional NMS algorithm. The white border in the middle is erroneously suppressed. The sub-picture on the right of the figure below is the execution result of the Mask-NMS algorithm, and all three borders have been successfully retained.
DMPNet model
In DMPNet (Deep Matching Prior Network), quadrilateral (non-rectangular) is used to mark the boundaries of text regions more compactly, and the model trained by it is better for detecting oblique text blocks.
As shown in the following figure, it uses a sliding window to obtain a text area candidate box on the feature map. The candidate box has both square and slanted quadrilaterals. Next, the Monte-Carlo method based on pixel sampling is used to quickly calculate the area coincidence between the quadrangle candidate frame and the labeled frame. Then, calculate the distance from the coordinates of the four vertices to the center point of the quadrangle, and compare them with the labeled values to calculate the target loss. It is recommended to replace L1 and L2 loss with Ln loss in the article, so that the size of the text box has a faster training regression (regress) speed.
From arXiv: 1703.01425,’Deep Matching Prior Network:
EAST model
In the EAST (Efficient and Accuracy Scene Text detection pipeline) model, a fully convolutional network (FCN) is first used to generate multi-scale fusion feature maps, and then pixel-level text block prediction is directly performed on this basis. In this model, two types of text area labeling are supported: rotating rectangular frame and arbitrary quadrilateral. Corresponding to the quadrilateral annotation, the model will predict the coordinate difference to the four vertices of each pixel in the feature map. Corresponding to the rotation of the rectangular frame label, the distance between the four sides of the rectangular frame and the direction angle of the rectangular frame are predicted for each pixel in the feature map when the model is executed.
According to the test of the pre-training model in the open source project, the model has a good effect on detecting English words and a poor effect on detecting long lines of Chinese text. Perhaps, after targeted training based on the characteristics of Chinese data, there is room for improvement in the detection effect.
In the above process, the steps of region suggestion, word segmentation, and sub-block merging that are common in other models are omitted, so the execution speed of this model is very fast.
From arXiv: 1704.03155,’EAST: An Efficient and Accur
SegLink model
In the labeling data of the SegLink model, each word is first cut into more directional small text blocks that are easier to detect, and then each small text block is connected into a word using a neighboring link. This scheme is convenient for identifying directional words and text lines that vary widely in length, and it will not detect long text lines because of the ratio of candidate box length to width like Faster-RCNN and other schemes. Compared with CTPN and other text detection models, SegLink's image processing speed is much faster.
From arXiv: 1703.06520,’Detecting Oriented Text in Na
As shown in the figure below, the model can simultaneously detect small text blocks from 6 scale feature maps. Small character blocks on the feature maps of the same layer, or the feature maps of adjacent layers may be connected into the same word. In other words, text blocks that are close in position and close in size may be predicted into the same word.
From arXiv: 1703.06520,’Detecting Oriented Text in Na
PixelLink model
A group of text blocks in natural scene images are often close together, and it is difficult to identify them by semantic segmentation, so the PixelLink model attempts to solve this problem by using instance segmentation.
The feature extraction part of the model is the FCN network constructed on the basis of VGG16. The model execution flow is shown in the figure below. First, two pixel-level predictions are performed with the help of the CNN module: a text binary classification prediction and a link binary classification prediction. Then, the positive links are used to connect the neighboring positive text pixels to obtain the segmentation result of the text block instance. Then, the frame of the text block is directly obtained from the segmentation result, and it is allowed to generate the inclined frame.
In the above process, the border regression step common in other models is omitted, so the training convergence speed is faster. In the training phase, a balancing strategy is used so that each text block has the same weight in the total LOSS. During training, examples of text blocks in various directions and angles were added through preprocessing.
From arXiv: 1801.01315,’Detecting Scene Text via Inst
Textboxes/Textboxes++ model
Textboxes are graphic detection models based on the SSD framework, the training method is end-to-end, and the running speed is faster. As shown in the figure below, in order to adapt to the characteristics of slender characters, the aspect ratio of the candidate frame has been increased by 1, 2, 3, 5, 7, 10 initial values. In order to adapt to the slender character of the text line, the feature layer also replaces the square convolution kernel commonly used in other models with a strip-shaped convolution kernel. To prevent missing lines of text, the number of candidate boxes has also been increased in the vertical direction. In order to detect character blocks of different sizes, text boxes are predicted in parallel on feature maps of multiple scales, and then NMS filtering is performed on the prediction results.
From arXiv: 1611.06779, ‘TextBoxes: A Fast Text Detect
(Textboxes++ is an upgraded version of Textboxes, the purpose is to add support for slanted text. To this end, the label data is changed to the format of rotating rectangular boxes and irregular quadrilaterals; The shapes have been adjusted accordingly.
From arXiv: 1801.02765,’ TextBoxes++: A Single-Shot O
WordSup model
As shown in the following figure, the character-level detection model is a key basic module in applications such as mathematical formula text recognition and irregular deformation text line recognition. Due to the high cost of character-level natural scene image labeling and the scarcity of related public data sets, most current image and text detection models can only train on text line and word-level labeling data. WordSup proposes a weakly supervised training framework that can train character-level detection models on text-line and word-level annotation datasets.
As shown in the figure below, in the WordSup weakly supervised training framework, two training steps are performed alternately: given the current character detection model, combined with word-level annotation data, a character center point mask map is calculated; given character center point mask Figure, supervised training of character-level detection models.
From arXiv: 1708.06720,’ WordSup: Exploiting Word Anno
As shown in the figure below, after training the character detector, you can add a suitable text structure analysis module to the data pipeline to output text content that meets the format requirements of the application scenario. The author of this article cites various implementations of the text structure analysis module.
The goal of the text recognition model is to recognize the text content from the segmented text area.
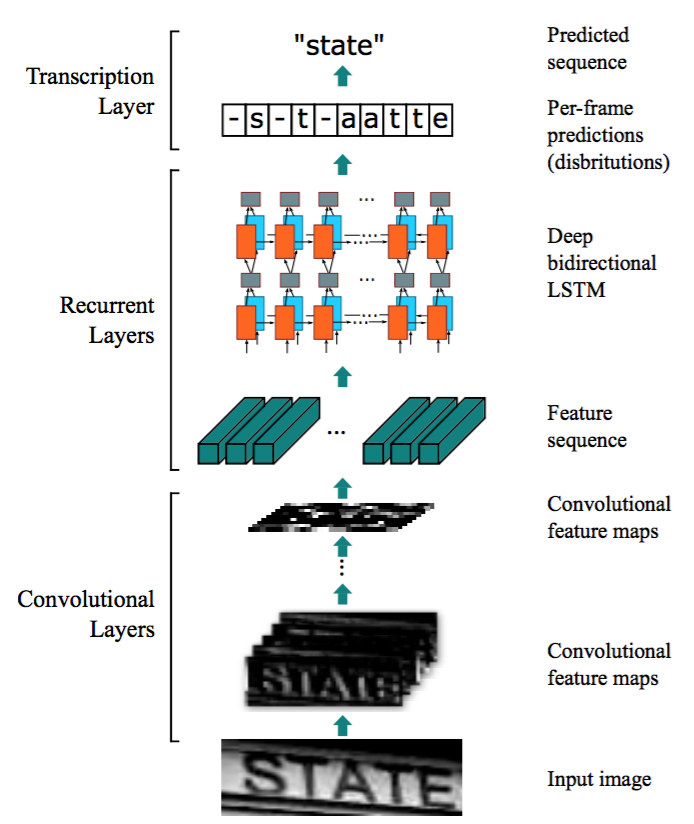
CRNN model
CRNN (Convolutional Recurrent Neural Network) is currently a popular graphic recognition model that can recognize long text sequences. It contains CNN feature extraction layer and BLSTM sequence feature extraction layer, which can carry out end-to-end joint training. It uses BLSTM and CTC components to learn the contextual relationship in character images, thereby effectively improving the accuracy of text recognition and making the model more robust. In the prediction process, the front end uses a standard CNN network to extract the features of the text image, and uses BLSTM to fuse the feature vectors to extract the context features of the character sequence, and then obtain the probability distribution of each column of features, and finally make predictions through the transcription layer (CTC rule) Get the text sequence.
From arXiv: 1507.05717,’An End-to-End Trainable Neura
RARE model
The RARE (Robust text recognizer with Automatic Rectification) model works well in recognizing distorted image text. As shown in the figure below, in the model prediction process, the input image must first be sent to a spatial transformation network for processing. The corrected image is then sent to the sequence recognition network to obtain the text prediction result.
As shown in the figure below, the spatial transformation network contains three components: positioning network, grid generator and sampler. After training, it can dynamically generate a spatial transformation grid according to the feature map of the input image, and then the sampler samples a rectangular text image from the original image according to the transformation grid kernel function. RARE supports a spatial transformation called TPS (thin-plate splines), which can more accurately identify perspective-transformed text and curved text.
From arXiv: 1603.03915,’Robust Scene Text Recognition
End-to-end model
The goal of the end-to-end model is to locate and recognize all text content directly from the picture in one stop.
FOTS Rotation-Sensitive Regression
FOTS (Fast Oriented Text Spotting) is an end-to-end learnable network model for simultaneous training of image text detection and recognition. The detection and recognition tasks share the convolutional feature layer, which not only saves computing time, but also learns more image features than the two-stage training method. Introducing a rotating region of interest (RoIRotate), which can generate directional text regions from convolutional feature maps, thereby supporting the identification of slanted text.
From arXiv: 1801.01671,’FOTS: Fast Oriented Text Spot
STN-OCR model
STN-OCR is an end-to-end learnable model that integrates graphic detection and recognition functions. In its detection part, a spatial transformation network (STN) is embedded to perform affine transformation on the original input image. Using this spatial transformation network, image correction actions such as rotation, zooming, and tilting can be performed on the detected multiple text blocks, respectively, thereby obtaining better recognition accuracy in the subsequent text recognition stage. STN-OCR is a semi-supervised learning method in training. It only needs to provide text content annotation, and does not require text positioning information. The author also mentioned that if you start training from the beginning, the network convergence speed is slow, so it is recommended to gradually increase the training difficulty. STN-OCR has opened the engineering source code and pre-training model.
From arXiv: 1707.08831,’STN-OCR: A single Neural Netw
Training dataset
This chapter will list some large public data sets that can be used for model training in the field of text detection and recognition, and does not involve small data sets that are only used for model fine-tune tasks.
Chinese Text in the Wild(CTW)
The data set contains 32,285 images, 1,018,402 Chinese characters (from Tencent Street View), including flat text, raised text, urban text, rural text, low-brightness text, distant text, and partial occlusion text. The image size is 2048*2048, and the data set size is 31GB. The data set is divided into a training set (25887 images, 812872 Chinese characters), a test set (3269 images, 103519 Chinese characters), and a validation set (3129 images, 103519 Chinese characters) at a ratio of (8:1:1) .
Literature link: https://arxiv.org/pdf/1803.00085.pdf
Data set download address: https://ctwdataset.github.io/
Reading Chinese Text in the Wild(RCTW-17)
The data set contains 12,263 images, 8034 training sets, 4229 test sets, a total of 11.4GB. Most of the images were taken by mobile phone cameras and contained a few screenshots. The images contained Chinese text and a small amount of English text. The image resolution varies.
Download address http://mclab.eic.hust.edu.cn/icdar2017chinese/dataset.html
Literature: http://arxiv.org/pdf/1708.09585v2
ICPR MWI 2018 Challenge
The competition provides 20,000 images as a data set, 50% of which is the training set and 50% is the test set. It is mainly composed of synthetic images, product descriptions, and online advertisements. The data set is full of data, mixed in Chinese and English, covering dozens of fonts with different font sizes, multiple layouts, and complex backgrounds. The file size is 2GB.
download link:
https://tianchi.aliyun.com/competition/information.htm?raceId=231651&_is_login_redirect=true&accounttraceid=595a06c3-7530-4b8a-ad3d-40165e22dbfe
Total-Text
The dataset contains a total of 1555 images and 11459 lines of text, including horizontal text, slanted text, and curved text. The file size is 441MB. Most are English texts, and a few are Chinese texts. Training set: 1255 sheets Test set: 300
Download address: http://www.cs-chan.com/source/ICDAR2017/totaltext.zip
Literature: http:// arxiv.org/pdf/1710.10400v
Google FSNS (Google Street View Text Data Set)
The data set is more than one million street name signs obtained from Google French Street View pictures, each of which contains different perspectives of the same street sign, the image size is 600*150, the training set is 1044868 and the verification set is 16150. 20,404 test sets.
Download address: http://rrc.cvc.uab.es/?ch=6&com=downloads
Literature: http:// arxiv.org/pdf/1702.03970v1
Replace high definition image
COCO-TEXT
The data set includes 63,686 images and 173,589 text examples, including handwritten and printed versions, clear and unclear versions. File size 12.58GB, training set: 43686, test set: 10000, verification set: 10000
Literature: http://arxiv.org/pdf/1601.07140v2
Download address: https://vision.cornell.edu/se3/coco-text-2/
Synthetic Data for Text Localisation
Natural scene text data synthesized under complex background. Contains 858750 images, a total of 7266866 word examples, 28971487 characters, and a file size of 41GB. The synthetic algorithm can know the label information and position information of the text without manual labeling, and can obtain a large amount of text labeling data of natural scenes.
Download address: http://www.robots.ox.ac.uk/~vgg/data/scenetext/
Literature: http://www.robots.ox.ac.uk/~ankush/textloc.pdf
Code: https://github.com/ankush-me/SynthText (English version)
Code https://github.com/wang-tf/Chinese_OCR_synthetic_data (Chinese version)
Synthetic Word Dataset
The synthetic text recognition data set contains 9 million images and covers 90,000 English words. The file size is 10GB
Download address: http://www.robots.ox.ac.uk/~vgg/data/text/
Caffe-ocr Chinese synthetic data
The data is randomly generated from the Chinese corpus through font, size, grayscale, blur, perspective, stretching and other changes. A total of 3.6 million pictures with an image resolution of 280x32 cover a total of 5990 characters including Chinese characters, punctuation, English, and numbers. The file size is about 8.6GB
Download address: https://pan.baidu.com/s/1dFda6R3
references
1. "Optical Character Recognition Technology: Let Computers Read Like People", Sina Weibo, Huo Qiang
http://tech.sina.com.cn/d/i/2015-04-03/doc-icczmvun8339303.shtml
2. “Fully Convolutional Networks for Semantic Segmentation”, arXiv:1411.4038,Jonathan Long, Evan Shelhamer, Trevor Darrell
https://arxiv.org/pdf/1411.4038
3. “Spatial Transformer Networks”,arXiv:1506.02025,Max Jaderberg, Karen Simonyan, Andrew Zisserman, Koray Kavukcuoglu
https://arxiv.org/pdf/1506.02025
4.“Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks”,arXiv:1506.01497,Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun
https://arxiv.org/pdf/1506.01497
5.“SSD: Single Shot MultiBox Detector”,arxiv:1512.02325,Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg
https://arxiv.org/pdf/1512.02325
6.“Detecting Text in Natural Image with Connectionist Text Proposal Network”,arXiv:1609.03605,Zhi Tian, Weilin Huang, Tong He, Pan He, Yu Qiao
https://arxiv.org/pdf/1609.03605
7.“Arbitrary-Oriented Scene Text Detection via Rotation Proposals”,arXiv:1703.01086,Jianqi Ma, Weiyuan Shao, Hao Ye, Li Wang, Hong Wang, Yingbin Zheng, Xiangyang Xue
https://arxiv.org/pdf/1703.01086
8.“Fused Text Segmentation Networks for Multi-oriented Scene Text Detection”,arXiv:1709.03272,Yuchen Dai, Zheng Huang, Yuting Gao, Youxuan Xu, Kai Chen, Jie Guo, Weidong Qiu
https://arxiv.org/pdf/1709.03272
9.“Deep Matching Prior Network: Toward Tighter Multi-oriented Text Detection”,arXiv:1703.01425,Yuliang Liu, Lianwen Jin
https://arxiv.org/pdf/1703.01425
10.“EAST: An Efficient and Accurate Scene Text Detector”,arXiv:1704.03155,Xinyu Zhou, Cong Yao, He Wen, Yuzhi Wang, Shuchang Zhou, Weiran He, Jiajun Liang
https://arxiv.org/pdf/1704.03155
11.“Detecting Oriented Text in Natural Images by Linking Segments”,arXiv:1703.06520,Baoguang Shi, Xiang Bai, Serge Belongie
https://arxiv.org/pdf/1703.06520
12. “Detecting Scene Text via Instance Segmentation”,arXiv:1801.01315,Dan Deng, Haifeng Liu, Xuelong Li, Deng Cai
https://arxiv.org/pdf/1801.01315
13.“TextBoxes: A Fast Text Detector with a Single Deep Neural Network”,arXiv:1611.06779,Minghui Liao, Baoguang Shi, Xiang Bai, Xinggang Wang, Wenyu Liu
https://arxiv.org/pdf/1611.06779
14.“TextBoxes++: A Single-Shot Oriented Scene Text Detector”,arXiv:1801.02765,Minghui Liao, Baoguang Shi, Xiang Bai
https://arxiv.org/pdf/1801.02765
15.“WordSup: Exploiting Word Annotations for Character based Text Detection”,arXiv:1708.06720,Han Hu, Chengquan Zhang, Yuxuan Luo, Yuzhuo Wang, Junyu Han, Errui Ding
https://arxiv.org/pdf/1708.06720
16.“An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition”,arXiv:1507.05717,Baoguang Shi, Xiang Bai, Cong Yao
https://arxiv.org/pdf/1507.05717
17. “Robust Scene Text Recognition with Automatic Rectification”,arXiv:1603.03915,Baoguang Shi, Xinggang Wang, Pengyuan Lyu, Cong Yao, Xiang Bai
https://arxiv.org/pdf/1603.03915
18.“FOTS: Fast Oriented Text Spotting with a Unified Network”,arXiv:1801.01671,Xuebo Liu, Ding Liang, Shi Yan, Dagui Chen, Yu Qiao, Junjie Yan
https://arxiv.org/pdf/1801.01671
19.“STN-OCR: A single Neural Network for Text Detection and Text Recognition”,arXiv:1707.08831,Christian Bartz, Haojin Yang, Christoph Meinel
https://arxiv.org/pdf/1707.08831
20.“Chinese Text in the Wild”,arXiv:1803.00085,Tai-Ling Yuan, Zhe Zhu, Kun Xu, Cheng-Jun Li, Shi-Min Hu
https://arxiv.org/pdf/1803.00085.pdf
21.“ICDAR2017 Competition on Reading Chinese Text in the Wild (RCTW-17)”,arXiv:1708.09585,Baoguang Shi, Cong Yao, Minghui Liao, Mingkun Yang, Pei Xu, Linyan Cui, Serge Belongie, Shijian Lu, Xiang Bai
http://arxiv.org/pdf/1708.09585
22.“Total-Text: A Comprehensive Dataset for Scene Text Detection and Recognition”,arXiv:1710.10400,Chee Kheng Chng, Chee Seng Chan
https://arxiv.org/pdf/1710.10400
23.“End-to-End Interpretation of the French Street Name Signs Dataset”,arXiv:1702.03970,Raymond Smith, Chunhui Gu, Dar-Shyang Lee, Huiyi Hu, Ranjith Unnikrishnan, Julian Ibarz, Sacha Arnoud, Sophia Lin
https://arxiv.org/pdf/1702.03970
24.“COCO-Text: Dataset and Benchmark for Text Detection and Recognition in Natural Images”,arXiv:1601.07140,Andreas Veit, Tomas Matera, Lukas Neumann, Jiri Matas, Serge Belongie
http://arxiv.org/pdf/1601.07140
25. “Synthetic Data for Text Localisation in Natural Images”,arXiv:1604.06646, Ankush Gupta, Andrea Vedaldi, Andrew Zisserman
https://arxiv.org/pdf/1604.06646
Recommended reading
[1]Machine learning-40 years of magnificence【Acquisition Code】SIGAI0413.
[2]What mathematical knowledge is required to learn machine learning?【Acquisition Code】SIGAI0417.
[3] History of face recognition algorithm evolution【Acquisition Code】SIGAI0420.
[4]Survey of target detection algorithms based on deep learning 【Acquisition Code】SIGAI0424.
[5]Why can convolutional neural networks dominate the field of computer vision?【Acquisition Code】SIGAI0426.
[6] Use a picture to understand the context of SVM【Acquisition Code】SIGAI0428.
[7] Overview of face detection algorithms【Acquisition Code】SIGAI0503.
[8] Understand the activation function of neural networks 【Acquisition Code】SIGAI2018.5.5.
[9] Deep convolutional neural network evolution history and structural improvement vein-a comprehensive interpretation of 40 pages of long text【Acquisition Code】SIGAI0508.
[10] Understand gradient descent【Acquisition Code】SIGAI0511.
[11] Overview of Recurrent Neural Networks—A Tool for Speech Recognition and Natural Language Processing【Acquisition Code】SIGAI0515
[12] Understand convex optimization 【Acquisition Code】 SIGAI0518
[13] [Experiment] Understand the kernel function and parameters of SVM 【Acquisition Code】SIGAI0522
[14][Summary of SIGAI] Pedestrian detection algorithm 【Acquisition Code】SIGAI0525
[15] The Application of Machine Learning in Automated Driving—Taking Baidu Apollo Platform as an Example (Part 1)【Acquisition Code】SIGAI0529
[16]Understanding Newton's method【Acquisition Code】SIGAI0531
[17] [Essence of Group Topics] May Highlights-Some Questions Worth Thinking about Machine Learning and Deep Learning【Acquisition Code】SIGAI 0601
[18] Adaboost algorithm 【Acquisition Code】SIGAI0602
[19] FlowNet to FlowNet2.0: Optical flow prediction algorithm based on convolutional neural network【Acquisition Code】SIGAI0604
[20] Understanding principal component analysis (PCA)【Acquisition Code】SIGAI0606
[21] Summary of key points detection of human bones 【Acquisition Code】SIGAI0608
[22]Understanding the decision tree 【Acquisition Code】SIGAI0611
[23] Summarize commonly used machine learning algorithms in one sentence【Acquisition Code】SIGAI0611
[24] Target detection algorithm YOLO 【Acquisition Code】SIGAI0615
[25] Understand overfitting 【Acquisition Code】SIGAI0618
[26]Comprehension calculation: From √2 to AlphaGo-Season 1 From √2 【Acquisition Code】SIGAI0620
[27] Scene Text Detection-Introduction of CTPN Algorithm 【Acquisition Code】SIGAI0622
[28] Convolutional neural network compression and acceleration 【Acquisition Code】SIGAI0625
[29] k-nearest neighbor algorithm 【Acquisition Code】SIGAI0627
[30]A Summary of Natural Scene Text Detection and Recognition Technology 【Acquisition Code】SIGAI0627
[31] Understanding computing: from √2 to AlphaGo-Season 2 The historical background of neural computing 【Acquisition Code】SIGAI0704
[32] Machine learning algorithm map【Acquisition Code】SIGAI0706
[33] Derivation of back propagation algorithm-fully connected neural network【Acquisition Code】SIGAI0709
[34] Overview of generative adversarial network model【Acquisition Code】SIGAI0709.
[35]How to become a good algorithm engineer【Acquisition Code】SIGAI0711.
[36] Comprehension calculation: from root number 2 to AlphaGo-the third quarter mathematical model of neural network【Acquisition Code】SIGAI0716
[37]【Technical short article】S3FD for face detection algorithm 【Acquisition Code】SIGAI0716
[38] Crowd counting method based on deep negative correlation learning【Acquisition Code】SIGAI0718
[39] Overview of manifold learning【Acquisition Code】SIGAI0723
[40] Summary of Receptive Field 【Acquisition Code】SIGAI0723
[41] Random forest overview 【Acquisition Code】SIGAI0725
[42] Summary of Content-based Image Retrieval Technology——Traditional Classic Method【Acquisition Code】SIGAI0727
[43] Neural network activation function summary【Acquisition Code】SIGAI0730
[44] Some questions worth clarifying in machine learning and deep learning【Acquisition Code】SIGAI0802
[45] Overview of automatic question answering system based on deep neural network【Acquisition Code】SIGAI0806
[46] A summary of the core knowledge points of machine learning and deep learning written at the beginning of campus recruitment 【Acquisition Code】SIGAI0808
[47] Understanding Spatial Transformer Networks【Acquisition Code】SIGAI0810
Intelligent Recommendation

Summary of text detection and recognition
table of Contents One install tesseract 1 tesseract download address 2 Installation 3 Configure environment variables Two use python's pytesseract library Three use openCV for text detection &n...

Realize the construction of ChineseOCR based on the darknet framework to achieve CTPN version natural scene text detection and CNN+CTCOCR text recognition
Github address Github source code address Support system: mac/ubuntu python=3.6 Realize function Text detection; Character recognition; Support GPU/CPU, CPU optimization (opencv dnn) Docker image serv...

Using tensorflow to realize natural scene text detection, keras/pytorch implements crnn+ctc to achieve variable length Chinese OCR recognition
Using tensorflow to realize natural scene text detection, keras/pytorch implements crnn+ctc to achieve variable length Chinese OCR recognition Recently studying computer vision related content, found ...
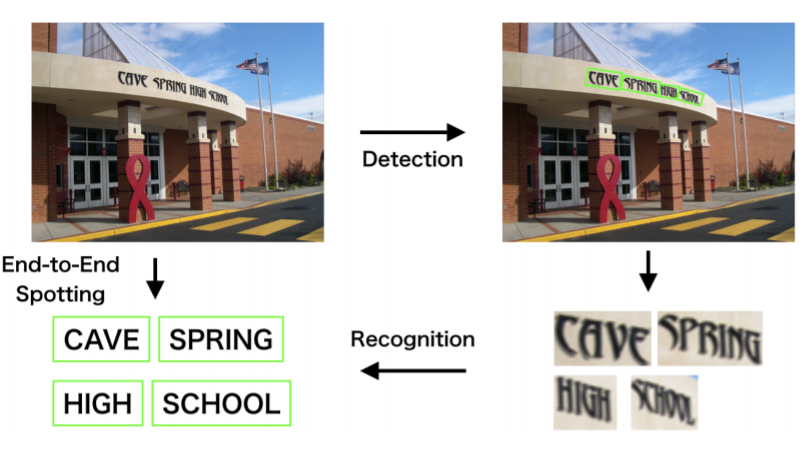
CTPN / CRNN an OCR text recognition natural scene understanding (II)
CRNN 1) end-to-trainable (CNN and the RNN joint training) 2) (image width of any arbitrary length, arbitrary word length) 3) there is no need to calibrate the training set of characters 4) with a dict...

Overview of natural scene text detection techniques (CTPN, SegLink, EAST)
The article is reproduced from: Foreword Text recognition is divided into two specific steps: the detection of text and the recognition of text, both of which are indispensable, especially text detect...
More Recommendation

Python+opencv+EAST to do natural scene text detection (transfer)
Mark, thank the author for sharing! English original link:https://www.pyimagesearch.com/2018/08/20/opencv-text-detection-east-text-detector/ Reminder: Author's implementation of Python's text detectio...

ICDAR 2017 RCTW Chinese scene text detection and recognition data set
Introduction ICDAR is the most well-known and commonly used data set for Scene Text Detection and Recognition tasks. ICDAR 2017 RCTW[1](Reading Chinest Text in the Wild), proposed by Baoguang Shi and ...
"Scene Text Detection and Recognition: The Deep Learning ERA" post-read sensation
table of Contents Foreword Summary background Previous method Now Text detection Simplified pipeline Decomposition into child text Specify the target Text identification CTC Attention mechanism End-to...

Scene text detection OD and character recognition OCR overview
Articles directory Overview Mainly divided into two steps Running framework Complete project example chineseocr chineseocr_lite Chineseocr_lite onnx Scene text detection OD CTPN Scene Text Detection v...
EAST: An Efficient and Accurate Scene Text Detector (text recognition in natural scenes) training, testing
First introduce my environment configuration, ubuntu16.04+cuda9.0, cudnn7.0, tensorflow-gpu=1.8 Introduction In fact, this is not very researched, just to participate in an Ali Tianchi competition, an...