CNN Convolution Neural Network DCN (Deformable Convolutional Networks, DEFORMABLE CONVNETS V2)
tags: Target Detection CNN convolutional neural network Computer vision artificial intelligence convolution Deformed convolution
Deformed convolution network DEFORMABLE CONVNETS V1, V2
Foreword
2017 "DEFORMABLE CONVOLUTIONAL NETWORKS"
Paper address:https://arxiv.org/pdf/1703.06211.pdf
2018 "DEFORMABLE CONVNETS V2: More DEFORMABLE, BETTER RESULTS"
Paper address:https://arxiv.org/pdf/1811.11168.pdf
Since the geometry of the module used in the constructor neural network is fixed, the ability of the geometric transformation modeling is limited. It can be said that the CNN does not have a good implementation of rotation. In the past, data enhancements will be used, allowing the network to force the network to memorize different geometry.
The author believes that the convolution of the conventional fixed shape is a "culprit" of the network that is difficult to adapt to geometric deformation, such as different locations of the same layer, may correspond to different shapes of objects, but all compute with the same shape convolution. So unobstructed wild effects on the entire object, thus proposing variability convolution.
First, DEFORMABLE CONVOLUTIONAL NETWORKS
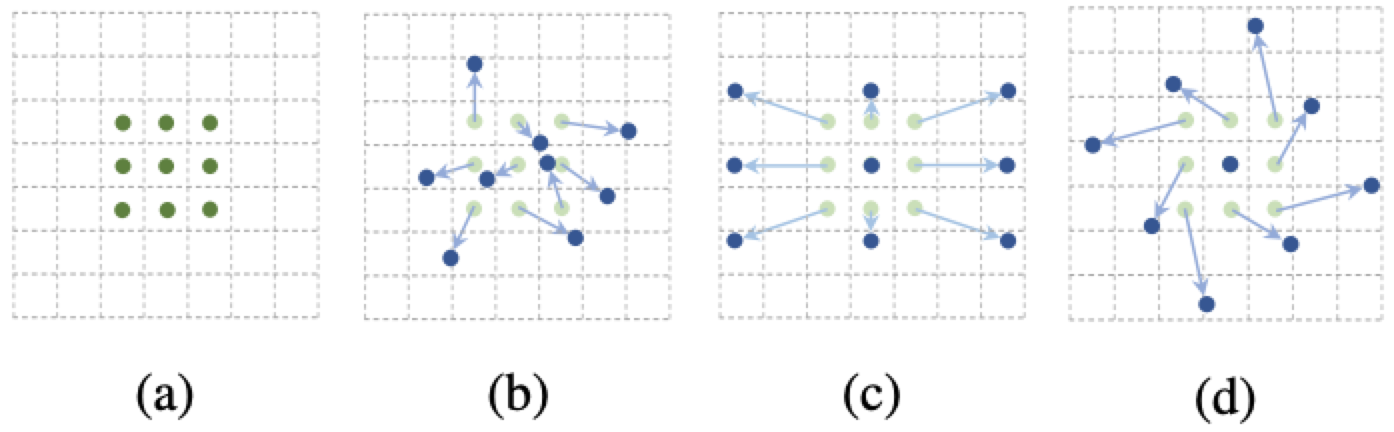
The following figure shows the normal convolution and deformable sampling mode of the volume subscmine size and a deformable convolution, and 9 points shown in the normal convolution indicated by the normal convolution, (B) (B) (C) ( d) is a deformable convolution, on normal sampling coordinatesAdd a displacement(Blue Arrow), (c) (D) as a special case of (b), showing a deformable convolution can be used as a special case of scale transformation, proportional transformation, and rotation transformation:
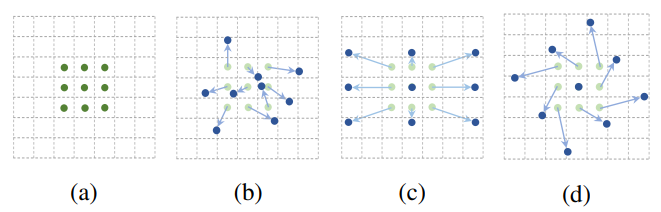
Here, how to calculate the offset displacement:
Deformable Convolution
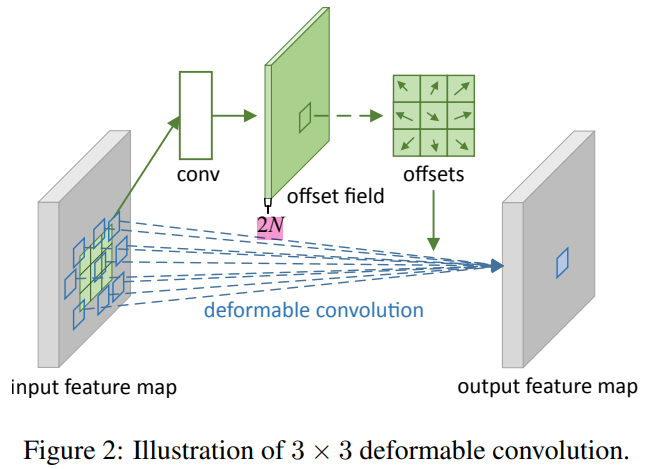
Suppose the feature of the input is WXH, the variable volume to be performed is kernelSize = 3x3, stride = 1, Dilated = 1, then first use a spatial resolution and dilation rate as the current variable glycular layer. Convolution (here also k = 3x3, s = 1, Dial can ensure that the number of offsets is consistent) to learn the OFFSET. CONV will output a WXHX2N of Offset FileD (n is a variable volume of 3x3 = 9 points, 2N is every pointxwithyTwo directions vector). Thereafter, the DCONV deformable convolution will be convolved according to the offset.
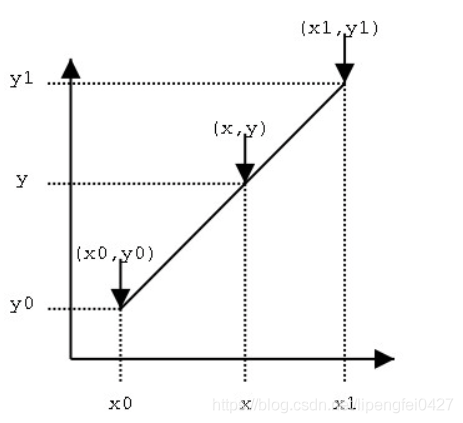
The offset is a decimal, and the original feature map needs to be double linear interpolation.
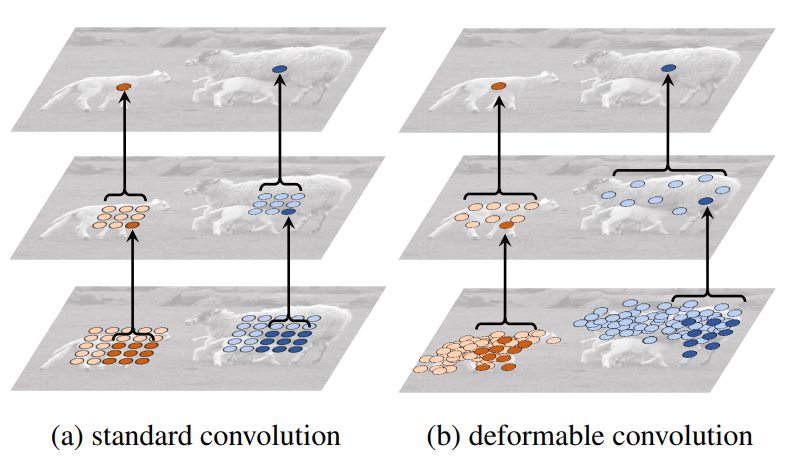
The following figure is the effect of continuous three-stage deformable convolution, each volume of convolution is made of 3 * 3 convolution, and 93 = 729 sample points can be generated after the three-layer convolution. It can be seen that all sampling points after training are offset around different scale targets.

Deformable RoI Pooling
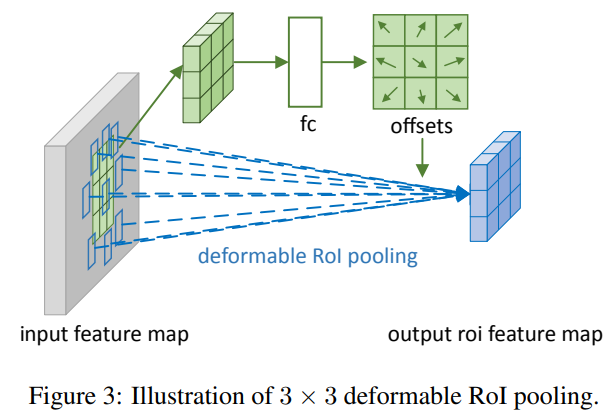
Variable RoIPooling offset value calculation: First ROI Pool generates Pooled Feature Maps, then use FC to learn the normalized offset value (in order to make the offset learning is not affected by the ROI size, you need to bias Make up to normalize), this variable and (w, h) do one multiplication, then multiplied by a scale factor, where W, H is the width and high of ROI, while gamma is a constant factor of 0.1. This displacement acts on deformable interest area pool (blue) to obtain features that are not limited to the fixed grid of interest. P is also a decimal, need to get a true value by bilinear interpolation.

Individual understands that the former is to combine the DEFORMABLE and ROI's scale, better estimate the offset position; and the latter is to prevent the offset from too much or even exceed ROI and the entire image.
The adjusted bin is shown in the red box: This time is not a rule to equal the yellow box ROI to BIN.

Position-Sensitive (PS) RoI Pooling
In addition, the author also has another ROI method similar to the location sensitive than R-FCN, which is also considering the deformable factor, called position-sensitive (ps) ROI Pool, here is not detailed.
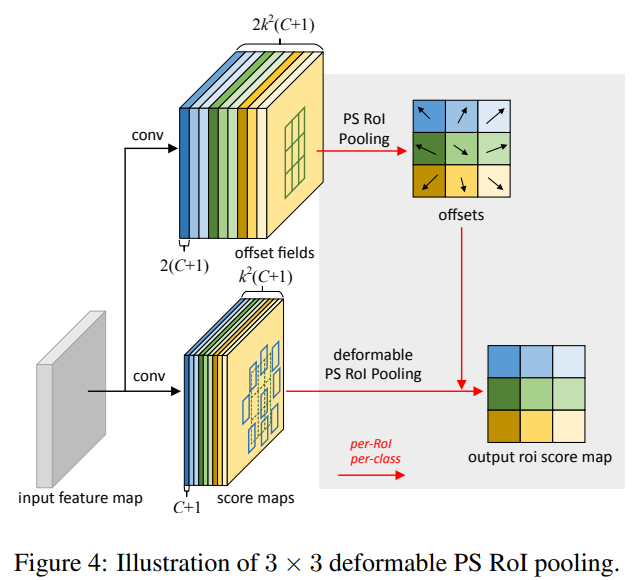
Offset learning is different, as shown. In the top branch, a CONV layer generates a full spatial resolution offset field. For each ROI (equally for each category), PS ROI pool is applied on these fields to obtain normalized offset ΔPbij, and then convert it to true offset ΔPij, method and the above-described variability ROI Pool is the same.
OFFSET offset learning
The author uses 0 initialization, then follow the other parameters of the network. β \beta βBy learning, this β \beta βThe default is 1, but in some cases, those of the FC in the FASTER RCNN are 0.01.
In addition, not all convolutions have a viable variable volume, which is better, and use a variable volume effect after extracting some semantic features, it is generally a few layers of network after the network. The figure below is the performance increase in different layers to the deformable convolution:
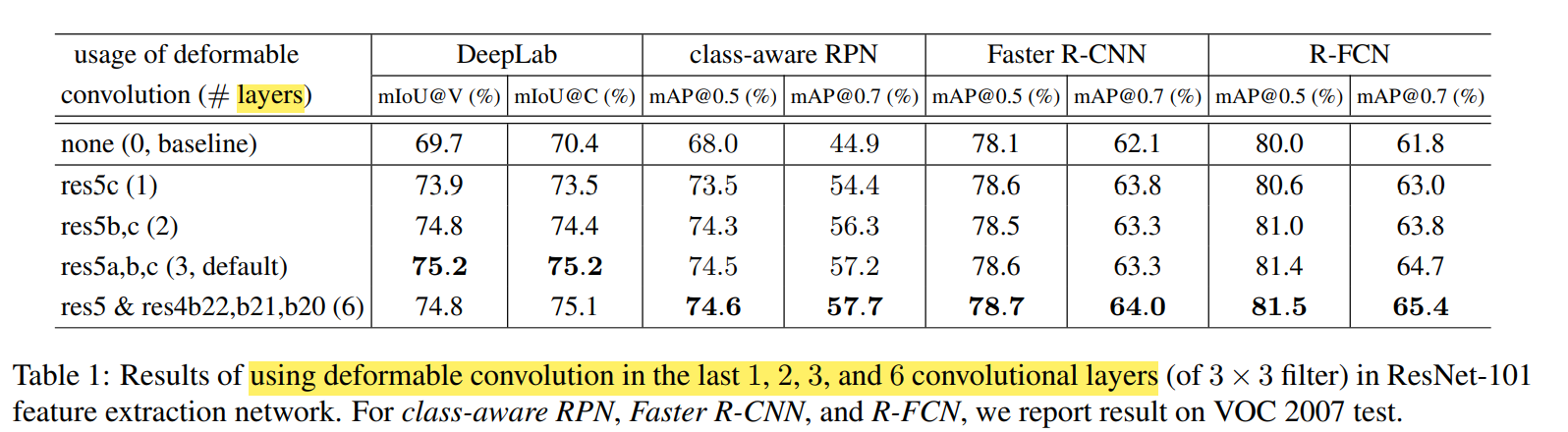
Experimental effect
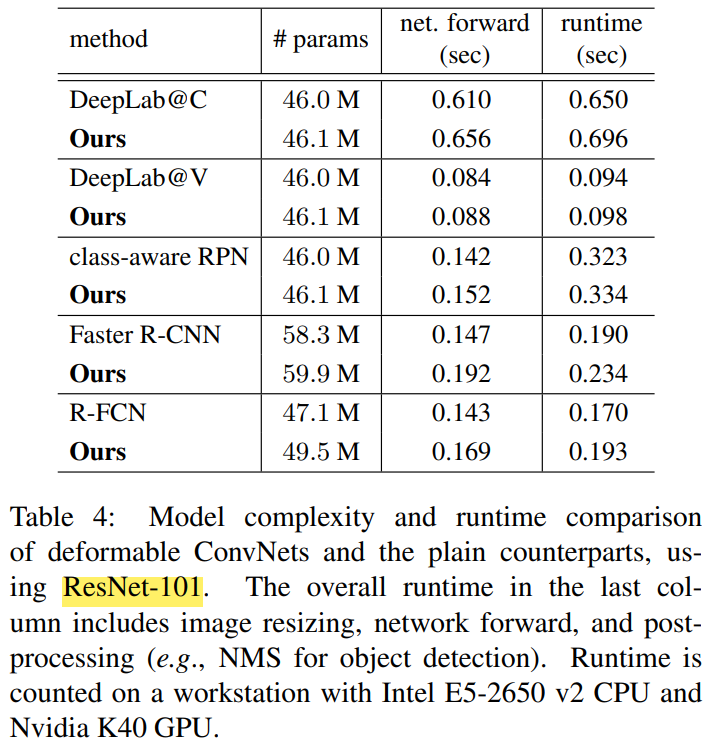
Joining DCN, parameter and speed will only be slightly increased:
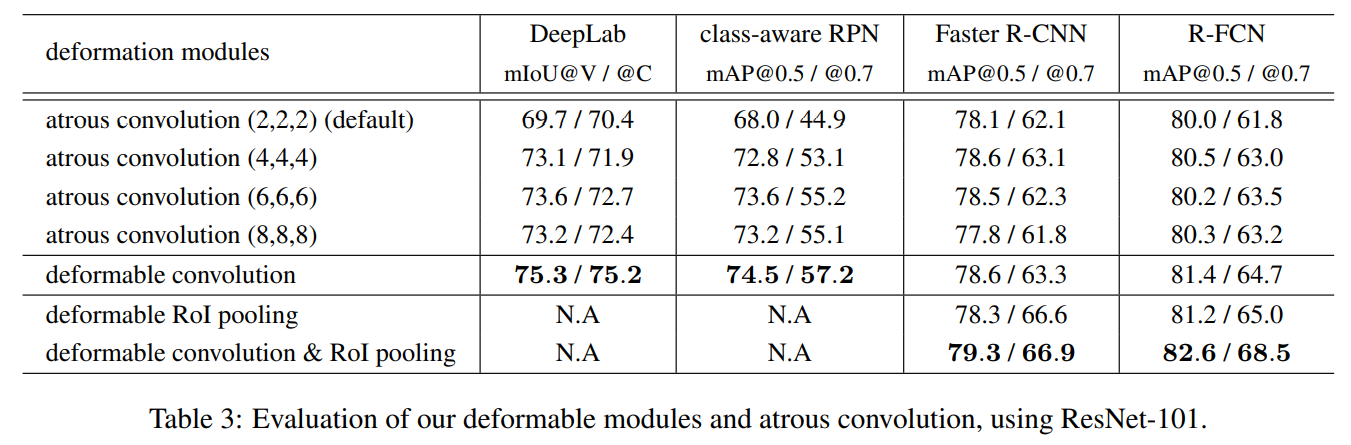
The figure below is comparison in the performance of each task: adding variable volume or variability ROI pool. (Atrous Convolution is also called empty volume Dilated Convolution)
Think
All in all, the convolution changes to similar sampling ideas, but there will be the following places that need to be taken: Is there a layer of network really effective to learn bias? What will the different pictures of different objects will not cause competition in OFFSET optimization (the bias will have their own preferences)?
Second, DEFORMABLE CONVNETS V2
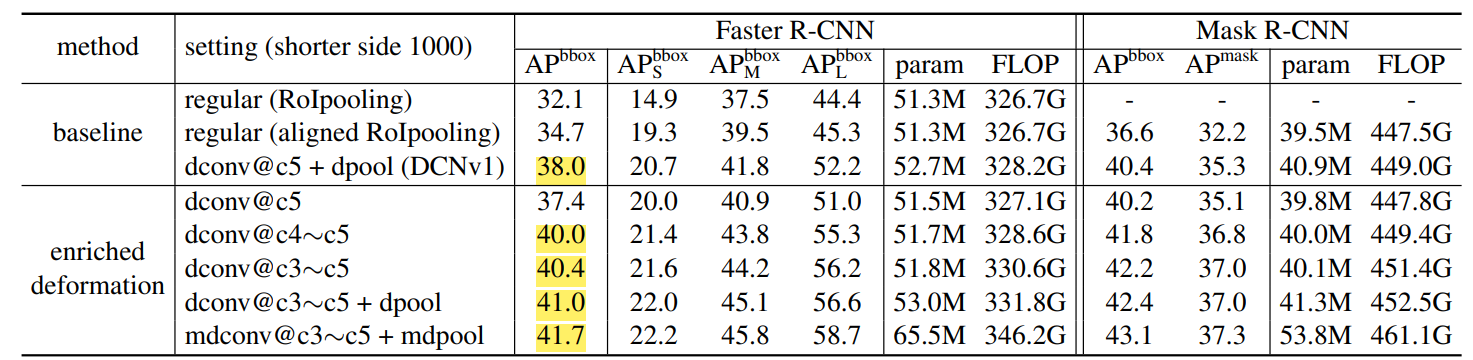
This article has made three improvements to V1:Increase the number of layers of deformable convolution,Adding adjustable deformable modules,Method of distillation mimics RCNN characteristics。
Stacking More Deformable Conv Layers
This article is more than more deformable, better results. The RESNET-50 used in V1, replaces only a total 3-layer 3x3 convolution in the CONV5 to a deformable convolution, which will convert the conv3, conv4, and conv5 in a total of 12 3x3 convolution layers to be deformable. convolution. V1 is found that the 3-layer deformable convolution is sufficient for PASCAL VOC. At the same time, the wrong deformation may hinder some more challenging Benchmark exploration. Author experiments found that uses deformable convolution in CONV3 to CONV5, which is the best equilibrium in efficiency and accuracy for Object Detection on COCO.△ PK, △ mk is learned by a convolution layer, so the number of channels of the convolution layer is 3N, where 2N represents ΔPK, which is the same as DCNV1, and the output of N channel is passed through the Sigmoid layer. The value mapped to [0, 1] is obtained to obtain △ mk.
Modulated Deformable Modules
V1 is only offset to the sampling point of ordinary convolution, and V2 also allows adjustment to adjust each sampling position or bin.Characterization gainHowever, the feature of this point is multiplied by a coefficient. If the coefficient is 0, it means that the feature of this part of the region has no effect on the output. This allows you to control the effective feelings.

From the experiment, increasing the number of dconv, the increase is still very obvious; but the number of modulated deformable modules has increased, and the performance enhancement is weak.
R-CNN Feature Mimicking
During the Detection training, if there is a lot of content in ROI, it may affect the extracted feature, thereby reducing the accuracy of the finally obtained model (but not, there is no extra context, plus, plus the performance here, weaken, So here, there is still something to think more.).
For V2, the adjustment coefficients other than ROI in ROILING can be used to remove unrelated context, but the experiment shows that this is still a good characteristic of ROI, which is due to the loss function of Faster R-CNN itself. Leading, there is therefore an additional supervision signal is required to improve the training of ROI feature extraction. due to,RCNN training is cropping ROI, using ROI training, thus greatly reduced the influence of independent regions on feature extraction. However, if the RCNN is introduced directly into the FASTERRCNN, the time of training and testing is greatly increased.
So the author uses Feature Mimicking means,Forcing ROI features in FASTER R-CNN can be close to the characteristics of R-CNN extraction. Introducing Feature MIMIC LOSS, it is desirable that the characteristics of networks are similar to the cropped image through RCNN, where the LOSS is set, and the COS similarity evaluation indicator is used.

The framework of network training is shown in the figure above.
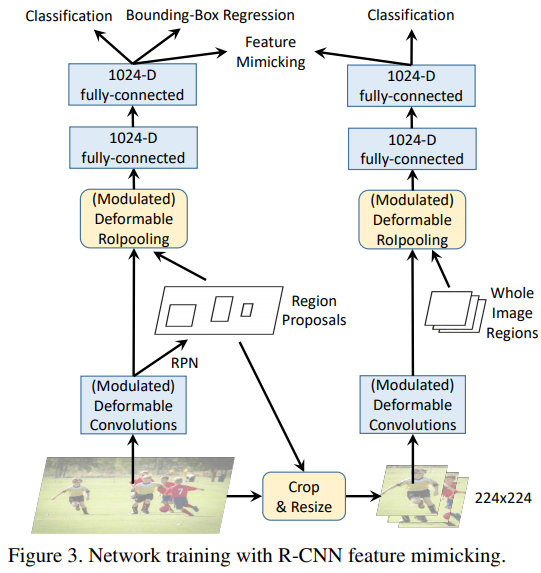
Although two networks are drawn, the same modules in the R-CNN and FASTER R-CNN are shared, such as the Modulated DEFORMABLE CONVOLUTION and MODULATED DEFORMABLE ROIPOOLING section. When INFERENCE, you only need to run the FASTER R-CNN. In this case, the increased computation is small.
Think
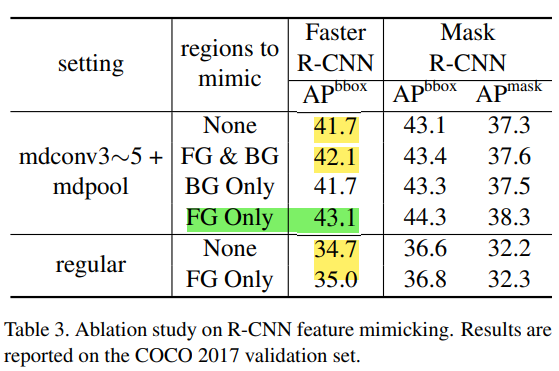
Look at the R-CNN Feature Mimicking Experiment:
- For positive samples on the foreground, use mimicking is especially useful. For negative sample background, the network tends to utilize more context information (Context), in which case mimicking doesn't help. So fg online is best
- On the Internet without MdConv, use MIMICKING's improvement amplitude is small, only 0.3 points. Here, the previous moduted deforbeable modules (there are fewer rise points, and the two will be slightly obvious) together:The improvement is only limited by modulated, mainly because the existing loss function is difficult to monitor the model to set less weightless regions, so the RCNN Feature Mimicking is introduced in the model training phase, providing effective via the RCNN network. Supervise the information, play the power role of modulation, making the extracted feature more concentrated in the effective area, so the rise points will be more obvious。If you can find a better learning mechanism for MODULATED DEFORMABLE CONVOLUTIONS, then I feel that MODULATED DEFORMABLE MODULES can also bring better performance improvement。
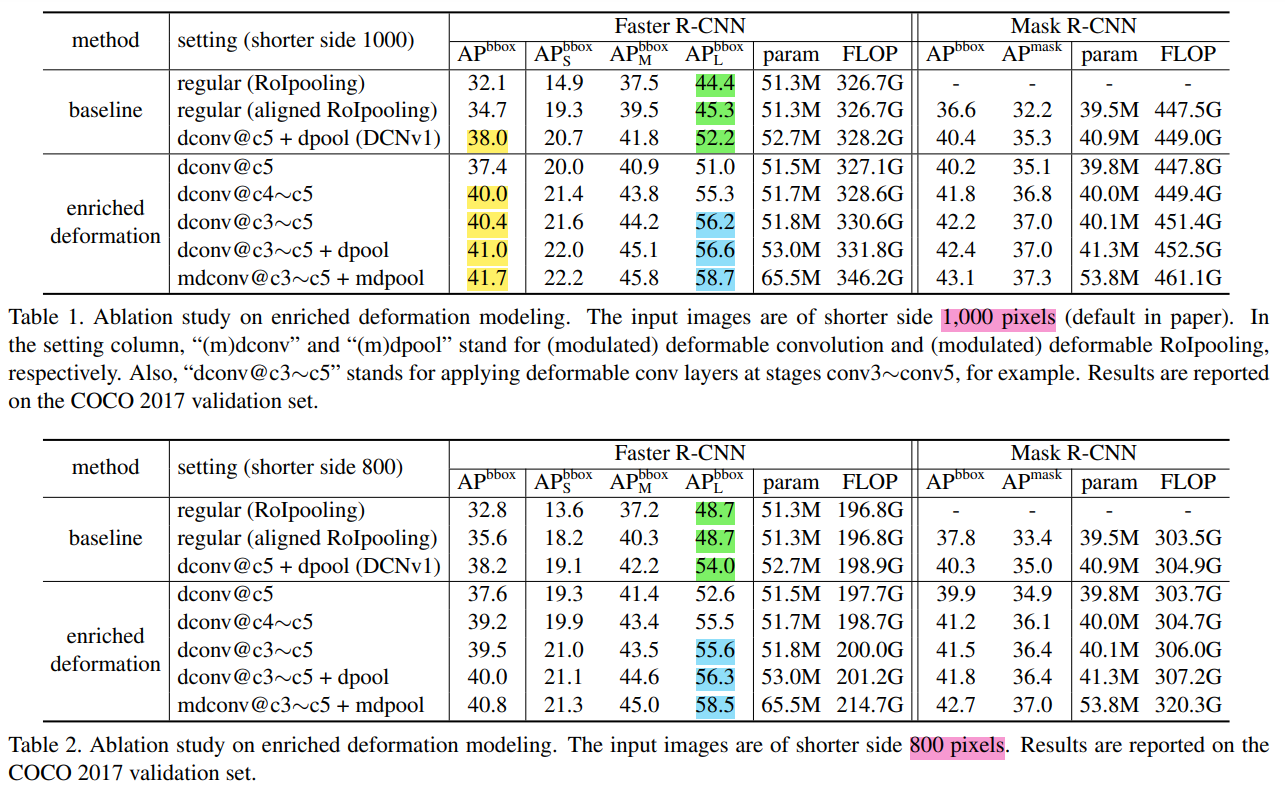
See some results on different scales:
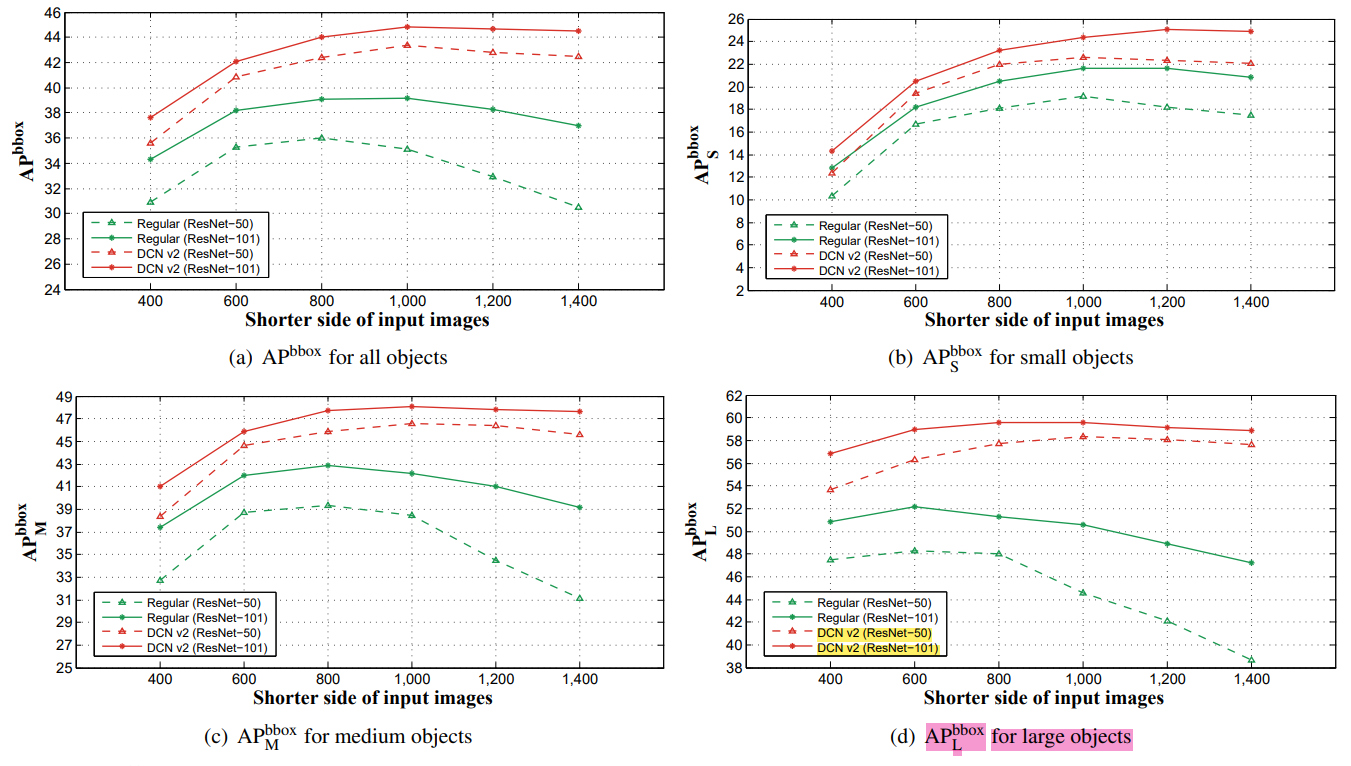
- APL: 800 -> 1000 does not add variable volume convolution (or addedNot enoughIt will also drop the point, it can be seen from the green blue part of the table below. [Small Object APsHourly, but deformable is related to the rise. Analysis: Put the picture adjustment to reduce the Receptive Field of the network, so the substitute has become very poor. Then this DCN still rises in the picture, and Performance is reasonable, because after all, it can dynamically adjust the perception of the field.
Personal point of view, welcome to exchange:
According to a reason, how many DCNs that should be several floors should be experimental to get the results, and should not be placed in V2, we will add a few layers to rose a lot (this paper is basically relying on this rose. ), Later saw one of the original author's answers is reasonable:

Link: https://www.zhihu.com/question/303900394
Modurated and feature mimicking points are very small, some people will think that these two are just a new idea for the Chinese, which seems to be more innovative. After all, the rise is to add several layers of DCONV. However, individuals think that the increase in gain coefficients to each perceptual wilderness is really innovative, and it is like consideration of the phase of the signal, and then needs to consider the amplitude, natural ideas. But why is the benefit? However, MODULATED and FEATURE MIMICKING have shown the effect? It feels that this gain factor lacks appropriate supervision information, the effect of training is not very good, joining Feature Mimicking can provide more better supervision information to make the gain factor learning.

Think about it, how can I learn more than the convolution better? From the front, △ pk, △ mk is learned through a convolution layer, then a convolution layer is not enough to learn so much parameters; if △ mk can join regularization when studying Method, because the places that need to focus on a feature map are limited, and it is not possible to pay attention to a location; do not add more supervision on each characterization, add a loss of gain factor
Welcome to exchange, prohibit reprint!
Previous:Target detection FPN
Intelligent Recommendation

Deformable ConvNets v2 algorithm notes
Paper: Deformable ConvNets v2: More Deformable, Better Results Link to the paper:https://arxiv.org/abs/1811.11168 This blog introduces a target detection article that I like very much: DCN v2, which i...

Deformable Convolutional Networks Deformable Convolutional Networks
Abstract Convolutional neural networks (CNNs) are inherently limited to model geometric transformations due to the fixed geometric structures in their building modules. The convolutional neural networ...

Deformable Convolutional Networks: Deformable Convolutional Networks
References: https://arxiv.org/abs/1703.06211 Code implementation: https://github.com/msracver/Deformable-ConvNets including understanding! Deformable Convolutional Networks Summary Convolutional neura...

Deformable Convolutional Networks Deformable Convolutional Networks Analysis
Deformable Convolutional Networks Article Directory Deformable Convolutional Networks 1. What is deformable convolution? 2. What problems does deformable convolution solve? 3. Specific implementation ...
Deformable Convolution Networks
Deformable Convolution Networks Papers link 1. Double linear interpolation principle Since the intramorable variable volume is acquired when the offset position pixel is acquired, it is necessary to u...
More Recommendation
Deformable Convolution Networks
CV Attention , 2017 CVPR Deformable ConvNets , article , Github PyTorch , …… 。 deformable convolution (4uiiurz1-pytorch ) and , 。 。 plain convolution operation: y ( p 0 ) = ∑ p n &is...

Deformable Convolutional Networks understands
The article turned to know: Deformable Convolutional Networks Paper link:https://arxiv.org/abs/1703.06211 code link:https://github.com/msracver/Deformable-ConvNets(Official implementation, but the rel...

Deformable Convolutional Networks translation
Deformable Convolutional Networks Abstract Convolutional neural networks (CNNs) are inherently limited to model geometric transformations due to the fixed geometric structures in their building module...
Deformable Convolutional Networks notes
Deformable Convolutional Networks (deformable volume and network) Article: https: //arxiv.org/abs/1703.06211link. Outline This work, the author introduces two new modules to enhance the modeling capab...
Deformable Convolutional Networks understand
Deformable-ConvNets the github link:https://github.com/msracver/Deformable-ConvNets This article reprinted from Microsoft Research AI headlines:Deformable convolution networks: new computer "as&q...