The "Singular" Momentum SGD Implementation in PyTorch
The momentum realization of SGD in pytorch is as follows
if momentum != 0:
param_state = self.state[p]
if 'momentum_buffer' not in param_state:
buf = param_state['momentum_buffer'] = d_p.clone()
else:
buf = param_state['momentum_buffer']
buf.mul_(momentum).add_(1 - dampening, d_p)
if nesterov:
d_p = d_p.add(momentum, buf)
else:
d_p = buf
p.data.add_(-group['lr'], d_p)
Translating the implementation of pytorch into a formula is like this:
Why is it so weird? Because it is different from the way in the papers of Polyak, Sutskever, etc.:
It is the learning rate and is the momentum factor.
Right, in fact, I changed my position and switched from the traditional one. However, in fact, through the expansion, it can be found that the two implementations are equivalent when the learning rate remains unchanged. In the case of a change in the learning rate, intuitively, the learning rate of the former method will immediately act on momentum:
makes the change in learning rate immediately effective, and the original method often requires several batches before the learning rate takes effect (because the momentum is too large).
So, in general, the implementation method used by pytorch will work.
[1]
[2]https://github.com/pytorch/pytorch/issues/1099
Reprinted at: https://www.jianshu.com/p/ee6a20a9ee41
Intelligent Recommendation
SGD、Momentum、 AdaGrad、Adam
table of Contents 1.SGD 1.1 SGD Disadvantages 2. Momentum 3. AdaGrad 4. Adam 5 Which update method is used? The purpose of the neural network learning is to find the value of the value of the loss fun...
Optimization Algorithm Optimization: SGD momentum Momentum
Momentum Motive In each iteration of SGD, the gradient decreases according to the current position of the independent, updates the argument along the gradient of the current position. However, if the ...
Pytorch-momentum
1. Momentum: (Momentum, Impulse): Combine the current gradient and the last update information for the current update; Second, the role of Momentum? Mainly when training the network, the network will ...
Comparison of SGD and Momentum of Python Handwriting Neural Network-"Introduction to Deep Learning-Theory and Implementation Based on Python (Chapter 6)"
Vanila SGD will not write first, it is very simple, mainly Momentum. Old rules, handwriting first, and then comparing books: In fact, this is really difficult to write the same, especially the ...
pytorch study: Law momentum Momentum
About momentum from the principle of the law is not written here, refer to other articles: Here is the code to achieve: ...
More Recommendation
Weight Update SGD Momentum AdaGrad RMSProp Adam
Foreword How to choose the appropriate weight update strategy after the back propagation propagation obtains the gradient is an important factor in the neural network training process. I learned sever...

Comparison of optimization algorithms such as SGD, Momentum, RMSProp, and Adam
Algorithm name formula Explanation Newton method θ t = θ t − 1 − H t − 1 − 1 ⋅ ▽ θ t − 1 J ( θ t − 1 ) \theta_t=\theta_{t-1}-H^{-1}_{t-...

Optimizer: SGD > Momentum > AdaGrad > RMSProp > Adam
table of Contents SGD stochastic gradient descent momentum AdaGrad RMSProp SGD stochastic gradient descent Here, SGD and min-batch mean the same thing. Take m small batches (independent and identicall...

Optimization algorithm in deep learning, SGD of Momentum
BeforeI introduced SGD (MINI-Batch Gradient Descent (MBGD), and sometimes when SGD is mentioned, it actually refers to MBGD). Here is the SGD of Momentum. SGD (Stochastic Gradient Descent) is difficul...
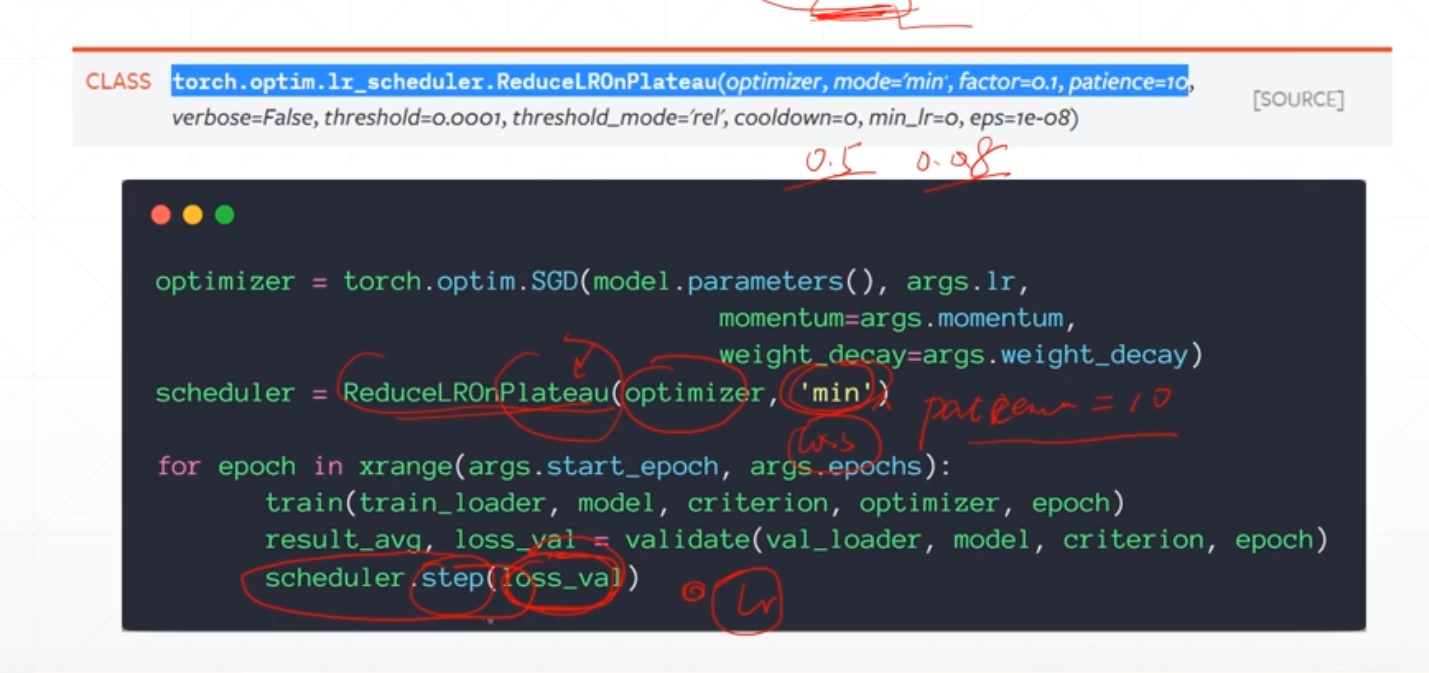
Pytorch: momentum and learning rate
(1) Momentum: Momentum can also be inertia ,go throughBecome In other words, the weight W is not only thinkingDirection attenuation, alsoThe direction of the direction is attenuated. Can be launchedBy...