Detailed explanation of Hbase client code connection
tags: hbase connection Connection connection pool
When many people use the client api for hbase connection, they will ask whether hbase has a connection pool and how to implement hbase connection pool. What's more, many beginners often have hbase connection numbers when developing hbase code The connection problems such as the limitation, in the final analysis, still don't know much about the connection object of hbase Connection, let's analyze the connection object of hbase in detail:
Common wrong ways to use Connection are:
(1) Implement the resource pool of a Connection object yourself, and each time you use it, take out a Connection object from the resource pool;
(2) One Connection object per thread.
(3) Each time you access HBase, temporarily create a Connection object, call close after use to close the connection.
From these practices, these users obviously use the Connection object as a connection object in a stand-alone database. However, as a distributed database, the HBase client needs to establish connections with different service roles in multiple servers, so the Connection object in the HBase client does not simply correspond to a socket connection. The definition of Connection in the HBase API document is:
A cluster connection encapsulating lower level individual connections to actual servers and a connection to zookeeper.
We know that HBase clients need to connect to three different service roles:
(1) Zookeeper: It is mainly used to obtain meta-region location, cluster Id, master and other information.
(2) HBase Master: It is mainly used to perform some operations of the HBaseAdmin interface, such as creating tables.
(3) HBase RegionServer: used to read and write data.
The following diagram simply illustrates the steps of client-server interaction:

The HBase client's Connection contains the encapsulation of the above three socket connections. The corresponding relationship between the Connection object and the actual socket connection is as follows:

In the HBase client code, the real connection to the socket is the RpcConnection object. HBase uses the data structure PoolMap to store the connection between the client and the HBase server. PoolMap encapsulates the structure of ConcurrentHashMap>, key is ConnectionId (encapsulates server address and user ticket), and value is a resource pool of RpcConnection objects. When HBase needs to connect to a server, it will first find the corresponding connection pool according to the ConnectionId, and then take a connection object from the connection pool.
HBase provides three resource pool implementations, namely Reusable, RoundRobin and ThreadLocal. The specific implementation can be specified through the hbase.client.ipc.pool.type configuration item, which is Reusable by default. The size of the connection pool can also be specified through the hbase.client.ipc.pool.size configuration item, which defaults to 1.
From the above analysis, it is not difficult to conclude that the Connection class in HBase has implemented the management function of the connection, so we do not need to do additional management on the Connection ourselves. In addition, Connection is thread-safe, and Table and Admin are not thread-safe, so the correct approach is to share a Connection object with a process, and use separate Table and Admin objects in different threads.
///All processes share a connection object
connection = ConnectionFactory.createConnection(config);
...
///Each thread uses a separate table object
Table table = connection.getTable(TableName.valueOf("test"));
try {
...
} finally {
table.close();
}The HBase client defaults to a connection pool size of 1, which means 1 connection per RegionServer. If the application needs to use a larger connection pool or specify other resource pool types, it can also be achieved by modifying the configuration:
config.set("hbase.client.ipc.pool.type",...);
config.set("hbase.client.ipc.pool.size",...);
connection = ConnectionFactory.createConnection(config);
...Intelligent Recommendation
HBase-RegionServer detailed explanation
1.RegionServer Overview A RegionServer consists of one (or more, only one by default) HLog, a BlockCache and multiple Regions: HLog guarantees high reliability of data writing Region is a data shard i...

detailed explanation of hbase architecture
1. What is HBAE (HBASE introduction)? 1. The prototype of HBase isGoogleofBigTableThe thesis, inspired by the thought of the paper, is currently developing and maintained as a sub -project of Hadoop t...
HBase-Client connection HBase prompt NoSuchColumnFamilyException
1. Use HBase-client to connect to the cluster HBase to report NoSuchColumnFamilyException. The online search data indicates that the client and the HBase version of the cluster do not correspond. Afte...
More Recommendation
Hbase client JAVA connection configuration
Hbase official has given the client sample code, there is a description in the Getting Started document, it will not be repeated. Here I want to tell you that the configuration of the remote connectio...
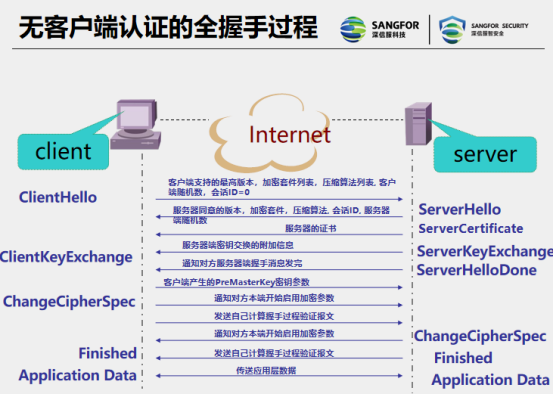
Basic knowledge of SSL and detailed explanation of whether there is a client connection process
Foreword: If you have any questions (including but not limited to this article, the network is available), please comment and discuss, and you will be answered if you can answer. Communicate with each...
Detailed explanation of Kafka (3) Client TCP connection management mechanism
1. Producer TCP link management 1.1 Overview of Kafka producer procedures The main object of Kafka's Java producer API is KafkaProducer. Usually we have 4 steps to develop a producer. The parameter ob...

WebSocket Android client implementation detailed explanation (1)-connection establishment and reconnection
The first requirement in the company this year is to write a client message center based on websocket. It has been online for a long time. On average, it reconnects 8 times a day in a network environm...
Redis Lettuce client asynchronous connection pool detailed explanation
Preface The asynchronous/non-blocking programming model requires a non-blocking API to get Redis connections. A blocked connection pool can easily lead to a state that blocks the event loop and preven...