The difference between L1 and L2 loss function and regularization
tags: Machine learning
This article was translated from the article:Differences between L1 and L2 as Loss Function and RegularizationIf there is any improper translation, welcome to make a brick, thank you~
In machine learning practice, you may need to make choices in the mysterious L1 and L2. The usual two decisions are: 1) L1 norm vs L2 norm loss function; 2) L1 regularization vs L2 regularization.
As a loss function
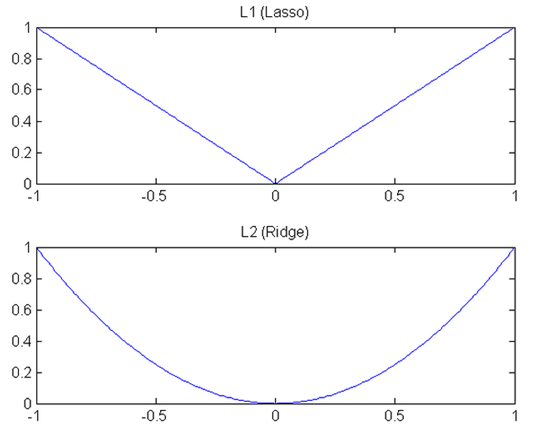
The L1 norm loss function, also known as the minimum absolute value deviation (LAD), the minimum absolute value error (LAE). In general, it is to put the target value ( ) with estimates ( The sum of the absolute differences ( ) )minimize:
The L2 norm loss function, also known as the least square error (LSE). In general, it is the target value ( ) with estimates ( The sum of the squares of the differences )minimize:
The difference between the L1 norm and the L2 norm as a loss function can be quickly summarized as follows:
| L2 loss function | L1 loss function |
|---|---|
| Not very robust (robust) | Robust |
| Stable solution | Unstable solution |
| Always a solution | Possible multiple solutions |
RobustnessAccording to Wikipedia, it is interpreted as:
Since the minimum absolute deviation method is more robust than the least squares, it is used in many applications. The minimum absolute value deviation is robust because it can handle outliers in the data. This may be useful in studies where outliers may be safely and effectively ignored. The minimum absolute deviation is a better choice if any or all of the outliers need to be considered.
Intuitively, because the L2 norm squares the error (if the error is greater than 1, the error will be much larger), the error of the model will be larger than the L1 norm (e vs e^2), so the model will sample this More sensitive, this requires adjusting the model to minimize errors. If the sample is an outlier, the model needs to be adjusted to accommodate a single outlier, which sacrifices many other normal samples because the error of these normal samples is less than the error of this single outlier.
stabilityAccording to Wikipedia, it is interpreted as:
The instability of the minimum absolute deviation method means that the regression line may jump a lot for a small horizontal fluctuation of the data set. On some data configurations, the method has many continuous solutions; however, a small movement of the data set skips many consecutive solutions of a data structure over a certain area. (The method has continuous solutions for some data configurations; however, by moving a datum a small amount, one could "jump past" a configuration which has multiple solutions that span a region.) After skipping the solution in this region, the minimum The absolute value deviation line may be more inclined than the previous line. Conversely, the solution of the least squares method is stable, because for any small fluctuation of a data point, the regression line will always only move slightly; that is, the regression parameter is a continuous function of the data set.
The following image is generated using real data and a real fit model:

The basic model used here is the Gradient Boosting Regressor, using the L1 norm and the L2 norm as the loss function. The green line and red represent the case when the model uses the L1 norm and the L2 norm as the loss function. The solid line represents the case where the trained model does not contain outliers (orange), and the dashed line represents the case where the trained model contains outliers (orange).
I slowly moved this outlier from left to right, making it less anomalous in the middle and more anomalous on the left and right. When this outlier is not so abnormal (in the middle case), the L2 norm changes less when fitting the line, and the L1 norm is larger.
When the outliers are more anomalous (upper left position, lower right position, they are further away from the left and right sides), both norms have large changes, but again The L1 norm is generally larger than the L2 norm.
Through data visualization, we are able to better understand the stability of these two loss functions.
As normalization
In machine learning, normalization is an important technique to prevent overfitting. Mathematically, it adds a regular term to prevent the coefficients from fitting too well to overfit. L1 differs from L2 only in that L2 is the sum of the squares of the weights, and L1 is the sum of the weights. as follows:
L1 regularization of the least squares loss function:

L2 regularization of the least squares loss function:

The differences in their nature can be quickly summarized as follows:
| L2 regularization | L1 regularization |
|---|---|
| High computational efficiency (because of analytical solutions) | Low computational efficiency in non-sparse situations |
| Non-sparse output | Sparse output |
| Featureless selection | Built-in feature selection |
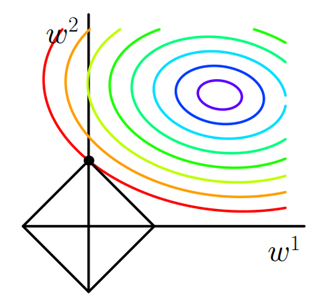
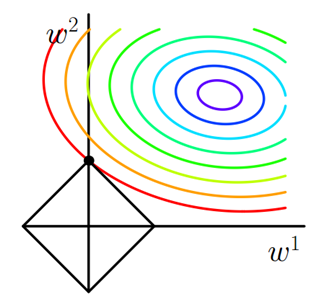
Uniqueness of solutionIt's a simpler nature, but it takes a little imagination. First, look at the picture below:

The green line (L2 norm) is the only shortest path, while the red, blue, and yellow lines (L1 norm) are the same path and the same length (12). It can be extended to the n-dimensional case. This is why the L2 norm has a unique solution and L1 is not.
Built-in feature selectionIt is a useful property that the L1 norm is often mentioned, and the L2 norm does not. This is a natural consequence of the L1 norm, which tends to produce sparse coefficients (explained later). Suppose the model has 100 coefficients, but only 10 of them are non-zero, which actually means that "the remaining 90 coefficients are useless when predicting the target value." The L2 norm produces a non-sparse coefficient, so it does not have this property.
SparsityIt means that only a few items in a matrix (or vector) are non-zero. The L1 norm has properties: it produces many zero or very small coefficients and a small number of large coefficients.
Computational efficiency. The L1 norm does not have an analytical solution, but the L2 norm has. This allows the L2 norm to be computationally efficient. However, the solution of the L1 norm is sparse, which allows it to use sparse algorithms to make calculations more efficient.
Intelligent Recommendation
L1, L2 Loss function and Regularization, and their implementation under Tensorflow framework
First talk about the L1 L2 loss: You can refer to this: Differences between l1 and l2 as loss function and regularization In the learning process of machine learning, you may choose to use L1 or L2. U...

Machine learning: norm regularization-L0, L1, L2 norm and loss function
L0, L1, L2 norm and loss function of norm regularization in machine learning The problem of supervised machine learning is nothing more than "minimize your error while regularizing your parameter...
The principle and difference of L1 and L2 regularization
The principle and difference of L1 and L2 regularization The purpose of regularization L0 and L1 norm L2 norm L1, L2 regularization difference Selection of regularization parameters reference is a not...

[AI interview] L1 loss, L2 loss and Smooth L1 Loss, L1 regularization and L2 regularization
The loss function is the soul basis of deep learning model optimization, so whether it is a very new transform model or the relatively early AlexNet, it is inevitable to involve the design and applica...
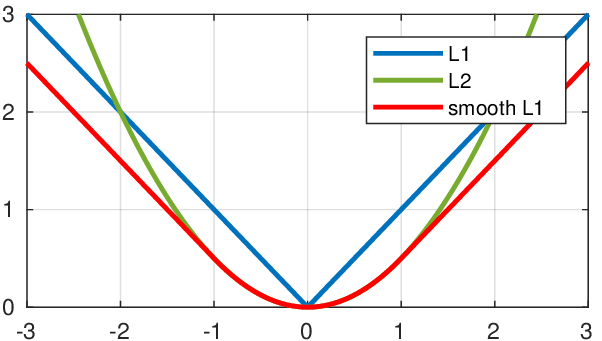
Deep learning loss function - L1 L2 Smoothl1 (Norm, loss function, regularization)
L1, L2, and SMOoth L1 are all three kinds of loss functions in deep learning, which have their own advantages and disadvantages and applicable scenes. First give a mathematical definition of each loss...
More Recommendation
Loss function - Gaussa's L1 regularization
L1 regularization is the decrease of the two sets of data, absolute value, and then the average Here, the two sets of data are subtracted, seek absolute value, Gaussian filter, and then see ave...
Algorithm questions often asked in machine learning interviews 1-the difference between L1 regularization and L2 regularization and why L1 regularization can produce sparse matrices, and L2 regularization can prevent overfitting**
One,The difference between L1 regularization and L2 regularization and why L1 regularization can produce a sparse matrix, L2 regularization can prevent overfitting Regularization (regularization): In ...

L1 regularization and L2 regularization
First, Occam razor(Occam's razor)principle: Among all the models that may be chosen, we should choose a model that is very good at interpreting the data and is very simple. From Bayesian perspective, ...
L1 and L2 Regularization Regularization
1. The norm is defined p norm: 1 norm: L1 corresponding regularization term: matrix w w w For example: ∑ i = 1 k ∣ w i ∣ \sum_{i=1}^k|w_i| i=1∑k∣wi∣ 2 norm: L2 corresponding regularization t...
On 15 --------- L0, L1, L2 regularization difference
1, the concept of L0 regularization parameter value is the number of non-zero parameters in the model. L1 represents a regularization absolute values of the respective parameters. L2 regularization ...