Poly-encoder
tags: text match natural language processing deep learning machine learning
Poly-encoder
Poly-encoder
The paper "Poly-encoders: Transformer Architectures and Pre-training Strategies for Fast and Accurate Multi-sentence Scoring" opens up a new transformer architecture, namely Poly-encoder.
Poly-encoder learns global rather than token-level self-attention features, and at the same time solves the problem of low matching quality of Bi-encoder and the slow matching speed of interactive cross-encoders such as ARC-II and BERT.
Bi-encoder
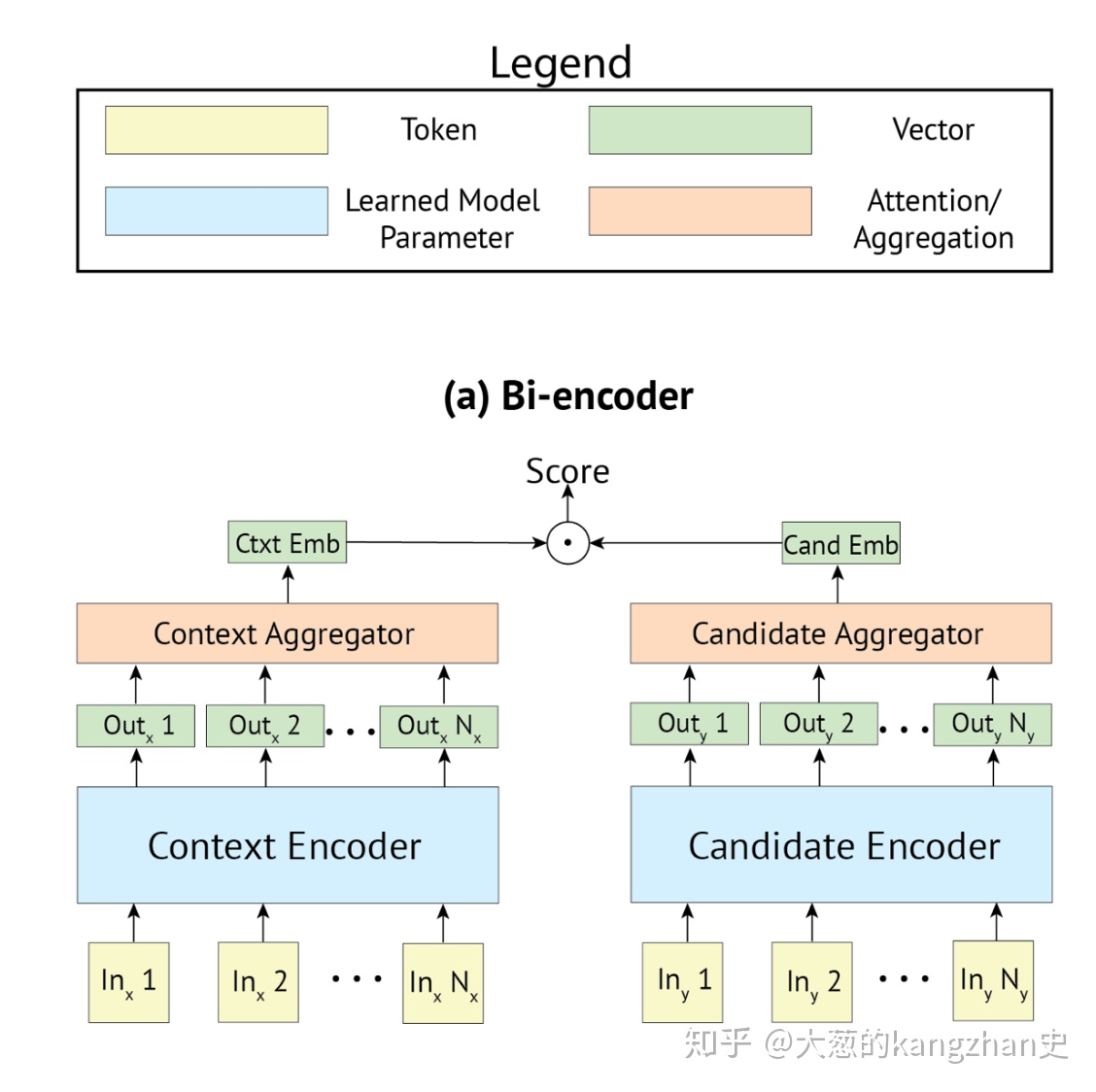
As shown in the figure, Bi-encoder uses two identical networks (such as BERT) to obtain the respective feature vectors of the two sentences, and then calculates the similarity.
-
Calculate the context vector: y c x t = r e d ( T 1 ( C T X T ) ) y_{cxt}=red(T_1(CTXT)) ycxt=red(T1(CTXT))
-
Calculate the candidate vector: y c a n d = r e d ( T 1 ( C A N D ) ) y_{cand}=red(T_1(CAND)) ycand=red(T1(CAND))
Three calculation methods of red():List item takes the vector of the first position (CLS)
Find the average of all position vectors
Find the average of the first n position vectors -
Similarity score: dot-product (dot product), ie s{CTXT, CAND}= y c x t ⋅ y c a n d y_{cxt} ·y_{cand} ycxt⋅ycand
-
Training, cross-entopy (cross entropy)
Generally speaking, two networks are used to encode context and candidate into vectors, and finally a similarity discriminant function (such as cosine, dot-product) is used to calculate the similarity between the two vectors.
The characteristic of Bi-encoder is that the process of encoding context and candidate into vectors is independent (the encoding process does not interact), and the interaction starts at the end. The speed is fast but the matching quality is not high.
Therefore, this independent encoding method allows us to calculate the vectors of all candidates offline. When serving online, we only need to calculate the vector of the query and then perform similarity matching. The matching speed is fast but the quality cannot reach the best.
cross-encoder
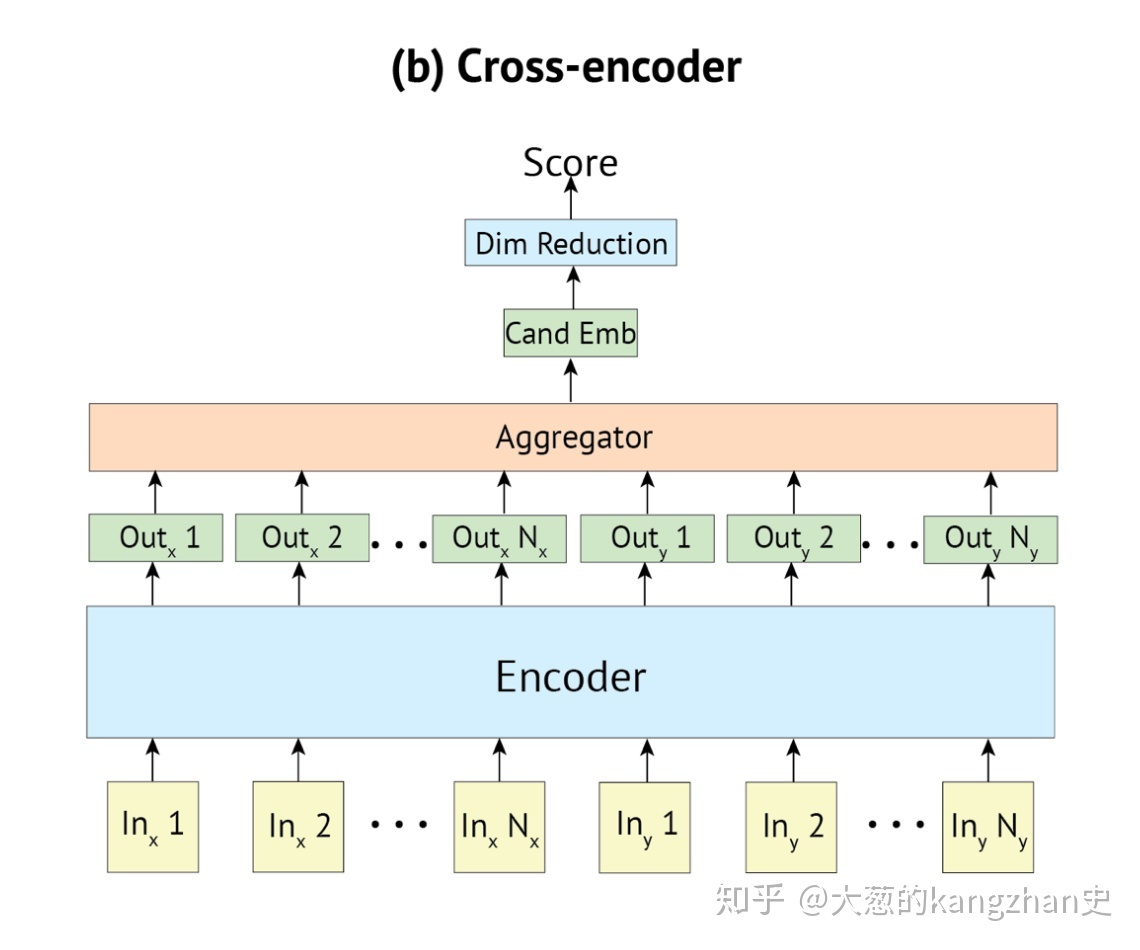 As shown in the picture:
As shown in the picture:
- Calculate the vector of context and candidate y c t x t , c a n d = h 1 = f i r s t ( T ( c t x t , c a n d ) ) y_{ctxt,cand}=h_1=first(T(ctxt,cand)) yctxt,cand=h1=first(T(ctxt,cand))
- Similarity score: s ( c t x t , c a n d ) = y c t x t , c a n d W s(ctxt,cand)=y_{ctxt,cand}W s(ctxt,cand)=yctxt,candW
- Training: cross-entopy (cross entropy).
The characteristic of cross-encoder is that the context and candidates are input into the consensus network structure, and the encoding process is completely interactive (that is, the context and candidates should interact with each other at all times), but the matching speed is slow, and the characterization vectors of all candidates cannot be calculated offline. Handling a context must interact with all candidates, and the model is very time-consuming.
poly-encoder
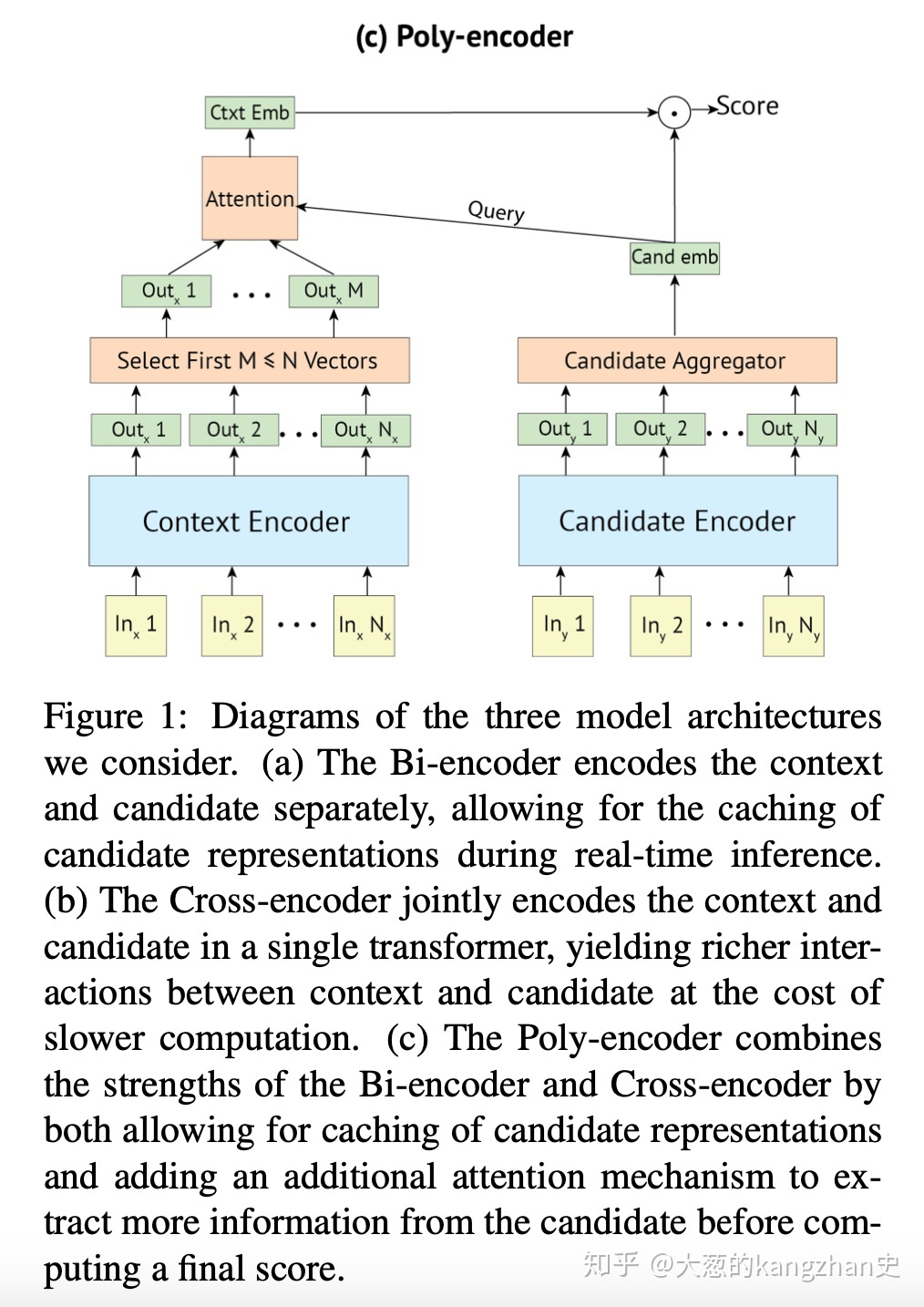
- Calculate the context vector
Use multiple vectors to represent context, (simplified version: go directly to the first m vectors) - Use an independent encoder to encode the representative features of the candidate.
- The two interact,
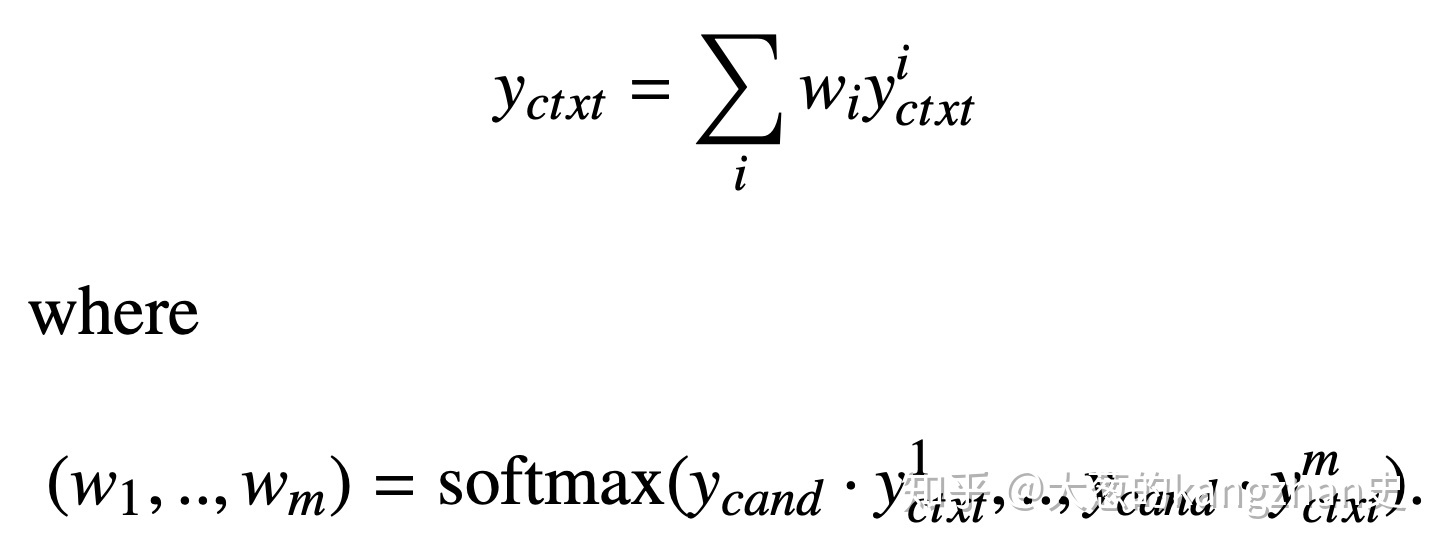
- Similarity score: dot-product.
Reference 1
Reference 2
Intelligent Recommendation
Poly Wide Source 52
The source code of the original strategy is as follows: #Strategy overview: With ROE as the screening criterion, select the stocks in the Shanghai and Shenzhen 300 that meet the conditions as the stoc...
Poly Wide Source 50
The source code of the original strategy is as follows: #RSRS indicator timing strategy Import function library from jqdata import * import pandas as pd import numpy as np from sklearn import linear_m...
Poly Wide Source 49
The source code of the original strategy is as follows: # Multi-factor backtest complete template (screening and trading conditions are stronger than ‘strategy generator’) import pandas as...
Poly Wide Source 45
The source code of the original strategy is as follows: # HS300 – Random forest turning point recognition import math import numpy as np import pandas as pd from pandas import DataFrame,Series i...
Poly Wide Source 43
The source code of the original strategy is as follows: Get API new skills, write strategies in research and backtest def initialize(context): set_params () # 1 Set policy parameters set_variables () ...
More Recommendation
Poly Wide Source 40
The source code of the original strategy is as follows: # Multi-factor model without model evaluation import pandas as pd import numpy as np import math from sklearn.svm import SVR from sklearn.model_...
Poly Wide Source 39
The source code of the original strategy is as follows: #Low valuation + TRIX + RSI low retracement strategy import jqdata Import talib library named tl import talib as tl Import numpy library named t...
Poly Wide Source 38
The source code of the original strategy is as follows: kdj index with accer filtering Import function library import jqdata import talib_real,bot_seller from jqlib.technical_analysis import * Initial...
Poly Wide Source 36
The source code of the original strategy is as follows: #Trend tracking strategy Import function library import jqdata import talib import pandas as pd import numpy as np import datetime from datetime...
Poly Wide Source 32
The source code of the original strategy is as follows: #Large market capitalization strategy from prettytable import PrettyTable import numpy as np import talib import pandas import scipy as sp impor...