linux-speed packet capture technology comparison --napi / libpcap / afpacket / pfring / dpdk
1. Traditional process linux stack performance and network protocol analyzer
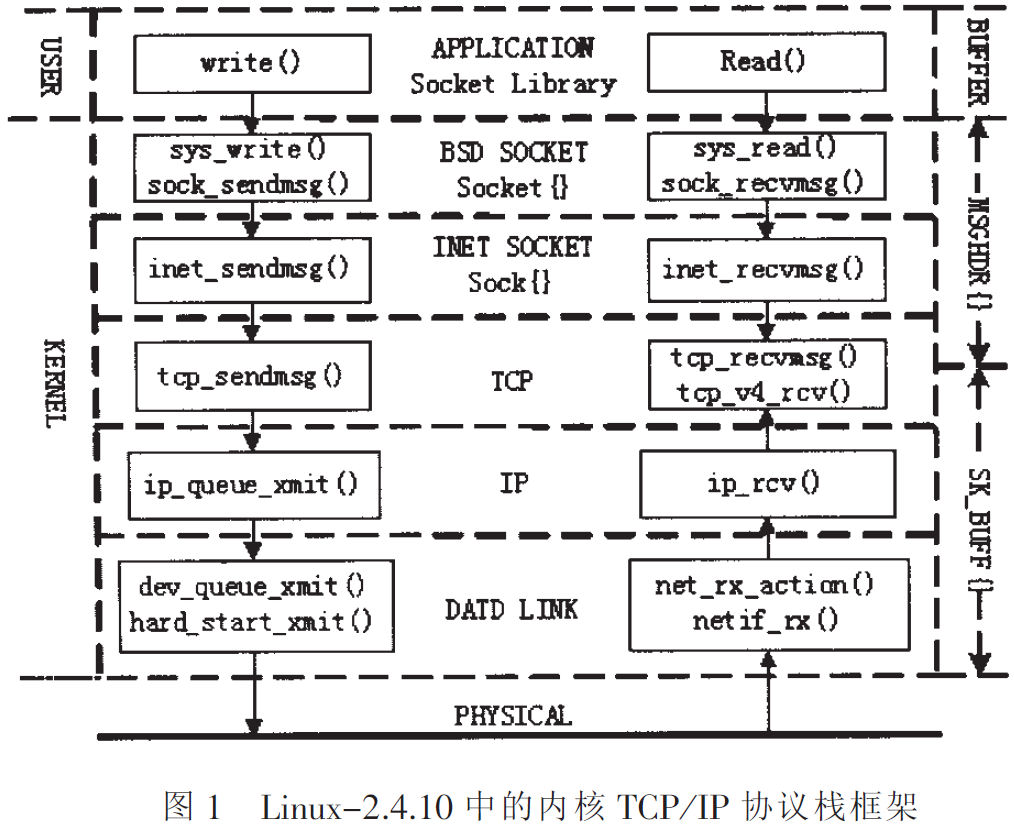
Linux network protocol stack processing system is a typical network data packet, which contains the whole process from the physical layer up to the application layer.

- Packet reaches the network card device.
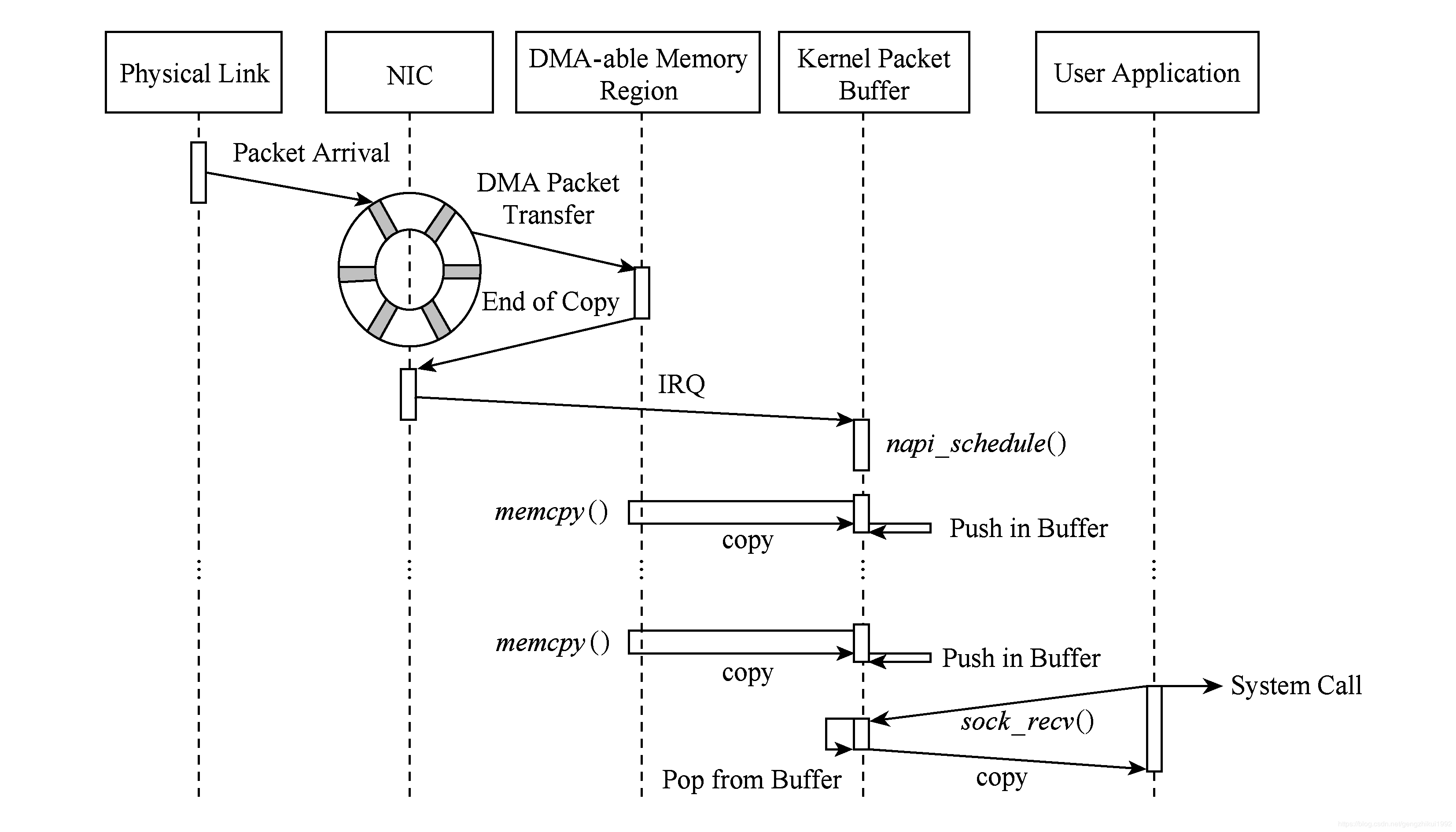
- LAN equipment based on configuration DMA operation. (1st copy: NIC Register -> network adapter allocated kernel buffer ring buffer)
- NIC transmit interrupt, wake up the processor.
- Driver software is read from the ring buffer, the filling skbuff core structure (The second copy: NIC kernel buffer ring buffer-> kernel specific data structures the skbuff)
- Data packets reach the kernel stack, perform high-level processing.
- socket system call to the user data are moved from the kernel mode. (The third copy: Kernel space -> user space)
The researchers found that, Linux kernel protocol stack of transmitting and receiving the data packet, the overhead time of memory copy operations accounted for 65% of the whole process time overhead, in addition to the interlayer transfer system call time is accounted for 8% to 10% .
The main problem of the protocol stack:
-
Resource allocation and release for a single packet level
whenever a packet arrives at the network card, the system will allocate a descriptor for the packet header information and storing the data packet until the packet is transmitted to the user the state space, which was only descriptor freed. In addition, most of the information sk_buff huge data structure for most network tasks concerned are useless. -
Serial traffic of
modern NIC different receive queue comprises a plurality of receiving terminal extension hardware (receiver-side scaling, RSS) allocated in the packet queue may be a hash function to the five-tuple. Using this technique, the packet capture process can be parallelized because each RSS queue may be mapped to a particular CPU core, and may correspond to a respective NAPI thread. So that the entire capture process can be done parallelization.
but above the level of the problem, in the Linux protocol stack network layer and the transport layer need to analyze all packets combined
① all traffic is processed in a single module, create a performance bottleneck;
② user process is unable to receive messages from a single queue RSS.
This results in the parallel processing capabilities of an upper layer application can not use modern hardware, which reduces the performance of the system during the user mode sequence assigned traffic has lost the driving level obtained accelerate.
In addition, there may be additional packets out of sequence from the combined flow rate of the different queues -
Copy data from the driver to the user mode
Process data packets received from the card to the removal of the application data, the presence of at least 2 times copy packet -
User space to the kernel context switching
from the perspective of the application point of view, it needs to perform a system call to receive each packet. Each context switch comprises a system call from a user mode kernel mode, followed by a lot of CPU time consumption. perform a context switch occurs when the system call may consume nearly 000 CPU cycles on each packet. -
Cross-Memory Access
For example, when receiving a packet 64 B, cache misses result in an additional consumption of 13.8% of the CPU cycles. Further, based on the NUMA system, memory access time is dependent on a access the storage node. Therefore, cache miss access memory blocks across environment leads to greater memory access latency, resulting in performance degradation.
2. improve capture efficiency technology
Today's high performance packet capture engine commonly used to improve the capture efficiency technologies that can overcome the performance limitations of previous architecture.
-
And reuse pre-allocated memory resources
Such techniques include:
before the start of packet reception, the desired preallocated packet to reach the memory space used to store data and metadata (packet descriptors). Embodied in particular, the NIC driver loading when the allocation descriptor queue of N well (each hardware device and a queue).Similarly, when a data packet is transmitted to the user space, the corresponding descriptor is not released, but again for the newly arrived packet storage. Thanks to this strategy, each packet allocation / release of to the performance bottleneck has been eliminated. Further, the memory overhead may be reduced by simplifying the data structure of sk_buff.
-
Direct access data packets using parallel transfer.
To solve the sequence of traffic, the need for the queue directly from the RSS to the parallel data path between the application. This particular technique RSS queue, application specific CPU core and the three binding to achieve improved performance.This technique also has some disadvantages:
① packets may arrive out of order the user mode, thus affecting the performance of some applications;
②RSS using the Hash function to distribute traffic between each of the receive queue when there is no mutual correlation between different nuclei of data packets, which can be analyzed independently, but the roundtrip packets if the same stream when are assigned to different CPU cores, it will cause inefficient access across the nucleus. -
Memory map.
Using this method, the memory area of the application can be mapped to kernel mode memory region, the application can read and write this memory area in the case where no intermediate copies.
This way we can directly access the DMA memory card application area, a technique known as zero-copy, but also zero-copy potential security problem, the card is exposed to the application circular queue registers and can affect the safety and stability of the system. -
Batch packet.
To avoid the overhead of repeated operations for each packet may be used to batch process the packet.This strategy packet into groups, allocating a buffer in groups, to copy them together with the kernel / user memory using this technique reduces the number of system calls and context switches attendant; while also reducing the copy times, thereby reducing the processing and replication in equal shares to each packet overhead.
but the packet must wait until the batch is full or a major problem will be submitted to the upper timer expires, batch processing and an increase in jitter is the delay time stamp packet receiving error. -
Affinity for prefetching.
running because the principle of locality, allocate memory for the process must be consistent with the operation of the processor is executing its block of memory, this technique is calledMemory affinity.
CPU affinityIt is a technology that allows a process or thread running on the specified processor core.
and the kernel driver level software and hardware interrupts CPU core shall be designated by the same processor or processing method, calledInterrupt affinityEach time a thread wishes to access the received data, if such data has previously been assigned to the same CPU interrupt handler receives the core, they can be more easily accessible to the local Cache.
3. Typical received packet engine
3.1 libpcap
Libpcap packet capture is increased in a bypass data link layer processing, the processing system itself does not interfere with network protocol stack, sending and receiving packets through buffering and filtering to make the Linux kernel, and finally passed to the upper layer directly application.

3.2 libpcap-mmap
libpcap libpcap-mmap is an improvement on the old implementation of the new version of libpcap have adopted the basic packet_mmap mechanism. PACKET_MMAP by mmap, reducing a memory copy, greatly improving the efficiency of packet capture.
Process analysis:
tpacket_rcv PACKET_MMAP to achieve, packet_rcv achieve the common AF_PACKET.
tpacket_rcv:
-
Some carried out the necessary checks
-
Run run_filter, through the BPF filter, we set the conditions for the message, get the length you need to capture snaplen
-
Find TP_STATUS_KERNEL in the ring buffer in the frame
-
Calculating macoff, netoff information
-
If snaplen + macoff> frame_size, and skb is shared, then the copy skb <generally not copied>
if(skb_shared(skb))
skb_clone() -
Skb to copy data from the kernel Buffer <copy>
skb_copy_bits(skb, 0, h.raw+macoff, snaplen); -
Provided copied to the header information packets of the frame, it includes a timestamp, length, status information
-
flush_dcache_page () the contents of a page in the data cache is synchronized back into memory.
x86 should do this, this is a multi-use RISC architecture -
Call sk_data_ready, sleep notification process, invoke poll
-
The application layer poll after the call returns, it will call pcap_get_ring_frame get a frame for processing. There is no copy and no system calls.
Cost analysis: 1 copy of the system call +1 (poll)
packet_rcv:
-
Some carried out the necessary checks
-
Run run_filter, through the BPF filter, we set the conditions for the message, get the length you need to capture snaplen
-
If skb is shared, then copy skb <usually copy>
if(skb_shared(skb))
skb_clone() -
Provided copied to the header information packets of the frame, it includes a timestamp, length, status information
-
Skb will be appended to the socket in the sk_receive_queue
-
Call sk_data_ready, sleep notification process data arrives
-
The application layer in the recvfrom sleep, when the data arrives, socket readable when the call packet_recvmsg, wherein the data is copied to the user space. <Copy>
skb_recv_datagram () obtained from sk_receive_queue the skb
skb_copy_datagram_iovec () to copy the data to the user spaceCost analysis: 2 copies of the system call +1 (recvfrom)
3.3 PF_RING noZC
Similar libpcap-mmap


3.4 PF_RING ZC
PF-RING ZC achieve a complete copy of zero, it will drive the user memory space is mapped into the memory space of the data register and the application can directly access the card user. In this way, the collation is avoided inner packet buffer, reducing the number of copies of the packet.

3.5 DPDK
Similarly pfring_zc, Intel DPDK process allows the user direct access to space using a library card DPDK provided without going through the kernel.
compared pfring_zc, dpdk in the packet processing, higher performance.
4. The lock-free queue Technology
In the packet capture process, lock-free queue is a very important data structure. Producer (NIC) write data and consumer (user mode program) to read data, not locking, can greatly improve efficiency.
Lock-free queue implementation techniques are mainly dependent on:
-
CAS atomic instruction operation
CAS (Compare and Swap, Compare and replace) the atomic instruction, to protect the data consistency.
instruction has three parameters, the current memory value V, the old expected value A, the updated value B, when and only when the anticipated value A memory value V are the same, the memory value is modified as B and returns true, otherwise do nothing and returns false. -
Memory barrier
when the operation is performed, each CPU core reads from memory the respective cache, after the end of the update from the cache memory, which may cause inter-thread data is not synchronized, so the memory required barrier forced the write data buffer or cache write-back to main memory.
is divided into a read barrier and write barrier: barrier allows data read in the cache fails, the forced re-load data from main memory;
write barrier can update data in the cache is written to main memory.
in the implementation valotitle keywords to use the memory barrier, so as to ensure thread A modification of this variable, the value of the latest value of the acquired other threads.
reference:
http://crad.ict.ac.cn/fileup/HTML/2017-6-1300.shtml
https://coolshell.cn/articles/8239.html
https://cloud.tencent.com/developer/article/1521276
https://blog.csdn.net/dandelionj/article/details/16980571
https://my.oschina.net/moooofly/blog/898798
Intelligent Recommendation
libpcap packet capture library multiple network adapters
Install libpcap library First, install the associated support environment Then download the latest version of libpcap, Download:http://www.tcpdump.org/。 Decompression, enter the following command in t...
IP packet capture library use Libpcap LAN
Experimental requirements Source and destination physical address of the print data packet; Print source IP and destination IP address; Printing upper layer protocol type; If the upper layer protocol ...

libpcap packet capture analysis project (2)
In project (1), we successfully captured the data packet and extracted the basic information in the data packet. This time we will output the various protocols used by the data packet and output the m...

libpcap packet capture analysis project (1)
First introduce the usage of libpcap library functions: Here I use two functions, pcap_open_live () and pcap_next (), you can jump through the portal to see the specific usage. The comments in the cod...

libpcap packet capture analysis project (4)
In project three, we completed the parsing of a package in the "hospital mirror stream.pcapng" file. The next thing we need to do is to write the parsed data into the file, so that the TS st...
More Recommendation
Analysis of libpcap packet capture mechanism (3)
At present, the network packet capture system under the Linux operating system is generally built on the libpcap packet capture platform. The English meaning of libpcap is Library of Packet Capture, t...
Analysis of libpcap packet capture mechanism (4)
1. Process and performance analysis of traditional Linux network protocol stack The Linux network protocol stack is a typical system for processing network packets. It includes the entire process from...
libpcap network packet capture function library
download Compile and install Instance The C function interface provided by the library is used to capture data packets passing through the specified network interface. download: http://www.linuxfromsc...

Linux data packet NAPI processing flow
Linux data packet NAPI processing flow 1. Concept NAPI: Linux's new network card packet processing API, using a new packet processing process. round-robin: Round-robin scheduling algorithm. Hard inter...

Network packet capture function library Libpcap installation and use (very powerful)
1. Introduction to Libpcap Libpcap is the abbreviation of Packet Capture Libray, which is the data packet capture function library. The C function interface provided by the library is used to capture...