Deep learning 21 days of actual combat caffe study notes "5: Mnist handwriting recognition case"
Mnist handwriting recognition case
Detailed source code
MNIST
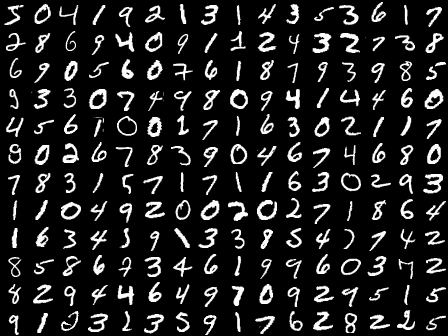
data set
Use the get_mnist.sh script to download under data/mnist in the Caffe source code directory.
$ cd data/mnist/
$ ./get_mnist.shmnist data format description:
There are four more files in the data/mnist directory
| file name | Description |
|---|---|
| train-images-idx3-ubyte | Training set, picture |
| train-labels-idx1-ubyte | Training set, label |
| t10k-images-idx3-ubyte | Test set, picture |
| t10k-labels-idx1-ubyte | Test set, label |

The format of test images and training images is the same;
Conversion format
The pixels in the picture file are organized in rows, white (pixel value 0) is the background, and black (pixel value 255) is the foreground;
The downloaded data set is a binary file and needs to be converted to LMDB or LEVELDB to be recognized by Caffe.
$ ./examples/mnist/create_mnist.sh
Creating lmdb...
Done.Two directories, mnist_train_lmdb/ and mnist_test_lmdb/, are generated in the examples/mnist directory, and there are two files in each directory: data.mdb and lock.mdb. Mnist_train_lmdb is a training set in LMDB format, and mnist_test_lmdb is a test set in LMDB format.
tips:
Caffe uses LMDB and LEVELDB for reason 1: to provide a unified data type format; reason 2: to improve disk IO utilization;
Network model
Review: Lenet's network structure (proto configuration)examples/mnist/lenet_solver.prototxt
Training network
tips: Be sure to read the printed log;
GLOG output format: date, time, process number, source file: code line number] output information;
It is convenient to track the remote operation process and analyze the operation efficiency;
CPU mode: the last line of examples/mnist/lenet_solver.prototxt is modified as follows
# solver mode: CPU or GPU
solver_mode: CPURun the examples/mnist/train_lenet.sh script
$ ./examples/mnist/train_lenet.sh The final result of training is saved in examples/mnist/lenet_iter_10000.caffemodel.
test
Use the MNIST test set to test the trained model
$ ./build/tools/caffe.bin test \
-model examples/mnist/lenet_train_test.prototxt \
-weights examples/mnist/lenet_iter_10000.caffemodel \
-iterations 100Command line parameters:
- ./build/tools/caffe.bin test means that only prediction (forward propagation) is made, and no parameter update is made;
- -model examples/mnist/lenet_train_test.prototxt specifies the model description file
- -weights examples/mnist/lenet_iter_10000.caffemodel specifies the trained weight file
- iterations 100 Specify the number of test iterations, the number of participating tests=iterations*batch_size, the data volume of each iteration is set batch_size: 100 in the model description file, and 100 iterations just cover 10000 samples of the test set.

You can look at the source file!
Intelligent Recommendation

21 days of deep learning actual caffe study notes "2: deep learning tools"
Summary of deep learning tools 1. Caffe【Convolutional Architecture for Fast Feature Embedding】 —Convolutional neural network based on C++/CUDA/Python implementation, providing command line, matl...

21 days of deep learning actual caffe study notes "1: the past of deep learning"
1. Deep learning DL: 1.1, Supervised learning, unsupervised learning, overfitting, training samples, generalization, training set, validation set, test set These knowledge related to deep learning nee...

Deep learning 21 days combat caffe three days before notes
This article is used as a memo for "Deep Learning 21-Day Practical Caffe Notes", please use it in conjunction with the original book~ Foreword The Caffe framework provides a high degree of a...
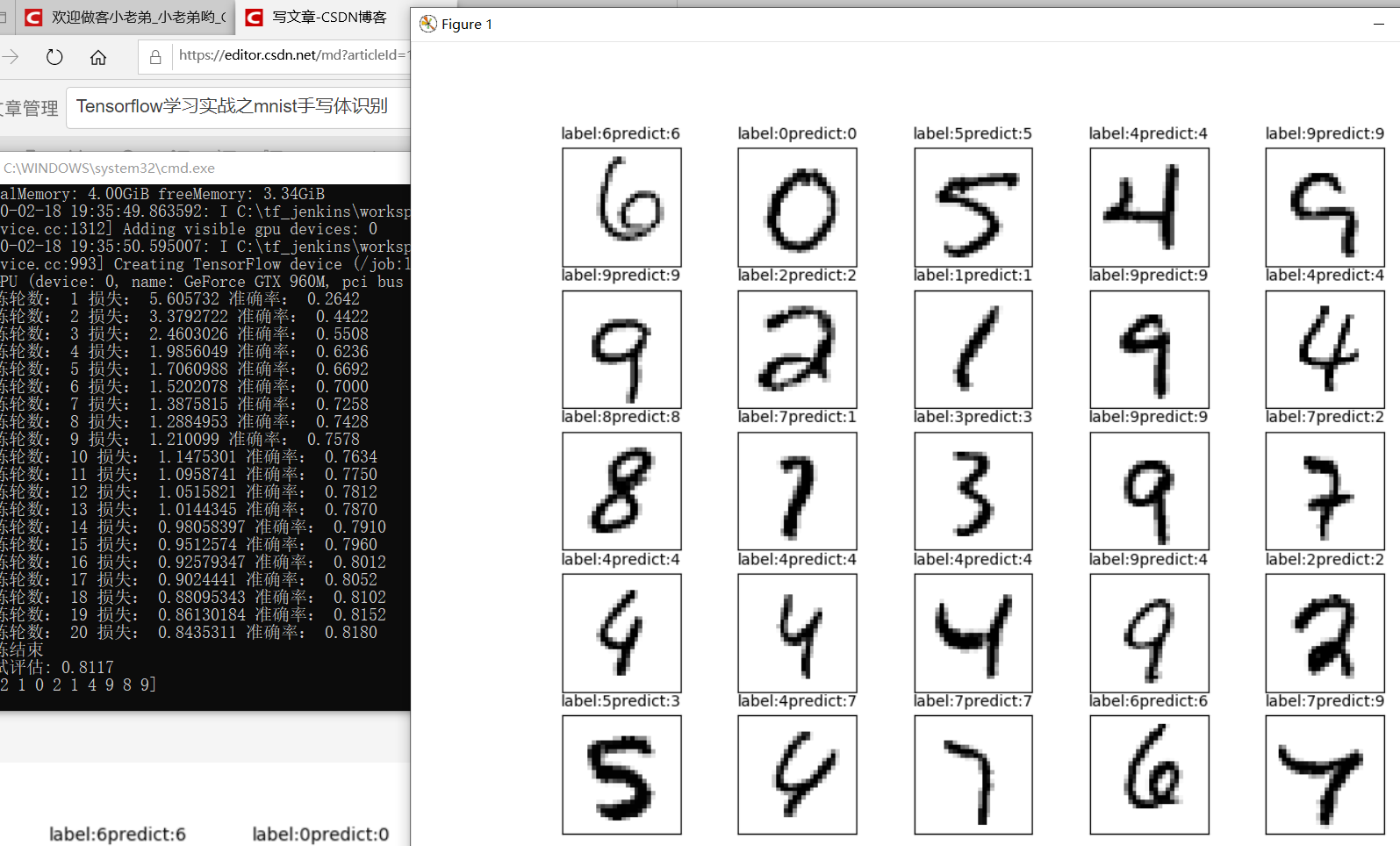
Tensorflow learning actual combat mnist handwriting recognition
Tensorflow learning actual combat mnist handwriting recognition data preparation Build model Training model evaluation result Visual display Tensorflow continues to study, today is the entry-level mni...

"21 days of actual combat caffe" 1-7 days study notes 1
Recently, I was forced to look at the caffe source code by my instructor, and I followed "21 days of caffe" to summarize some of the problems encountered. I especially call the author here. ...
More Recommendation
[Pytorch actual combat (5)] realize MNIST handwriting recognition
One, MNIST data set MNIST data set addresshttp://yann.lecun.com/exdb/mnist/ The data set contains 6w training set pictures and 1w test set pictures Second, realize MNIST handwriting recognition 1. Dow...
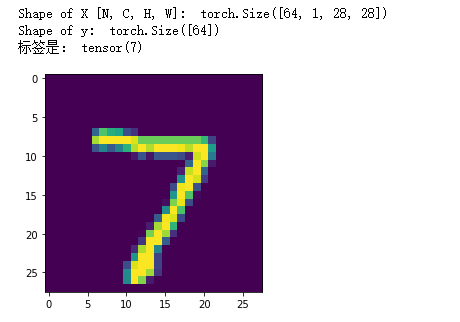
Deep learning actual combat - handwriting word identification mnist
Handwriting word recognition Introduction to Python. Handwritten word identification is a deep learning entry tutorial, which includes several modules of data download, model c...
Caffe learning example (1) mnist handwriting recognition
The simple operation process is as follows: 1. Download data (Run the script to download and convert the data format from the MNIST website) Use the get_mnist.sh script to download under data/mnist in...
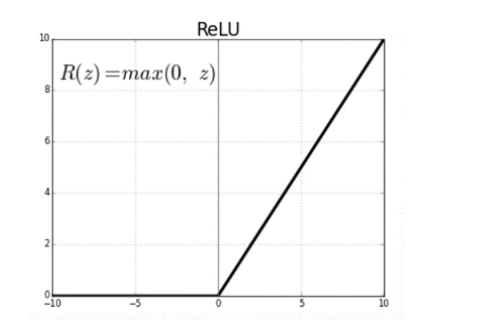
[PyTorch study notes] Start MNIST handwriting recognition digital combat
Classification problem Image representation The size of each picture of handwritten digits in MNIST is28×28 single channel picture We can take this picturetieInto one long degree for 784 Length ...