Analysis of libpcap packet capture mechanism (4)
tags: system
1. Process and performance analysis of traditional Linux network protocol stack
The Linux network protocol stack is a typical system for processing network packets. It includes the entire process from the physical layer to the application layer.
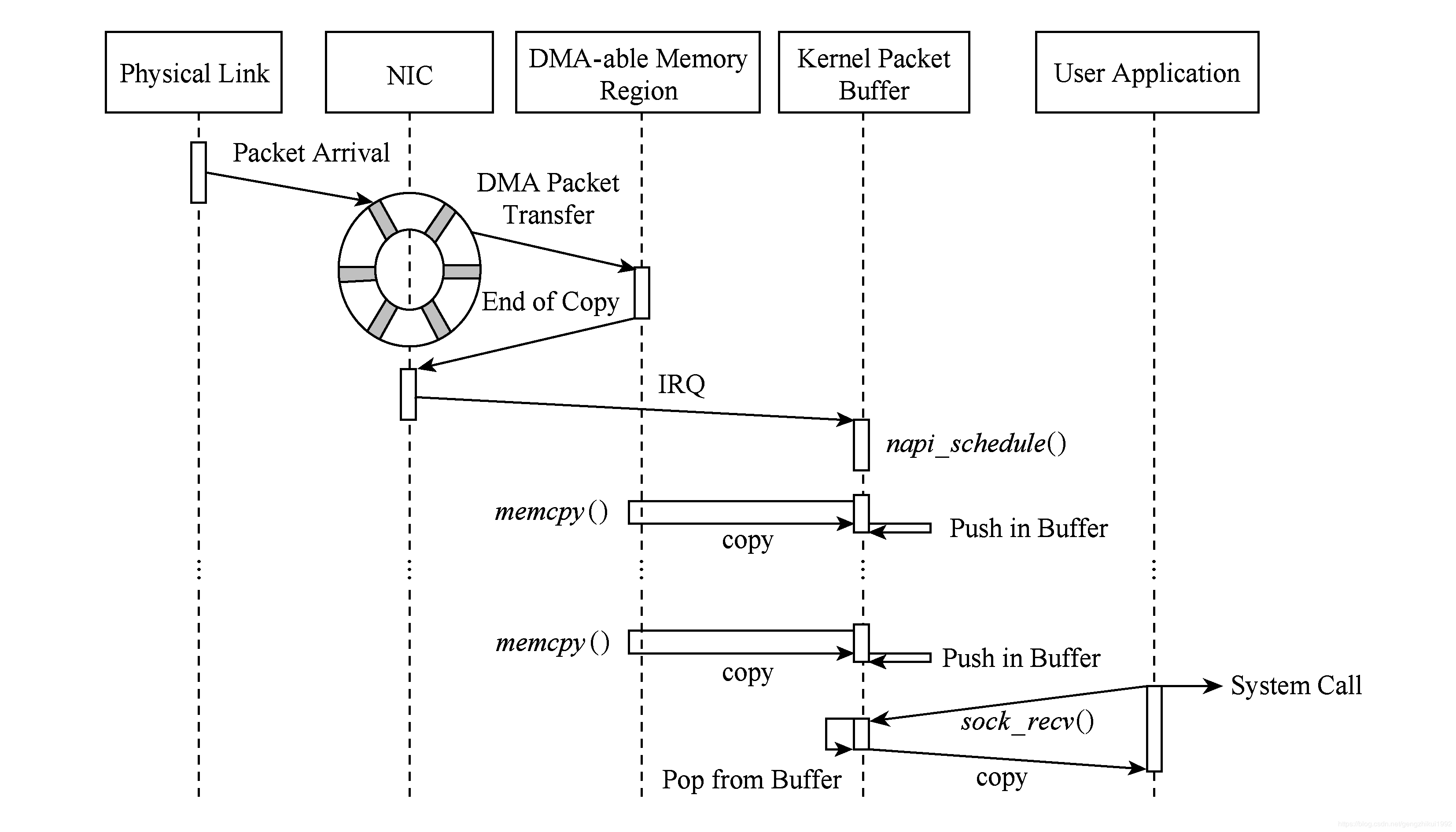
- The data packet reaches the network card device.
- The network card device performs DMA operation according to the configuration. (1st copy: NIC register -> the buffer ring buffer allocated by the kernel for the NIC)
- The network card sends an interrupt to wake up the processor.
- The driver software reads from the ring buffer and fills the kernel skbuff structure (2nd copy: Kernel network card buffer ring buffer->kernel special data structure skbuff)
- The data message reaches the kernel protocol stack and performs high-level processing.
- The socket system call moves data from the kernel to user mode. (3rd copy: Kernel space -> user space)
Researchers have found that in the process of sending and receiving data packets in the Linux kernel protocol stack, the time overhead of memory copy operations accounts for 65% of the entire processing time overhead. In addition, the system call time passed between layers also accounts for 8% to 10% .
The main problems of the protocol stack:
1. Resource allocation and release for a single packet level
Whenever a data packet arrives at the network card, the system allocates a packet descriptor to store the information and header of the data packet. Until the packet is transferred to the user state space, its descriptor is not freed. In addition, most of the information in the huge data structure of sk_buff is useless for most network tasks.
2. Serial access to traffic
Modern network cards include multiple hardware receiver-side scaling (RSS) queues that can assign packets to different receive queues according to the quintuple hash function. Using this technique, the packet capture process can be parallelized, because each RSS queue can be mapped to a specific CPU core, and can correspond to the corresponding NAPI thread. In this way, the entire capture process can be parallelized.
But the problem appears at the upper level. The protocol stack in Linux needs to analyze all the combined data packets at the network layer and the transport layer.
- All traffic is processed in a single module, creating a performance bottleneck;
- User processes cannot receive messages from a single RSS queue.
This makes it impossible for upper-layer applications to take advantage of the parallel processing capabilities of modern hardware. This process of allocating traffic sequences in user mode reduces the performance of the system and loses the acceleration obtained at the driver level.
In addition, traffic merged from different queues may generate additional out-of-order packets
3. Data copy from drive to user mode
There are at least 2 copies of the data packet from the time the network card receives the data packet to when the application takes the data
4. Context switch from kernel to user space
From the perspective of the application, it needs to execute a system call to receive each packet. Each system call includes a context switch from user mode to kernel mode, and the ensuing It is a lot of CPU time consumption. The context switch generated when the system call is executed on each packet may consume nearly 1,000 CPU cycles.
5. Cross-memory access
For example, when receiving a 64 B packet, a cache miss caused an additional 13.8% of CPU cycles. In addition, in a NUMA-based system, the memory access time depends on The storage node being accessed. Therefore, a cache miss in the cross-memory block access environment will cause a greater memory access delay, resulting in reduced performance.
2. Technology to improve capture efficiency
The techniques commonly used in current high-performance packet capture engines to improve capture efficiency can overcome the performance limitations of previous architectures.
1. Pre-allocate and reuse memory resources
This technology includes:
Before starting packet reception, pre-allocate the memory space required for the arriving packets to store data and metadata (packet descriptors). This is particularly reflected in the fact that N descriptor queues are allocated when the network card driver is loaded ( One for each hardware queue and device).
Similarly, when a packet is transferred to user space, its corresponding descriptor will not be released, but will be re-used to store newly arrived packets. Thanks to this strategy, each packet is allocated/released The resulting performance bottlenecks have been eliminated. In addition, memory overhead can be reduced by simplifying the sk_buff data structure.
2. Data packets are transmitted in parallel direct channels.
In order to solve the serialized access traffic, it is necessary to establish a direct parallel data channel from the RSS queue to the application. This technology achieves performance improvement through the binding of a specific RSS queue, a specific CPU core, and an application.
This technique also has some disadvantages:
- Data packets may arrive in user mode out of order, thereby affecting the performance of some applications;
- RSS uses the Hash function to distribute traffic between each receiving queue. When the data packets of different cores are not correlated with each other, they can be analyzed independently, but if the round-trip data packets of the same flow are distributed to different CPU cores, This will result in inefficient cross-core access.
3. Memory mapping.
Using this method, the memory area of the application can be mapped to the memory area of the kernel mode, and the application can read and write this memory area without an intermediate copy.
In this way, we can make the application directly access the DMA memory area of the network card. This technique is called zero copy. However, zero copy also has potential security issues. Exposing the network card ring queue and registers to the application will affect the security of the system. And stability.
4. Batch processing of data packets.
In order to avoid the overhead of repeated operations on each packet, you can use batch processing of packets.
This strategy divides the data packets into groups, allocates buffers according to groups, and copies them to the kernel/user memory together. Using this technique reduces the number of system calls and subsequent context switches; it also reduces the number of copies Times, thereby reducing the overhead of amortizing to processing and copying each packet.
However, since the packet must not be delivered to the upper layer until a batch has expired or the timer expires, the main problems of batch processing technology are delay jitter and increased timestamp error of received messages.
5. Affinity and prefetching.
Due to the locality principle of the program, the memory allocated for the process must be consistent with the memory block of the processor operation that is performing it. This technique is called memory affinity.
CPU affinityIs a technology that allows processes or threads to run on designated processor cores.
At the kernel and driver level, software and hardware interrupts can be specified in the same way to specify specific CPU cores or processors to handle, called interrupt affinity. Whenever a thread wants to access the received data, if the previous data has been assigned to If the interrupt handlers of the same CPU core are received, they can be more easily accessed in the local cache.
Three, libpcap
The packet capture mechanism of libpcap is to add a bypass process at the data link layer, without interfering with the processing of the system's own network protocol stack, filtering and buffering the data packets sent and received through the Linux kernel, and finally passed directly to the upper layer application.
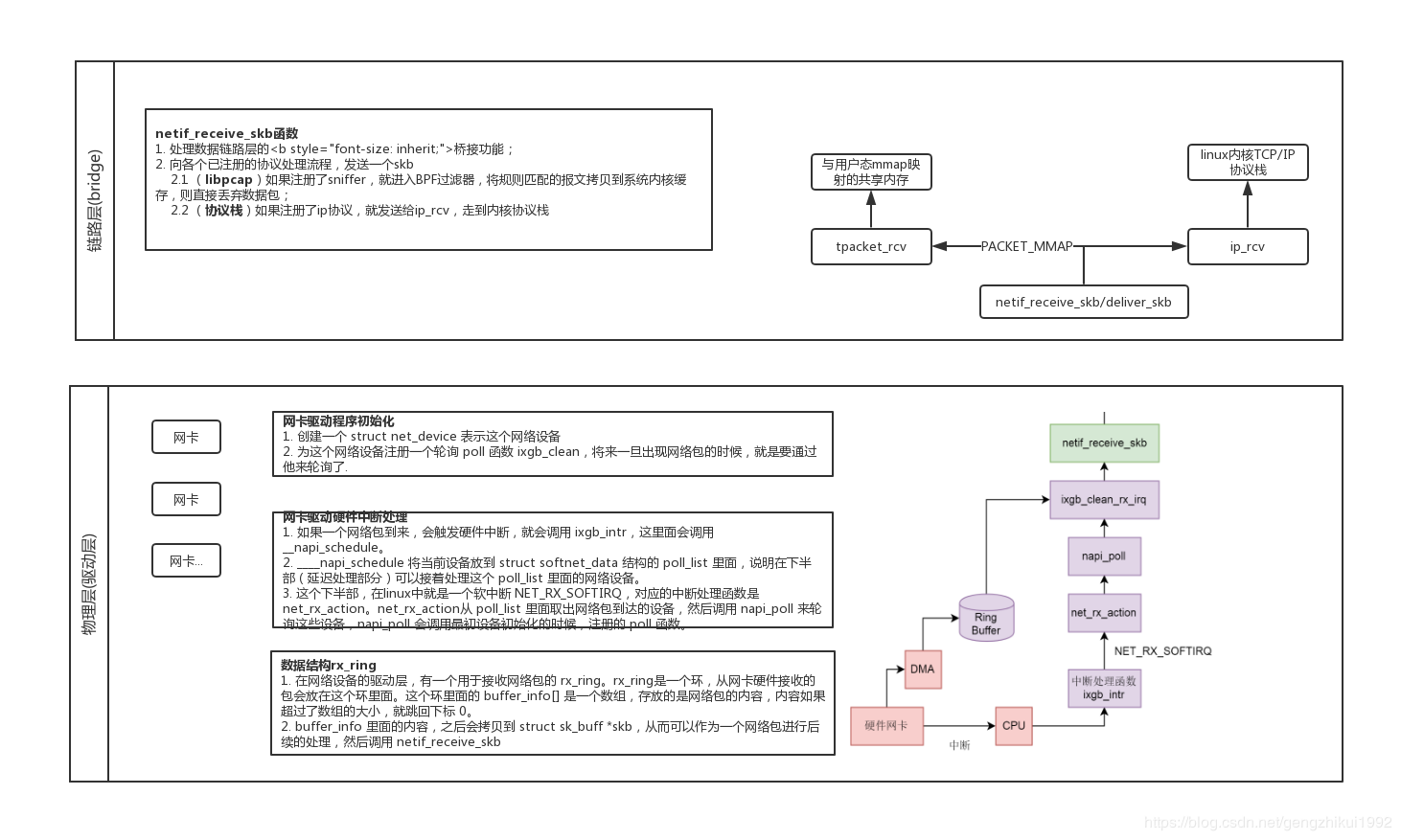
-
The data packet reaches the network card device.
-
The network card device performs DMA operation according to the configuration. (1st copy: NIC register -> the buffer ring buffer allocated by the kernel for the NIC)
-
The network card sends an interrupt to wake up the processor.
-
The driver software reads from the ring buffer and fills the kernel skbuff structure (2nd copy: Kernel network card buffer ring buffer->kernel special data structure skbuff)
-
Then call the netif_receive_skb function:
- If there is a packet capture program, the network sub-interface enters the BPF filter, and the packets matching the rules are copied to the system kernel cache (3rd copy). BPF associates a filter and two buffers for each packet capture program that requires service. BPF allocates buffers and usually its quota is 4KB. The store buffer is used to receive data from the adapter; the hold buffer is used to copy packets to the application.
- Handle the bridging function of the data link layer;
- Determine the upper layer protocol according to the skb->protocol field and submit it to the network layer for processing, enter the network protocol stack, and perform high-level processing.
-
libpcap bypasses the processing of the protocol stack part of the Linux kernel packet collection process, so that the user space API can directly call the socket PF_PACKET to obtain a copy of the data message from the link layer driver and remove it fromThe kernel buffer is copied to the user space buffer(4th copy)
Four, libpcap-mmap
libpcap-mmap is an improvement on the old libpcap implementation. The new version of libpcap basically uses the packet_mmap mechanism. Through mmap, PACKET_MMAP reduces a memory copy (the fourth copy is gone), reduces frequent system calls, and greatly improves the efficiency of packet capture.
Original link:linux-speed packet capture technology comparison --napi / libpcap / afpacket / pfring / dpdk
Intelligent Recommendation
IP packet capture library use Libpcap LAN
Experimental requirements Source and destination physical address of the print data packet; Print source IP and destination IP address; Printing upper layer protocol type; If the upper layer protocol ...
libpcap network packet capture function library
download Compile and install Instance The C function interface provided by the library is used to capture data packets passing through the specified network interface. download: http://www.linuxfromsc...

Design and implementation of network packet capture and traffic online analysis system-based on libpcap on MacOS Record this happy (DT) week
Design and implementation of network packet capture and traffic online analysis system-based on libpcap on MacOS Record this happy (DT) week Claim: Design and implement a network flow analysis system ...

TLS1.3 packet capture analysis (4) - NewSessionTicket
Last time, the client's authentication phase was analyzed. This time, the last content was analyzed later. First look at the Client responseChange Cipher SpecwithFinishedMessage when the server was se...

Experiment 4: Wireless LAN Packet Capture and Analysis
Wireless LAN Packet Capture and Analysis Experimental requirements and purpose Features and uses that are familiar with common wireless measurements Learn Wireshark Packet Capture and Analysis on WIND...
More Recommendation

Network packet capture function library Libpcap installation and use (very powerful)
1. Introduction to Libpcap Libpcap is the abbreviation of Packet Capture Libray, which is the data packet capture function library. The C function interface provided by the library is used to capture...
WinPcap / libpcap network packet capture TCP header flag
Recent WinPcap / libpcap fetch packet network, and to extract HTML image. To analyze TCP packets when they were big-endian out of the head. Finally, patience and the flag bit fields are read out. TCP ...
Porting libpcap packet capture library to arm platform under Linux
1. Introduction The libpcap library is installed on the x86-based Ubuntu. The predecessors have written very clearly. For details, please refer to: as well as If you need any dependency packages durin...

Libpcap library programming guide-network card packet capture
The functions and effects achieved by the sample program in this lecture are very similar to those in the previous lecture (open the adapter and capture data packets), but this lecture will use the pc...
libpcap source code analysis _PACKET_MMAP mechanism
Use PACKET_MMAP mechanism causes: is not turned on when the acquisition process is very inefficient PACKET_MMAP, it uses a very limited buffer, and each captures a packet need a system call, If you wa...