Re-exploring the TCP Delay Confirmation Mechanism under Linux--TCP_QUICKACK
Case 1: A colleague writes a stress test program with the logic of: continuously sending N 132-byte packets per second, and then continuously receiving N 132-byte packets returned by the background service. The code is roughly as follows:
1: char sndBuf[132];
2: char rcvBuf[132];
3: while (1) {
4: for (int i = 0; i < N; i++){
5: send(fd, sndBuf, sizeof(sndBuf), 0);
6: ...
7: }
8: for (int i = 0; i < N; i++) {
9: recv(fd, rcvBuf, sizeof(rcvBuf), 0);
10: ...
11: }
12: sleep(1);
13: }
In the actual test, it is found that when N is greater than or equal to 3, after the second second, every third recv call will always block about 40 milliseconds, but when analyzing the server-side log, it is found that all requests are processed on the server side. The consumption is below 2ms.
The specific positioning process at that time was as follows: First try to trace the client process with strace, but the strange thing is: once the strace is attached to the process, all the transceivers are normal, there will be no blocking phenomenon, once the strace is exited, the problem reappears. Remind by colleagues, it is likely that strace changed some things in the program or system (this problem has not yet been clarified), so I used tcpdump to capture the packet analysis and found that the server backend is after the response packet is returned, the client side The data was not immediately acknowledged by ACK, but waited for approximately 40 milliseconds before being acknowledged. After Google, and consulted "TCP / IP Detailed Volume 1: Protocol", this is TCP's Delayed Ack mechanism.
The solution is as follows: After the recv system call, call the setsockopt function once and set TCP_QUICKACK. The final code is as follows:
1: char sndBuf[132];
2: char rcvBuf[132];
3: while (1) {
4: for (int i = 0; i < N; i++) {
5: send(fd, sndBuf, 132, 0);
6: ...
7: }
8: for (int i = 0; i < N; i++) {
9: recv(fd, rcvBuf, 132, 0);
10: setsockopt(fd, IPPROTO_TCP, TCP_QUICKACK, (int[]){1}, sizeof(int));
11: }
12: sleep(1);
13: }
Case 2: When the performance of the CDKEY version of the marketing platform is tested, it is found that the demand distribution is abnormal: 90% of the requests are within 2ms, and the consumption is always between 38-42ms when 10% or so. This is a very good Regular number: 40ms. Because I have experienced Case 1 before, the guess is also due to the time-consuming problem caused by the delay confirmation mechanism. After a simple packet capture verification, the delay problem can be solved by setting the TCP_QUICKACK option.
Delayed confirmation mechanism
The principle of TCP/IP Explain 1: Protocol is described in detail in Chapter 19. TCP handles interactive data streams (ie, Interactive Data Flow, which is different from Bulk Data Flow, that is, block data stream, typical interaction. When the data stream is telnet, rlogin, etc., the Delayed Ack mechanism and the Nagle algorithm are used to reduce the number of small packets.
The book has already been very clear about the principles of these two mechanisms, and will not be repeated here. The subsequent part of this article will explain the TCP delay confirmation mechanism by analyzing the implementation of TCP/IP under Linux.
1. Why does TCP delay confirmation cause delay?
In fact, only the delay confirmation mechanism does not cause the request to be delayed (initially thought that it must wait until the ACK packet is sent, and the recv system call will return). In general, time-consuming growth can only occur when the mechanism is mixed with Nagle's algorithm or congestion control (slow start or congestion avoidance). Let's take a closer look at how it interacts:
Delayed acknowledgment and Nagle algorithm
Let's take a look at the rules of the Nagle algorithm (see the tcp_nagle_check function comment in the tcp_output.c file):
1) If the packet length reaches MSS, it is allowed to send;
2) If it contains FIN, it is allowed to send;
3) The TCP_NODELAY option is set, allowing sending;
4) When the TCP_CORK option is not set, if all outgoing packets are acknowledged, or all outgoing small packets (packet length less than MSS) are acknowledged, then transmission is allowed.
For rule 4), it means that there can be at most one unacknowledged small packet on a TCP connection, and no other small packets can be sent until the acknowledgement of the packet arrives. If the acknowledgment of a small packet is delayed (40ms in the case), the subsequent small packet transmission will be delayed accordingly. That is to say, the delayed acknowledgement affects not the packet that was delayed in confirmation, but the subsequent response packet.
1 00:44:37.878027 IP 172.25.38.135.44792 > 172.25.81.16.9877: S 3512052379:3512052379(0) win 5840 <mss 1448,wscale 7>
2 00:44:37.878045 IP 172.25.81.16.9877 > 172.25.38.135.44792: S 3581620571:3581620571(0) ack 3512052380 win 5792 <mss 1460,wscale 2>
3 00:44:37.879080 IP 172.25.38.135.44792 > 172.25.81.16.9877: . ack 1 win 46
......
4 00:44:38.885325 IP 172.25.38.135.44792 > 172.25.81.16.9877: P 1321:1453(132) ack 1321 win 86
5 00:44:38.886037 IP 172.25.81.16.9877 > 172.25.38.135.44792: P 1321:1453(132) ack 1453 win 2310
6 00:44:38.887174 IP 172.25.38.135.44792 > 172.25.81.16.9877: P 1453:2641(1188) ack 1453 win 102
7 00:44:38.887888 IP 172.25.81.16.9877 > 172.25.38.135.44792: P 1453:2476(1023) ack 2641 win 2904
8 00:44:38.925270 IP 172.25.38.135.44792 > 172.25.81.16.9877: . ack 2476 win 118
9 00:44:38.925276 IP 172.25.81.16.9877 > 172.25.38.135.44792: P 2476:2641(165) ack 2641 win 2904
10 00:44:38.926328 IP 172.25.38.135.44792 > 172.25.81.16.9877: . ack 2641 win 134
From the above tcpdump capture packet analysis, the eighth packet is delayed acknowledgement, and the data of the ninth packet is already placed in the TCP send buffer on the server side (172.25.81.16) (the application layer calls Send has been returned), but according to the Nagle algorithm, the ninth packet needs to wait until the ACK of the first 7 packets (less than MSS) arrives.
Delayed acknowledgment and congestion control
We first use the TCP_NODELAY option to turn off the Nagle algorithm, and then analyze how the latency acknowledgment interacts with TCP congestion control.
Slow start: The sender of TCP maintains a congestion window, which is denoted as cwnd. The TCP connection is established. This value is initialized to one segment. Each time an ACK is received, the value is incremented by one segment. The sender takes the minimum value in the congestion window and the notification window (corresponding to the sliding window mechanism) as the upper transmission limit (the congestion window is the flow control used by the sender, and the notification window is the flow control used by the receiver). The sender starts to send 1 segment. After receiving the ACK, cwnd increases from 1 to 2, that is, 2 segments can be sent. When the ACKs of the two segments are received, cwnd is increased to 4. That is, exponential growth: for example, within the first RTT, a packet is sent, and its ACK is received, cwnd is incremented by 1, and within the second RTT, two packets can be sent and the corresponding two ACKs are received, then cwnd each When an ACK is received, it increases by 1, and eventually becomes 4, achieving an exponential increase.
In Linux implementations, not every time an ACK packet is received, cwnd is incremented by 1. If no other packets are waiting to be ACKed when the ACK is received, it does not increase.
I use the test code of Case 1. In the actual test, cwnd starts from the initial value of 2 and finally holds the value of 3 segments. The tcpdump results are as follows:
1 16:46:14.288604 IP 172.16.1.3.1913 > 172.16.1.2.20001: S 1324697951:1324697951(0) win 5840 <mss 1460,wscale 2>
2 16:46:14.289549 IP 172.16.1.2.20001 > 172.16.1.3.1913: S 2866427156:2866427156(0) ack 1324697952 win 5792 <mss 1460,wscale 2>
3 16:46:14.288690 IP 172.16.1.3.1913 > 172.16.1.2.20001: . ack 1 win 1460
......
4 16:46:15.327493 IP 172.16.1.3.1913 > 172.16.1.2.20001: P 1321:1453(132) ack 1321 win 4140
5 16:46:15.329749 IP 172.16.1.2.20001 > 172.16.1.3.1913: P 1321:1453(132) ack 1453 win 2904
6 16:46:15.330001 IP 172.16.1.3.1913 > 172.16.1.2.20001: P 1453:2641(1188) ack 1453 win 4140
7 16:46:15.333629 IP 172.16.1.2.20001 > 172.16.1.3.1913: P 1453:1585(132) ack 2641 win 3498
8 16:46:15.337629 IP 172.16.1.2.20001 > 172.16.1.3.1913: P 1585:1717(132) ack 2641 win 3498
9 16:46:15.340035 IP 172.16.1.2.20001 > 172.16.1.3.1913: P 1717:1849(132) ack 2641 win 3498
10 16:46:15.371416 IP 172.16.1.3.1913 > 172.16.1.2.20001: . ack 1849 win 4140
11 16:46:15.371461 IP 172.16.1.2.20001 > 172.16.1.3.1913: P 1849:2641(792) ack 2641 win 3498
12 16:46:15.371581 IP 172.16.1.3.1913 > 172.16.1.2.20001: . ack 2641 win 4536
The packet in the above table is in the case of setting TCP_NODELAY, and cwnd has grown to 3. After the 7th, 8th, and 9th are issued, it is limited by the size of the congestion window. Even if the TCP buffer has data to send, it cannot continue to send. That is, the 11th packet must wait until the 10th packet arrives before it can be sent, and the 10th packet obviously has a 40ms delay.
Note: The TCP_INFO option (man 7 tcp) of getsockopt can be used to view the details of the TCP connection, such as the current congestion window size, MSS, and so on.
2. Why is it 40ms? Can this time be adjusted?
First of all, in the official document of redhat, there are the following instructions:
Some applications may cause a certain delay due to TCP's Delayed Ack mechanism when sending small packets. Its value defaults to 40ms. The minimum delay confirmation time at the system level can be adjusted by modifying tcp_delack_min. E.g:
# echo 1 > /proc/sys/net/ipv4/tcp_delack_min
That is, it is expected to set the minimum delay acknowledgment timeout time to 1ms.
However, under the slackware and suse systems, this option was not found, which means that the minimum value of 40ms, under these two systems, cannot be adjusted through configuration.
There is a macro definition under linux-2.6.39.1/net/tcp.h:
1: /* minimal time to delay before sending an ACK */
2: #define TCP_DELACK_MIN ((unsigned)(HZ/25))
Note: The Linux kernel issues timer interrupt (IRQ 0) every fixed period. HZ is used to define timer interrupts every second. For example, HZ is 1000, which represents 1000 timer interrupts per second. HZ can be set when the kernel is compiled. For systems running on our existing servers, the HZ value is 250.
From this, the minimum delay confirmation time is 40ms.
The delayed acknowledgement time of the TCP connection is generally initialized to a minimum value of 40 ms, and then continuously adjusted according to parameters such as the retransmission timeout period (RTO) of the connection, the time interval between the last received data packet and the current reception of the data packet. Specific adjustment algorithm, you can refer to linux-2.6.39.1/net/ipv4/tcp_input.c, Line 564 tcp_event_data_recv function.
3. Why does TCP_QUICKACK need to be reset after each call to recv?
In man 7 tcp, there are the following instructions:
TCP_QUICKACK
Enable quickack mode if set or disable quickack mode if cleared. In quickack mode, acks are sent immediately, rather than delayed if needed in accordance to normal TCP operation. This flag is not permanent, it only enables a switch to or from quickack mode. Subsequent operation of the TCP protocol will once again enter/leave quickack mode depending on internal protocol processing and factors such as delayed ack timeouts occurring and data transfer. This option should not be used in code intended to be portable.
The manual clearly states that TCP_QUICKACK is not permanent. So what is its specific implementation? Refer to the setsockopt function for the implementation of the TCP_QUICKACK option:
1: case TCP_QUICKACK:
2: if (!val) {
3: icsk->icsk_ack.pingpong = 1;
4: } else {
5: icsk->icsk_ack.pingpong = 0;
6: if ((1 << sk->sk_state) &
7: (TCPF_ESTABLISHED | TCPF_CLOSE_WAIT) &&
8: inet_csk_ack_scheduled(sk)) {
9: icsk->icsk_ack.pending |= ICSK_ACK_PUSHED;
10: tcp_cleanup_rbuf(sk, 1);
11: if (!(val & 1))
12: icsk->icsk_ack.pingpong = 1;
13: }
14: }
15: break;
In fact, the linux socket has a pingpong attribute to indicate whether the current link is an interactive data stream. If the value is 1, it indicates that the interactive data stream will use a delayed acknowledgment mechanism. But the value of pingpong will change dynamically. For example, when a TCP link is to send a packet, the following function (linux-2.6.39.1/net/ipv4/tcp_output.c, Line 156) is executed:
1: /* Congestion state accounting after a packet has been sent. */
2: static void tcp_event_data_sent(struct tcp_sock *tp,
3: struct sk_buff *skb, struct sock *sk)
4: {
5: ......
6: tp->lsndtime = now;
7: /* If it is a reply for ato after last received
8: * packet, enter pingpong mode.
9: */
10: if ((u32)(now - icsk->icsk_ack.lrcvtime) < icsk->icsk_ack.ato)
11: icsk->icsk_ack.pingpong = 1;
12: }
The last two lines of code indicate that if the current time and the last time the packet was received were less than the calculated delay acknowledgment timeout, the interactive data flow mode was re-entered. It can also be understood that when the delayed acknowledgement mechanism is confirmed to be valid, it will automatically enter the interactive.
From the above analysis, the TCP_QUICKACK option needs to be reset after each call to recv.
4. Why aren't all packages delayed confirmation?
In the TCP implementation, use tcp_in_quickack_mode (linux-2.6.39.1/net/ipv4/tcp_input.c, Line 197) to determine if you need to send an ACK immediately. Its function is implemented as follows:
1: /* Send ACKs quickly, if "quick" count is not exhausted
2: * and the session is not interactive.
3: */
4: static inline int tcp_in_quickack_mode(const struct sock *sk)
5: {
6: const struct inet_connection_sock *icsk = inet_csk(sk);
7: return icsk->icsk_ack.quick && !icsk->icsk_ack.pingpong;
8: }
Two conditions are required to be considered as the quickack mode:
1. pingpong is set to 0.
2, the quick confirmation number (quick) must be non-zero.
The value of pingpong is described earlier. The quick attribute has the following comment in the code: scheduled number of quick acks, which is the number of packets that are quickly confirmed. Each time you enter the quickack mode, quick is initialized to receive the window divided by 2 times the MSS value (linux-2.6.39.1/net /ipv4/tcp_input.c, Line 174), each time an ACK packet is sent, the quick is decremented by 1.
5, on the TCP_CORK option
The TCP_CORK option, like TCP_NODELAY, controls Nagleization.
1. Turning on the TCP_NODELAY option means that no matter how small the packet is, it is sent immediately (regardless of the congestion window).
2. If you compare a TCP connection to a pipe, the TCP_CORK option acts like a plug. Setting the TCP_CORK option is to plug the pipe with a plug, and to cancel the TCP_CORK option, the plug is unplugged.
For example, the following code:
1: int on = 1;
2: setsockopt(sockfd, SOL_TCP, TCP_CORK, &on, sizeof(on)); //set TCP_CORK
3: write(sockfd, ...); //e.g., http header
4: sendfile(sockfd, ...); //e.g., http body
5: on = 0;
6: setsockopt(sockfd, SOL_TCP, TCP_CORK, &on, sizeof(on)); //unset TCP_CORK
When the TCP_CORK option is set, the TCP link will not send any packets, ie it will only be sent when the amount of data reaches the MSS. When the data transfer is complete, it is usually necessary to cancel the option so that it is plugged, but not enough packets of MSS size can be sent out in time. In order to improve performance and throughput, Web Server and file server generally use this option.
The famous high-performance Web server Nginx, in the case of using the sendfile mode, can be set to open the TCP_CORK option: configure tcp_nopush in the nginx.conf configuration file to be on. (TCP_NOPUSH and TCP_CORK two options are similar in function, except that NOPUSH is an implementation under FreeBSD, and CORK is an option under Linux). In addition, in order to reduce the system call, Nginx pursues the ultimate performance. For short connections (generally, the connection is automatically closed immediately after the data is transmitted. Except for the HTTP persistent connection of Keep-Alive), the program does not cancel the TCP_CORK option through the setsockopt call because the connection is closed. The TCP_CORK option is automatically cancelled and the remaining data is sent.
Intelligent Recommendation

RabbitMQ message Ack confirmation mechanism + message delay queue
table of Contents One: RabbitMQ message Ack confirmation mechanism 1. Confirm the type 2. Message sending confirmation 2.1 Declare queues and exchanges 2.2 Producer configuration application 2.3. Prod...
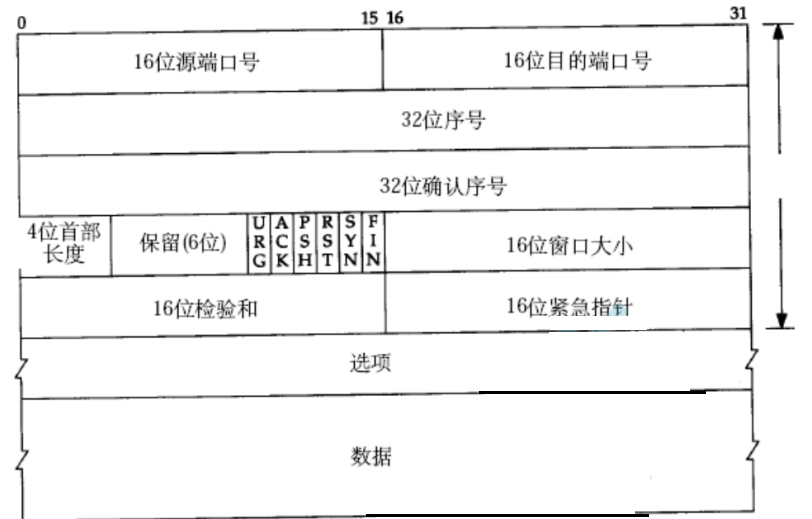
TCP protocol confirmation response mechanism and timeout retransmission mechanism
What is TCP TCP is a transmission control protocol. In the transmission process, it mainly guarantees the reliability of data Three characteristics of TCP Connected reliability Byte-oriented TCP proto...
Linux, TCP delayed acknowledgment delay problem (Delayed Ack) mechanism leading analysis
2019 Unicorn Enterprises heavily recruiting engineers Python standard >>> Disclaimer: This article from the Pan group of original articles, please indicate the source: Original article link:h...
Use TCP_QUICKACK and SO_LINGER to eliminate the 3rd packet in tcp handshake
Find an insterest project, to remove last packet in 3-way tcp handshake, https://github.com/tevino/tcp-shaker Disable TCP_QUICKACK(linux 2.4.4+) will prevent connect to sending ack(3 packet) immediate...
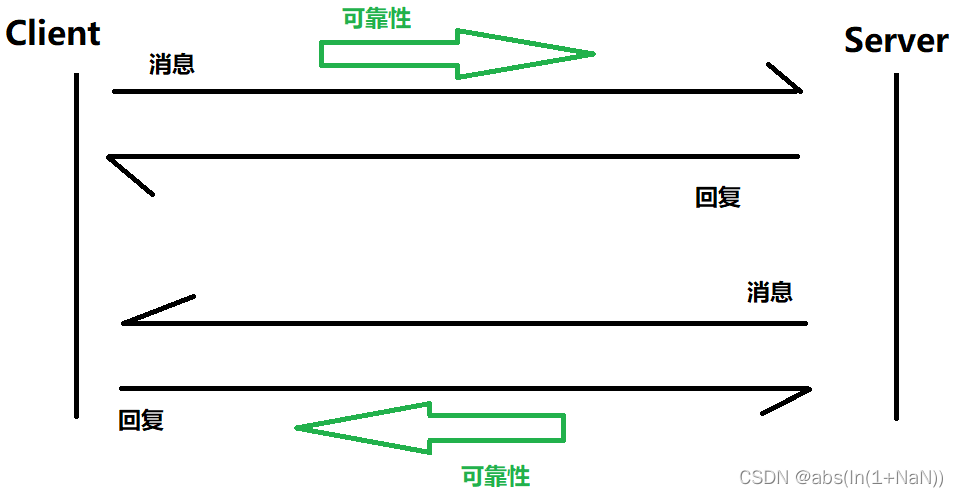
Key mechanisms for TCP reliability——Confirmation Response Mechanism (ACK)
The confirmation response mechanism is the key mechanism to realize TCP reliability. Simply put, the confirmation response mechanism is that after sending a message, either the client or the server mu...
More Recommendation

Linux system delay and timing mechanism
Background: It is impossible for people to be in front of the computer all the time, and sometimes there is a problem of resource occupancy. Therefore, if it can be delayed or scheduled, it will be mu...
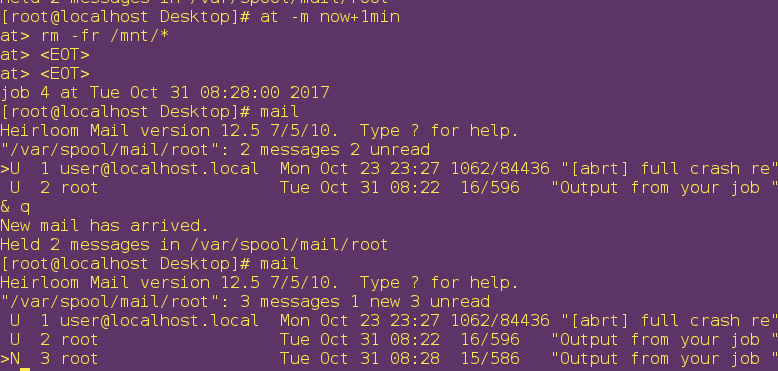
System delay and timing mechanism in Linux
1. System delay mechanism Purpose: To allow managers to perform the actions they want to perform at any time. 1) at command At the time when you want to perform the action Action &...

linux-system delay and timing mechanism
at 1. Basic usage of the at command at xx:xx Enter to write the task to be executed (or directly use now+1min to execute in one second) now+1min operation at -l lists the id of the delayed task at -r ...

TCP fast re-transmission mechanism details
Understanding of wireshark capture fields when retransmission bit fuzzy, check for a long time finally see RFC fly.RFC2018This way: So for the sack option, this option includes a series of info block,...
The LCD driver under the first exploring linux
LCD is a commonly used peripheral. Generally, semiconductor manufacturers will write the corresponding LCD interface driver for their own chips. Developers do not need to modify the LCD driver part, j...