Read() problem in computer secondary exam python file
Read() problem in computer secondary exam python file
In the Python computer secondary exam, the first set of simulation questions and the second set of simulation questions are character statistics, but the first question does not use .read() to read the file, while the second set requires Use .read() to read the file, try to modify the file to read the first topic by adding .read(). The generated .txt file is blank. Please also explain the wave to Xiaobai.
#"The Analects of Confucius" is one of the classic works of the Confucian school, which mainly records the words and deeds of Confucius and his disciples.
There are a lot of "The Analects" text versions on it. Here is a version with the file name "Analects - Network
Edition.TXT".
Question 1: Please write a program to extract all the original content in the "The Analects" document, and save the output to
"The Analects of Confucius - Extracted .txt" file output file format requirements: remove each line of the original part of the article
The first space and the number sign such as "1.11", there is no space at the end of the line, no blank line reference format is as follows
(The original brackets and internal numbers are the corresponding tokens in the source file)
a = open('The Analects - Network Edition.txt', 'r', encoding = 'utf-8')
b = open('The Analects - Extractor 2.txt', 'w')
wflag = False
for line in a:
if '【'in line:
wflag = False
If '[ ]' in line:
wflag = True
continue
if wflag == True:
for i in range(0,25):
for j in range(0,25):
line = line.replace('{}·{}'.format(i,j),'**')
for i in range(0,10):
line = line.replace('*{}'.format(i),'')
for i in range(0,10):
line = line.replace('{}*'.format(i),'')
line = line.replace('*','')
b.write(line)
a.close()
b.close()
“Tianlong Ba Bu” is one of the masterpieces of the famous writer Jin Yong, which was completed in 4 years.
The work is magnificent and has many characters. It is very classic and gives a "Dragon"
Network version, the file name is ". Tianlong Babu - online version.
Question 1: Please write a program for Chinese characters and punctuation marks appearing in this "Dragon" text
Statistics are performed. The character and the number of occurrences are separated by a colon: the output is saved to
In the "Tianlong Babu-Chinese Character Statistics.txt" file, the file is required to be stored in CSV format.
The reference format is as follows (note that the spaces and carriage returns are not counted):
Example: Day: 100, Dragon: 110, Eight: 109, Part: 10
m=open('Tianlong Babu-Network Edition.txt', 'r', encoding='utf-8')
b=open('Tianlong Babu-Chinese character statistics.txt', 'w', encoding='utf-8')
a = m.read()
c = {}
for i in a :
c[i] = c.get(i,0)+1
del c['\n']
d = []
for key in c:
d.append('{}:{}'.format(key,c[key]))
b.write(','.join(d))
m.close()
b.close()
Intelligent Recommendation

7. National Computer Secondary Python Exam - Simple Application (II)
important: Code is displayed in a picture form,Red box for the exam code in the examIt is also the code we need to add, and the rest of the code exam will be given, we need to fill in the remaining ar...
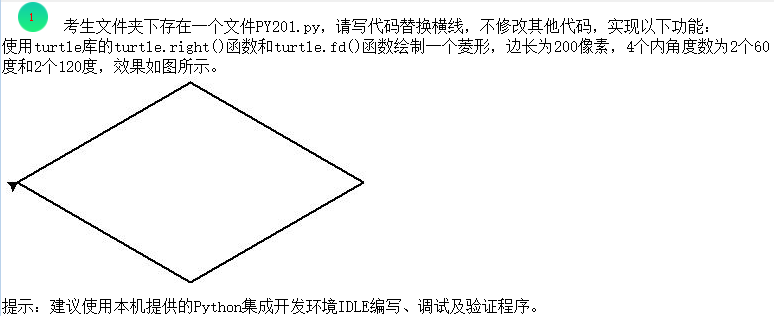
6. National Computer Secondary Python Exam - Simple Application Top (1)
important: Code is displayed in a picture form,Red box for the exam code in the examIt is also the code we need to add, and the rest of the code exam will be given, we need to fill in the remaining ar...
More Recommendation
National Computer Rating Secondary Python Exam Prosperity Prediction and Analysis
Although it has been determined in September 2018 to join "Secondary Python" in the National Computer Rank Examination, it has not yet been introduced in the full and detailed exam outline, ...