Python tutorial return in Keras deep learning library
Keras deep learning is a library that encapsulates an efficient and math libraries Theano TensorFlow.
In this article, you will learn how to use Keras development and evaluation of the neural network model to solve regression problems.
After completing this step by step tutorial, you will know:
- How to load CSV data collection and input as Keras library algorithms.
- How to use a neural network model Keras a regression problem.
- How Keras scikit-learn and cross validation to evaluate the model.
- How to perform data processing to improve performance Keras model.
- How to adjust network topology Keras model.
Now let's get started.
- March 2017Updated: examples are based on Keras 2.0.2, TensorFlow 1.0.1 and Theano 0.9.0 version
 Python Keras deep learning library return Tutorials Photo by Salim Fadhley shooting, the corresponding rights reserved.
Python Keras deep learning library return Tutorials Photo by Salim Fadhley shooting, the corresponding rights reserved.
1. Problem Description
In this tutorial, we want to solve the problem based onBoston house price data sets。
You can use this linkDownload this datasetAnd save it to the current working directory, named housing.csv.
The data set describes 13 digital quantitative attributes Boston suburb houses, and several hundred thousand dollars per square unit price for the houses of the outskirts of the simulation. So this is a regression prediction modeling. Enter the property crime rate, including non-retail commercial area, the concentration of chemical pollution and so on.
This is a machine learning in a very good question. Because all of the input and output attributes are quantifiable, and there are as many as 506 instances can be used, so this research question is easy to use.
Using the mean square error (MSE) to assess the reasonable performance of the model is approximately 20 square (that is, per square meter of $ 4500) per one hundred thousand dollars. The figure for our neural network is a good training goals.
2. Develop standard neural network model
In this section, we will create a benchmark regression neural network model.
Introduces all functions and objects (required Python library) needed for this tutorial.
import numpy import pandas from keras.models import Sequential from keras.layers import Dense from keras.wrappers.scikit_learn import KerasRegressor from sklearn.model_selection import cross_val_score from sklearn.model_selection import KFold from sklearn.preprocessing import StandardScaler from sklearn.pipeline import Pipeline
After the introduction of the necessary libraries, we can now load our data set from a local directory file.
UCI machine learning repository data set is not really CSV format, but with a space separating the two properties. We can use the pandas library to easily load the data set. Then, separating an input (X) and output (Y) properties, and to make it easier to use Keras scikit-learn modeling.
# load dataset dataframe = pandas.read_csv("housing.csv", delim_whitespace=True, header=None) dataset = dataframe.values # split into input (X) and output (Y) variables X = dataset[:,0:13] Y = dataset[:,13]
We can use scikit-learn to create, and to assess Keras models through its easy to use wrapper objects. This approach is ideal because scikit-learn good assessment model, and allow us a few lines of code, you can use the powerful data model and pre-assessment program.
Keras need a wrapper function as a parameter function. This must be defined function is responsible for creating neural network model to be evaluated.
Let's define a function to create a reference model to be evaluated. This is a simple model, only one hidden layer fully connected, has the same number of neurons in the input attributes (13). Relu network uses hidden layer activation function. No activation function for the output layer, because this is a regression problem, we want to predict the value directly, without the need to transform the activation function.
We will use ADAM efficient optimization algorithms and optimization of minimum mean square error loss function. This will be our unified metric used to assess the performance of multiple models. This is a desirable indicator, because the calculation of the output value by the square root of a mistake, we can direct (thousands of dollars as a unit) understood in the context of the problem.
# define base model def baseline_model(): # create model model = Sequential() model.add(Dense(13, input_dim=13, kernel_initializer='normal', activation='relu')) model.add(Dense(1, kernel_initializer='normal')) # Compile model model.compile(loss='mean_squared_error', optimizer='adam') return model
Keras packaged object as scikit-learn regression estimator calculates library named KerasRegressor. We create a KerasRegressor
Object instance, and create a function name of the neural network model, as well as some of the parameters passed to the later model fit () function, such as the maximum number of training, the size of each batch of data. Both are set to reasonable defaults.
We also use a constant random seed to initialize the random number generator, we assessed each model tutorial entire process is repeated (same random number) present. This is to ensure that we consistently compare models.
# fix random seed for reproducibility seed = 7 numpy.random.seed(seed) # evaluate model with standardized dataset estimator = KerasRegressor(build_fn=baseline_model, nb_epoch=100, batch_size=5, verbose=0)
The final step is to assess the baseline model. We will use the 10-fold cross-validation to evaluate the model.
kfold = KFold(n_splits=10, random_state=seed) results = cross_val_score(estimator, X, Y, cv=kfold) print("Results: %.2f (%.2f) MSE" % (results.mean(), results.std()))
We evaluated the operation code in an invisible model data (randomly generated) on performance. Mean square error result output, comprising a 10-fold cross-validation (10) mean and standard deviation of all the evaluation results (mean square).
Baseline: 31.64 (26.82) MSE
3. Modeling standardized data sets
An important issue is the Boston housing data sets input attributes different impact on prices.
Before using the neural network model to data modeling, data is ready to be used is always a good practice.
The baseline model from above to continue the discussion, we can use the model to evaluate the input data set prior to re-evaluate the standardized version.
We can use scikit-learn thePipeline At each step of the frame cross-validation of the normalized data model evaluation process. This ensures that each test set in the cross-validation, the data does not leak to the training data.
The following code creates a scikit-learn Pipeline, standardized data set first, and then create and evaluate a reference Neural Network Model.
# evaluate model with standardized dataset numpy.random.seed(seed) estimators = [] estimators.append(('standardize', StandardScaler())) estimators.append(('mlp', KerasRegressor(build_fn=baseline_model, epochs=50, batch_size=5,verbose=0))) pipeline = Pipeline(estimators) kfold = KFold(n_splits=10, random_state=seed) results = cross_val_score(pipeline, X, Y, cv=kfold) print("Standardized: %.2f (%.2f) MSE" % (results.mean(), results.std()))
Run the sample than without providing standardized data reference model for better performance and reduce errors.
Standardized: 29.54 (27.87) MSE
This may further extend the output section similar variable scaling, for example, be normalized to the range of 0-1, and using the Sigmoid activation function or the like in the output layer outputs the predicted pass is reduced to the same input range.
4. Adjust Neural Network Topology
For neural network models, there are many aspects that can be optimized.
Optimization may be most obvious effect of the structure of the network itself, the number of layers and each layer comprises a number of neurons.
In this section, we will evaluate the other two network topology, to further improve the performance of the model. These two structures are deeper layers and the layer width wider network topology.
4.1. Assess deeper layers of the network topology
A method for improving the performance of neural networks is to add more layers. This may allow the model to extract and re-combination of higher order characteristic data contains.
In this section, we will evaluate the effect of adding a hidden layer model. It is as simple as defining a new function that will create the deeper model, most programs are copied from above code from the baseline model. Then we can insert a new layer after the first hidden layer. In the present embodiment, the new layer comprising neurons half (6)
# define the model def larger_model(): # create model model = Sequential() model.add(Dense(13, input_dim=13, kernel_initializer='normal', activation='relu')) model.add(Dense(6, kernel_initializer='normal', activation='relu')) model.add(Dense(1, kernel_initializer='normal')) # Compile model model.compile(loss='mean_squared_error', optimizer='adam') return model
Our network topology is as follows:
13 inputs -> [13 -> 6] -> 1 output
We can use the same manner as above to evaluate the network topology, while the use of the normalized data set of said data to improve performance.
numpy.random.seed(seed) estimators = [] estimators.append(('standardize', StandardScaler())) estimators.append(('mlp', KerasRegressor(build_fn=larger_model, epochs=50, batch_size=5,verbose=0))) pipeline = Pipeline(estimators) kfold = KFold(n_splits=10, random_state=seed) results = cross_val_score(pipeline, X, Y, cv=kfold) print("Larger: %.2f (%.2f) MSE" % (results.mean(), results.std()))
Run the code, the model does show further improvement, reduced from 28-24 dollars per square 100,000.
4.2. Evaluation slice width wider network topology
Another method of improving the performance capability model is to establish a network layer wider width.
In this section, we will evaluate the effect of keeping the shallow network architecture, but will increase the number of neurons in the hidden layer nearly doubled.
Similarly, we need to do is define a new function to create our neural network model. In the following code, we have increased the number of neurons in the hidden layer, compared with the baseline model increased from 13 to 20.
# define wider model def wider_model(): # create model model = Sequential() model.add(Dense(20, input_dim=13, kernel_initializer='normal', activation='relu')) model.add(Dense(1, kernel_initializer='normal')) # Compile model model.compile(loss='mean_squared_error', optimizer='adam') return model
Our network topology is as follows:
13 inputs -> [20] -> 1 output
We can use the same protocol as above to evaluate the broader network topology:
numpy.random.seed(seed) estimators = [] estimators.append(('standardize', StandardScaler())) estimators.append(('mlp', KerasRegressor(build_fn=wider_model, epochs=100, batch_size=5,verbose=0))) pipeline = Pipeline(estimators) kfold = KFold(n_splits=10, random_state=seed) results = cross_val_score(pipeline, X, Y, cv=kfold) print("Wider: %.2f (%.2f) MSE" % (results.mean(), results.std()))
The model is built error further down to around $ 100,000 per 21 square feet. This is not the result of a trough of cake for this problem.
Wider: 21.64 (23.75) MSE
Difficult to guess before put into action, a wider network performance on this issue would be better than the network's structure is more. The results demonstrate the importance of empirical testing in the development of neural network model.Article Source:Beida Jade Bird official website
summary
HDGHW824145898In this article, you learned about Keras depth study library for use regression modeling problem.
In this tutorial, you learned how to develop and evaluate neural network model, including:
- How to load data and developing a baseline model.
- How to use the data preparation techniques (such as standardization) to improve performance.
- How to design and evaluate the network have different topologies.
Intelligent Recommendation
Python deep learning library keras-various network layers
Full Stack Engineer Development Manual (Author: Luan Peng) Python tutorial full solution 1. Network layer The layers of keras mainly include: Common layer (Core), convolutional layer (Convolutional), ...
Python deep learning library keras-full solution for network modeling
Full Stack Engineer Development Manual (Author: Luan Peng) Python tutorial full solution 1. Data preprocessing 1. Sequence preprocessing 1.1, pad sequence pad_sequences Convert the sequence of nb_samp...
WINDOWS Python Configuration Theano Deep Learning Framework Keras Library
Reference reference 1. Install anaconda Python IDE-Anaconda for scientific calculations 2. Open Anaconda Prompt 3. Install the GCC environment Add: PATH in the system environment variable: Verificatio...

Python Xiaobai Deep Learning Tutorial: Keras Explained (Part 1)
Click on"Simply Talk about Python",select"Top/Star Official Account" Welfare dry goods, delivered immediately! Picture from:https://unsplash.com/ This article is authorized to repr...
[Reserved] Keras beginner tutorial: use python to learn about deep learning
Original link: This article comes from the EliteDataScience website, the original address ishere。 In this step-by-stepKerasIn the tutorial, you will learn how to build a convolucted neural network usi...
More Recommendation
Keras learning-deep learning library of Theano and TensorFlow
Keras: Deep learning library based on Theano and TensorFlow This is Keras Keras is a high-level neural network library, Keras is written in pure Python and based on Tensorflow or Theano. Keras was bor...
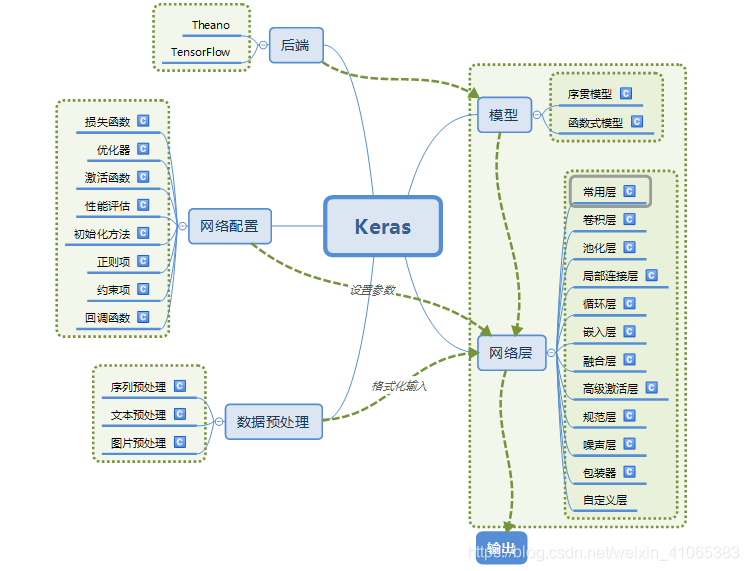
Keras: Python-based deep learning library (Basic)----Deep learning white introduction essay
The content of this article refers to the following article and summarizes the knowledge: https://keras-cn.readthedocs.io/en/latest/ 1. About Keras 1 Introduction Keras is a deep learning framework ba...
Python deep learning -Keras summary
You should be familiar with the following three network architecture: a dense network connections, network and convolution cycle network. Hypothesis space each type of network are specific to a partic...

Deep learning library Keras Quick Start
Keras is a powerful, easy to use deep learning library, seamless Theano and TensorFlow, while providing high-level neural network API, to establish and assess the depth of the learning model. K...
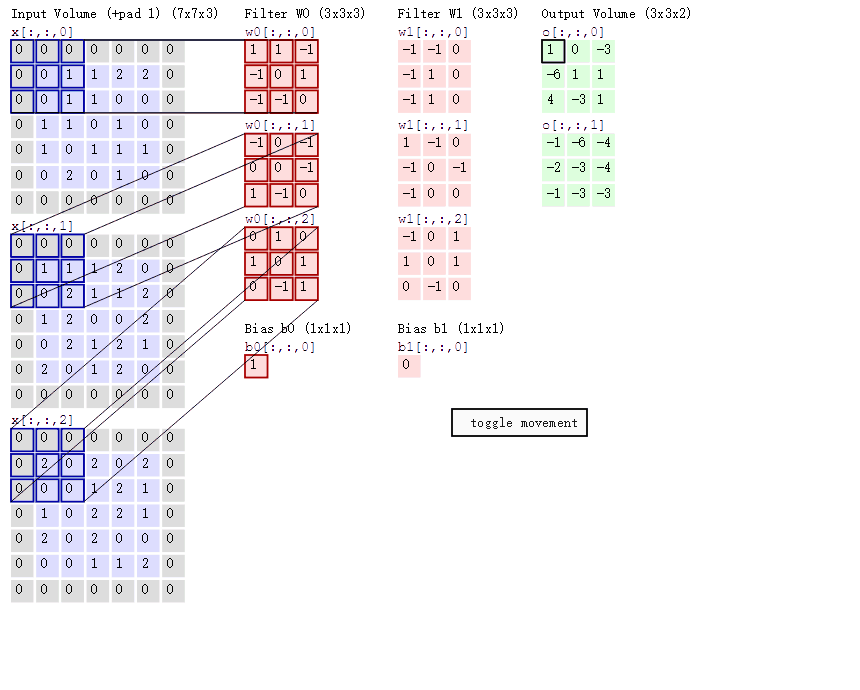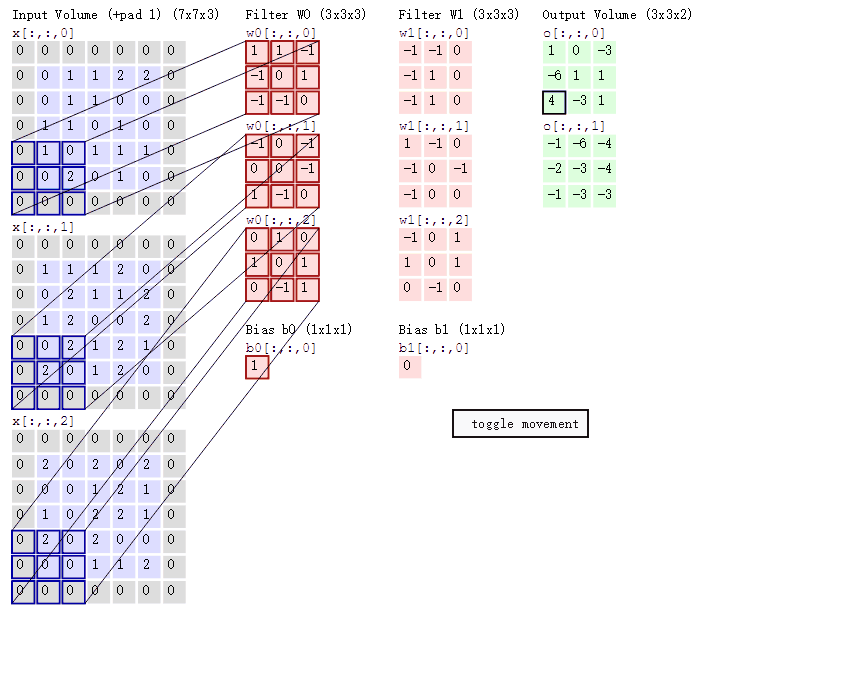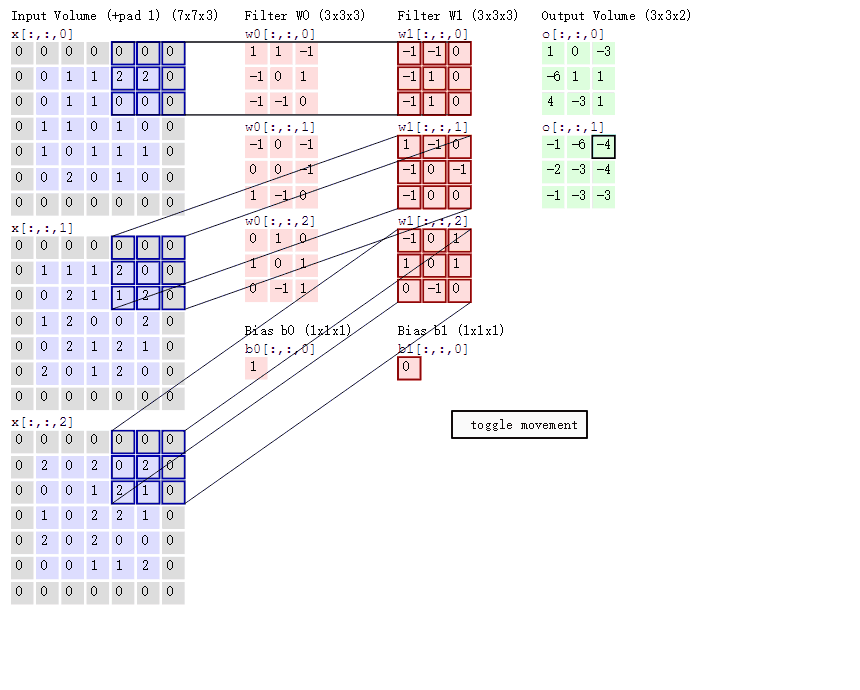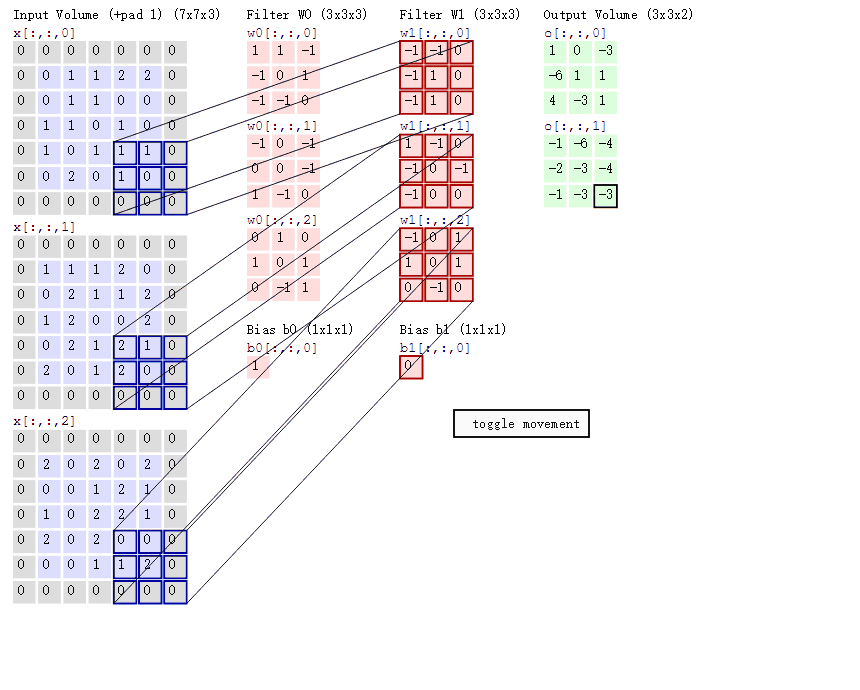
Keras: deep learning library based on Theano and TensorFlow
The article is reproduced at: https://www.cnblogs.com/LittleHann/p/6442161.html For the introduction of keras framework, you can also refer to: https://www.jianshu.com/p/8dcddbc1c6d4 KerasThe organiza...