When do I need to use ConcurrentHashMap and linkedHashMap?
First look at the basics
Collection includes set map list
set is not repeated
The TreeSet internal elements are sorted and are not synchronized.
HashSet internal data structure is a hash table, which is not synchronized LinkHashSet
List ordered repeatable
The Vector inside is an array data structure that is synchronous (thread-safe). Additions and deletions are very slow.
Stack ArrayList is an array data structure. Threads are not secure. - Same as LinkList usage. The main function is query.
LinkedList is a bidirectional circular linked list data structure, which is asynchronous (thread unsafe) ---- add and delete
Map
HashMap traversal data is random, allowing a record's key to be NULL, allowing multiple records to be NULL
HashTable is a thread-safe version of hashmap that supports off-the-shelf synchronization, low efficiency, and keys and values cannot be NULL ConcurrentHashMap thread safe, and lock separation
LinkHashMap saves the order of record insertion. It is definitely inserted first when Iteraor traverses. It is slower than hashmap when traversing. It has all the features of HashMap.
The SortMap interface implemented by TreeMap can sort the records it saves according to the key. The default is ascending (natural), or you can specify the sorting comparator. When you use Iterator to traverse TreeMap, the records obtained are sorted, and the key is not allowed. The implementation principle of the asynchronous treeMap is realized by the red-black tree.
The implementation principle of HashMap
1 HashMap overview: HashMap is a non-synchronous implementation of the Map interface based on the hash table. This implementation provides all optional mapping operations and allows the use of null values and null keys. This class does not guarantee the order of the mapping, especially since it does not guarantee that the order will remain constant.
2 HashMap data structure: In the Java programming language, the most basic structure is two, one is an array, the other is an analog pointer (reference), all data structures can be constructed with these two basic structures HashMap also No exception. HashMap is actually a "chain table hash" data structure, that is, a combination of an array and a linked list.
3 When we go to the put element in the Hashmap, we first recalculate the hash value according to the hashcode of the key, and root the hash value to get the position (subscript) of the element in the array.
If the array already has other elements stored in that location, then the elements in this position will be stored in a linked list, with the newly added one in the chain.
is added to the end of the chain first. If there is no element in the position in the array, the element is placed directly at the position of the array.
Traversing collection
Iterator it = arr.iterator(); while(it.hasNext()){ object o
=it.next(); …}
Traversing the Map
The efficiency of keySet is not as efficient as entrySet Iterator it = map.entrySet().iterator();
while(it.hasNext()){ Entry e =(Entry) it.next();
System.out.println("key"+e.getKey() + "value" + e.getValue());
Collection sort
Collections.sort();
1. Have you used HashMap? What is a HashMap? Why do you use it?
Used, HashMap is a non-synchronous implementation of the Map interface based on the hash table, which allows null keys and null values, and HashMap relies on the design of its data structure, storage efficiency is particularly high, which is why I use it.
2. Do you know how HashMap works? Do you know how the get() method of HashMap works?
The above two questions belong to the same answer
HashMap is implemented based on the hash algorithm. It stores the object into the HashMap through put(key, value), and can also get the object from the HashMap through get(key). When we use put,
First, the HashMap hashes the value of the hashCode() of the key, and the position of the element in the array is obtained according to the hash value, and the element is stored in the linked list at the position.
The returned hashCode is used to find the bucket location to store the Entry object.。
When we use get, first HashMap will hash the value of the key hashCode(), get the position of the element in the array according to the hash value, and take the element from the position. Take out of the linked list
3. What happens when the hashcodes of two objects are the same?
The hashcode is the same, indicating the same position of the two objects HashMap array,
(After finding the bucket location, the keys.equals() method is called to find the correct node in the list, and finally find the value object to be found. The perfect answer!)
Then HashMap will traverse each element in the list, and use the equals method of the key to determine whether it is the same key.
If it is the same key, the new value will overwrite the old value and return the old value. If it is not the same key, the chain header of the linked list stored at the location
"What happens when the hashcodes of the two objects are the same?" From here on, the real confusion begins. Some interviewers will answer because the hashcodes are the same, so the two objects are equal, the HashMap will throw an exception, or it won't Store them. The interviewer may then remind them that there are two methods, equals() and hashCode(), and tell them that the two objects are the same as the hashcode, but they may not be equal. Some interviewers may give up on this, while others can continue to advance. They answer, "Because the hashcodes are the same, their bucket locations are the same, and the 'collision' will happen. Because HashMap uses a linked list to store objects, this Entry contains key-value pairs. The Map.Entry object is stored in the linked list." This answer is very reasonable, although there are many ways to deal with collisions, this method is the simplest, and it is the HashMap processing method.
4. If the hashcodes of the two keys are the same, how do you get the value object?
Traverse each element in the HashMap list, perform hash calculation for each key, and finally get its corresponding value object by get method.
5. What if the size of the HashMap exceeds the capacity defined by the load factor?
The load factor defaults to 0.75. The HashMap exceeds the capacity defined by the load factor, that is, the value of the HashMap size*load factor is exceeded. Then the HashMap will create an array size twice the size of the original HashMap to re-adjust the map. Size and put the original object into a new bucket array
As your new capacity, this process is called resize or rehash
6. Do you know what is wrong with resizing HashMap?
In the case of multithreading, conditional competition may occur. When re-adjusting the size of the HashMap, there is indeed conditional competition. If both threads find that the HashMap needs to be resized,
They will try to resize at the same time. In the process of resizing, the order of the elements stored in the linked list will be reversed, because when moving to a new array position, the HashMap does not place the element at the end of the LinkedList.
is placed on the head, in order to avoid tail traversing. If conditional competition occurs, then it will loop.
7. Can we use a custom object as a key?
Yes, as long as it follows the definition rules for the equals() and hashCode() methods, and will not change when the object is inserted into the Map. If this custom object is immutable,
Then it has satisfied the condition as a key, because it cannot be changed after it is created.
8 When is the LinkedeHashMap used? Why use LinkedeHashMap?
For example, hashmap is slow to write and fast to read; linkedhashmap is an ordered list that reads slowly and writes fast; treeMap can help you automatically sort in ascending order.
ConcurrentHashMap, thread safe, fast read and write, and lock separation
9-The difference between ConcurrentHashMap and Hashtable
What is the difference between Hashtable and ConcurrentHashMap? They can all be used in a multi-threaded environment, but when the size of the Hashtable is increased to a certain level, performance will drop dramatically because it will need to be locked for a long time. Because ConcurrentHashMap introduces segmentation, no matter how large it becomes, it only needs to lock some part of the map, while other threads do not need to wait until the iteration is complete to access the map. In short, during the iteration, ConcurrentHashMap only locks a part of the map, and Hashtable locks the entire map.
10 But still did not say why use? Or what is its usage scenario?
ConcurrentHashMap and CopyOnWriteArrayList retain thread safety while also providing higher concurrency.
Sun’s grandfathers launched ConcurrentHashMap, which is thread-safe and fast to read and write. You are not blind to me, thread safety and read and write speed is definitely inversely proportional, how is it possible. After reading the source code, I know that this is a space-for-time structure, which is a bit like the distributed cache structure.
When creating, the memory is directly divided into 16 segments. Each segment is actually a stored hash table. When writing, first find the corresponding segment, then lock the segment. Write, unlock, sweat! It's so simple to solve, when the segment is locked, other segments can continue to work. It seems that listening is quite simple. In fact, the code of the uncles is really a headache. Everywhere is shifting, right and wrong. Take the code to calculate the storage location. How to evenly hash and reduce position collisions? If you are serious, you still have to sigh that your uncle is your uncle.
11- Can we use CocurrentHashMap instead of Hashtable?
This is another very popular interview question because ConcurrentHashMap is used by more and more people. We know that Hashtable is synchronized, but ConcurrentHashMap has better synchronization performance because it only locks a portion of the map based on the synchronization level. ConcurrentHashMap can of course replace HashTable, but HashTable provides more thread safety.
12 Can we synchronize HashMap?
Map m = Collections.synchronizeMap(hashMap);
**1. HashMap data structure**
There are arrays and linked lists in the data structure to store the data, but the two are basically two extremes.
Array
The array storage interval is continuous, taking up a lot of memory, so the space is very complicated. However, the binary search time of the array is small, which is O(1); the characteristics of the array are: easy to address, difficult to insert and delete;
Linked list
The linked list storage interval is discrete, and the occupied memory is relatively loose, so the space complexity is small, but the time complexity is very large, reaching O(N). The characteristics of the linked list are: difficulty in addressing, easy to insert and delete.
Hash table

So can we combine the characteristics of the two and make a data structure that is easy to address and easy to insert and delete? The answer is yes, this is the hash table we want to mention. Hash table ((Hash
table) not only satisfies the convenience of data search, but also does not occupy too much content space, and is also very convenient to use.
A hash table is composed of an array + linked list. In an array of length 16, each element stores the head node of a linked list. Then what kind of rules are these elements stored in the array? The general case is obtained by hash(key)%len, that is, the hash value of the key of the element is obtained by modulo the length of the array. For example, in the above hash table, 12% 16 = 12, 28% 16 = 12, 108% 16 = 12, 140% 16 = 12. So 12, 28, 108, and 140 are all stored in the array with the subscript 12.
First, a static inner class Entry is implemented in HashMap. The important attributes are key, value, next. From the attribute key, value, we can clearly see that Entry is a HashMap key-value pair. A basic bean implementation, we said above that the basis of HashMap is a linear array, this array is Entry[], the contents of the Map are stored in Entry[].
HashMap access implementation
// When storing:
Int hash = key.hashCode(); // This hashCode method is not detailed here, just understand that each key's hash is a fixed int value.
int index = hash % Entry[].length;
Entry[index] = value;
// When taking values:
int hash = key.hashCode();
int index = hash % Entry[].length;
return Entry[index];
Intelligent Recommendation
Do I need to change this when I blog for the first time?
The first time I wrote a blog, just in time for my first time learning unity and markdown syntax Try to write a catalog for yourself first Let’s start with unity cause after Then I started to bl...
Why do I need to use WiReshark Tools?
Wireshark is a very easy to use the captain tool, but for the classmates of the Ethernet Ethernet, we will use it. Through its own experience, I think the beginners use Wireshark because of learning t...
Why do I need to use WaitPid?
Why do I need to use WaitPid? MAN Page from Waitpid (): In the case of a terminated child, performing a wait allows the system to release the resources associated with the child; if a wait is not perf...
Why do I need to use MQ?
Supporting high concurrent, asynchronous decoupling, flow peak, reducing coupling degree. Synchronously send HTTP requests The client sends a request to the server side, and the server is implemented ...
When to use ConcurrentHashMap
Many colleagues have learned the principles of HashMap and ConcurrentHashMap, and also looked at the source code of the two classes, but still do not know under what circumstances to use ConcurrentHas...
More Recommendation
When do I need to inject Bean in Spring (which categories need to be injected and which classes do not need)?
When do I need to inject Bean in Spring (which categories need to be injected and which classes do not need)? I have to say that this is a valuable and once confused me. I once doubted what the purpos...
When do you use Ref and when do you need to Ref?
Articles directory Ref No Ref Ref "Beating my body, hurting her heart", use itrefEssence For example, if you click on the event to be bound to a tag, the event processing function must acces...
When do you need to use a list of initialization?
The initialization list is used to initialize the data of the class. The member list is initialized in the constructor, followed by the colon of the constructor. Refer to the following example: [cpp] ...
When do you need to use a volatile keyword?
If you want everyone to see the volatile keyword, but you know when you need to use the volatile keyword? Look directly below the code: When this program is compiled, if the compiler discovery program...
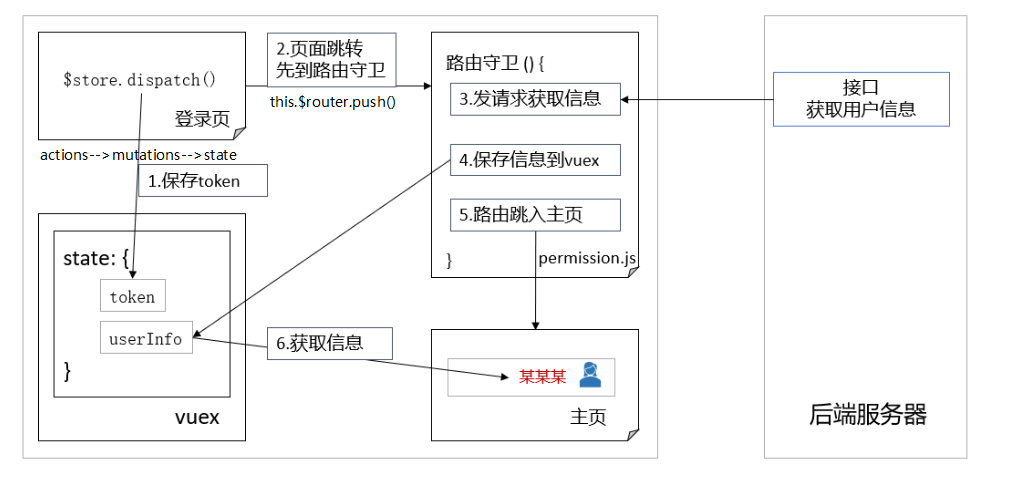
When do you need to use vuex?
When to use vuex? Only when you can't manage data well, you need to use Vuex Specifically, it is generally divided into two categories: 1. When a component needs to dispatch events multiple times The ...