Analysis of Netty thread model
The Netty thread model is based on the Reactor thread model, and the Reactor thread model is divided into a single thread model, a multi-thread model, and a master-slave Reactor multi-thread model. Reactor's threading model is based on synchronous and non-blocking IO. Proactor is based on asynchronous and non-blocking IO (here we do not analyze Proactor). Let's study the Reactor thread model and its application in the Netty thread model.
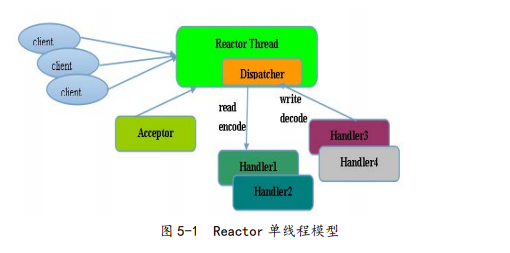
1. Reactor single-threaded model
The schematic diagram is as follows:

Reactor single-threaded model, as the name suggests, is a single NIO thread to complete all IO operations. The specific tasks are:
a. Responsible for reading the request / response message of the communication peer
b. Responsible for sending request / response messages to the communication peer
c. As a server, receiving client connection requests
d. As a client, send a connection request to the server
As can be seen from the schematic diagram, one thread of NIO multiplexes, the event dispatcher and processing are all taken up by themselves. The Reactor thread mode uses synchronous non-blocking IO, that is, the IO operations on the thread will not be blocked Impact, in theory, the above work can indeed be done by one thread (select will actively poll which IO operations are ready), working process: Acceptor receives the TCP request from the client, after the link is successfully established, through the dispatcher Hand the ByteBuf to the corresponding Handler for processing.
For some small-flow applications, the above single-threaded model can be used, but it is not suitable for large load and high concurrency situations. The main reasons are:
a. When an IO thread processes millions or even tens of millions of links, the performance will be insufficient and the CPU may be overwhelmed.
b. When an IO thread is overloaded, it will not be processed in time, which will cause the client to wait for a long time and continue to timeout and reconnect, the customer experience is extremely poor
c. Once this IO thread has an infinite loop, it will cause the entire program to be unavailable.
In order to make up for the above shortcomings, Reactor multi-thread model is proposed
2. Reactor multithreading model
The schematic diagram is as follows:

The analysis from the schematic diagram is as follows:
a. There is a special NIO thread Acceptor responsible for listening to the server, handling the client's TCP connection, including security verification, etc.
b. After the Acceptor is processed, send the IO operation to the NIO thread pool. The thread pool can be implemented using the JDK's thread pool, which contains a task queue and N threads. These threads are responsible for reading, encoding, decoding, and sending information.
c. One NIO thread can process N links at the same time, but one link can only correspond to one thread, avoiding the problem of concurrency
The Reactor multi-threading model satisfies most of the application scenarios, but the disadvantage is that when faced with a million-level request that requires security authentication, because authentication is a performance-consuming operation, a performance bottleneck will occur in an Acceptor thread.
In order to solve the above problems, a master-slaveReactorMultithreading model
3. Master-slave Reactor multithreading model
The schematic diagram is as follows:

From the schematiccanIt can be seen that it is not an NIO thread that processes the client connection request, but an NIO thread pool. After the Acceptor thread processes the client's TCP access request (which may include verification), the newly created SocketChannel is registered with the IO thread An IO thread in the pool (Sub Reactor) handles operations such as reading, encoding, decoding, and sending. The Acceptor thread is only responsible for listening to the server, processing the client's TCP connection and authentication requests. After the link is successfully established, the link is registered in the thread of the Sub Reactor Thread Pool.
The master-slave Reactor multi-threading model solves the performance bottleneck problem a lot. At this time, Netty recommends the use of threadsmodel
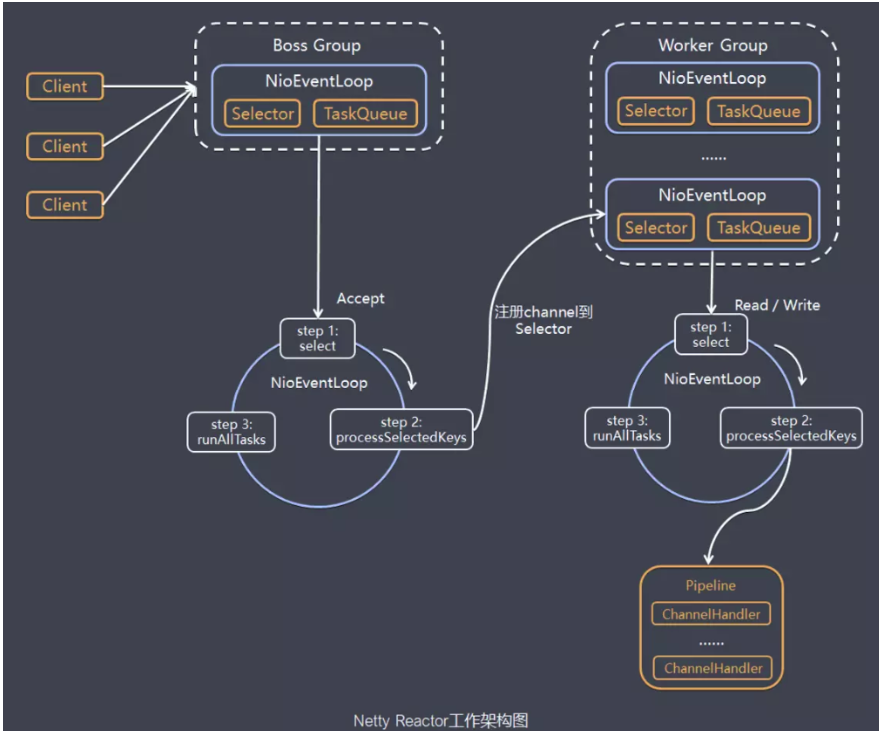
4. Netty's threading model
The schematic diagram is as follows:

Netty's thread model can choose the thread model by setting the startup class parameters. Netty supports Reactor's single-thread model, multi-thread, and master-slave Reactor multi-thread model.
As can be seen from the schematic diagram, two NioEventLoopGroups are created when the server starts, which are two independent Reactor thread pools, one is the boss thread pool, and the other is the worker thread pool. The two divisions of labor are clear, one is responsible for receiving client connection requests, and the other is responsible for handling IO related read and write operations, or to perform Task tasks, or perform scheduled Task tasks. The number of NioEventLoop in NioEventLoopGroup defaults to the number of processor cores * 2.
By configuring the number of threads in the boss thread pool and the worker thread pool and whether to share the thread pool, configure single-threaded, multi-threaded, master-slave Reactor multi-threaded.
The tasks of the Boss thread pool:
a. Receive the client's connection request and initialize the channel parameters
b. Notify ChannelPipeline when the link status changes
The role of worker thread pool
a. Asynchronously read the message from the communication peer and send the read event to ChannelPipeline
b. Send the message asynchronously to the communication peer, call the send message interface of ChannelPipeline
c. Perform system task
d. Perform system task tasks
4.1 System Task
The reason for creating them is that when the IO thread and the user thread are operating on the same resource, the problem of lock contention will occur, so the user thread is encapsulated as a Task and handed over to the IO thread for serial processing to achieve local lock-free
4.2 Timing Task
Mainly used for timing actions such as monitoring and inspection
For the above reasons, NioEventLoop is not just an IO thread, it is also responsible for scheduling user threads.
The schematic diagram of the NioEventLoop processing chain is as follows:

In order to improve performance, many places within Netty have adopted a local lock-free design. For example, serialization operations are used inside the IO thread to avoid multi-thread lock competition. On the surface, this will result in low CPU utilization, but as long as multiple serialized IO threads are configured for concurrent operation, the CPU utilization can be improved, and the performance ratio is better.
After Netty's NioEventLoop reads the data, it will directly call ChannelPipeline's fireChannelRead (Object msg) method, as long as the user does not switch threads,NioEventLoopThe user's handler will always be called without thread switching. This is the specific performance of serialization, which can well avoid the problem of lock competition and improve performance.
4.3 Main points of Netty thread model setting
a. Create two NioEventLoopGroup, namely NIO Acceptor thread pool and NIO IO thread pool
b. The codec needs to be placed in the NIO Handler, not in the user thread
c. Try not to create user threads in ChannelHandler, you can dispatch POJO to the back-end business thread pool after decoding
d. If the IO operation is not complicated and does not involve database blocking, disk reading, network read and write operations that may be blocked, you can complete the business logic directly in the handler called by NIO instead of putting it in the user thread. Ground, if the IO business logic is complex, it will seriously affect performance, so POJOs need to be packaged into Task objects and dispatched to the business thread pool for processing to ensure that NIO threads are not occupied for a long time and cause false death.
Intelligent Recommendation
5 Netty thread model
When we discuss the Netty threading model, we usually first think of the classic Reactor threading model. Although different NIO frameworks have different implementations of the Reactor mode, they ess...
Netty thread model (middle)
1. background 1.1. Amazing performance dataData analysis and enterprise architectureData-driven personalized recommendation under JD 618 promotionHow to build an artificial intelligence product resear...
Netty | rectify thread model
Two common business scenarios CPU-intensive: computing type; IO-intensive: waiting type, such as relying on other microservices and databases; CPU intensive Keep the current thread model and reuse the...

2.2.1 Netty thread model
Introduction to Netty Netty is a high-performance, highly scalable asynchronous event-driven network application framework, which greatly simplifies network programming such as TCP and UDP client and ...
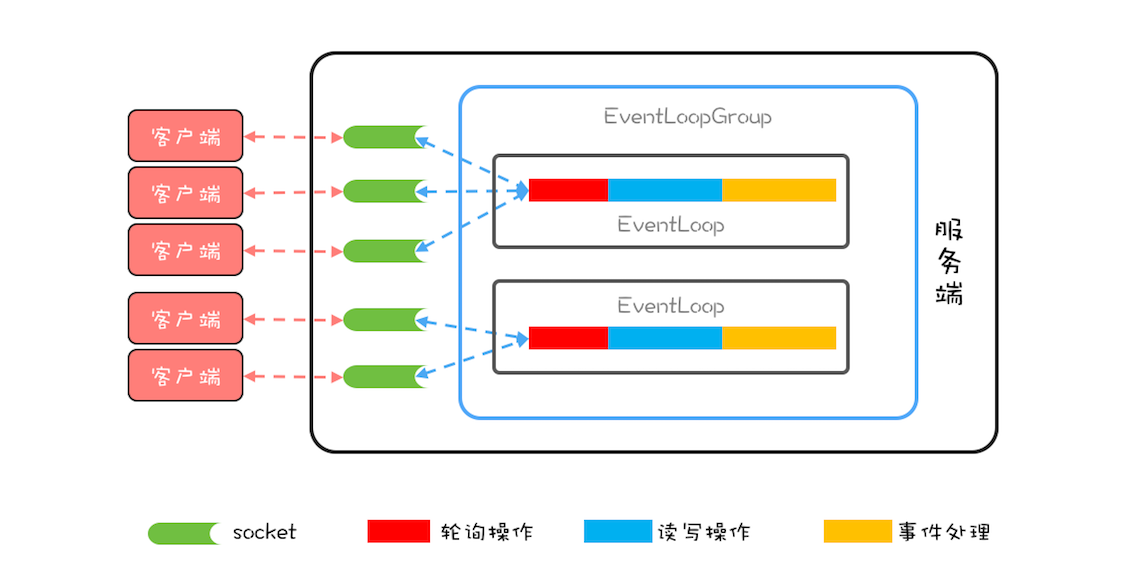
Thread model in Netty
The core concept in Netty isEvent loop (EventLoop), Which is actually Reactor in Reactor mode,Responsible for monitoring network events and calling event handlers for processing.In the 4.x version of ...
More Recommendation
Netty features and thread model
Zero copy hard driver - kernel buffer - protocol engine only DMA copy avoids cpu copy There was actually a cpu copy of kernel buffer - socket buffer, but the copied information can rarely be ignored; ...
013. NETTY thread model
Introduction to Netty Netty is a high-performance, high-scalable asynchronous event-driven network application framework, which greatly simplifies network programming such as TCP and UDP clients and s...
Netty thread model and basics
Why use Netty Netty is an asynchronous event-driven web application framework for rapid development of maintainable high-performance and high-profile servers and clients. Netty has the advantages of h...
Netty thread model and gameplay
Event cycle group All I / O operations in Netty are asynchronous, and the asynchronous execution results are obtained by channelfuture. Asynchronously executes a thread pool EventLoopGroup, it ...
Redis source code parsing: 09redis database implementations (key operation, key timeout function key space notification)
This chapter of the Redis database server implementations are introduced, indicating achieve Redis database-related operations, including key-value pairs in the database to add, delete, view, update a...