CUDA: shared memory for matrix multiplication
Shared memory is allocated using the __shared__ qualifier.
Related Reading:
CUDA programming interface: run initialization and device memory
CUDA programming interface: compatibility with nvcc compiler
CUDA programming interface: how to compile CUDA programs with nvcc
CUDA programming model: memory hierarchy and heterogeneous programming
CUDA programming model: an overview of the kernel and thread hierarchy
As mentioned in the previous article, shared memory should be faster than global memory, the details will be introduced in subsequent articles. Any opportunity to access shared memory instead of global memory should be explored, as shown in the matrix multiplication example below. The following code is a direct implementation of matrix multiplication and does not utilize shared memory. Each thread reads a row of A and a column of B, and then calculates the corresponding element in C, as shown in Figure 1. In this way, A reads B.width times and B reads A.height times.
// Matrices are stored in row-major order:
// M(row, col) = *(M.elements + row * M.width + col)
typedef struct {
int width;
int height;
float* elements; } Matrix;
// Thread block size
#define BLOCK_SIZE 16
// Forward declaration of the matrix multiplication kernel
__global__ void MatMulKernel(const Matrix, const Matrix, Matrix);
// Matrix multiplication - Host code
// Matrix dimensions are assumed to be multiples of BLOCK_SIZE
void MatMul(const Matrix A, const Matrix B, Matrix C) {
// Load A and B to device memory
Matrix d_A; d_A.width = A.width;
d_A.height = A.height;
size_t size = A.width * A.height * sizeof(float);
cudaMalloc((void**)&d_A.elements, size);
cudaMemcpy(d_A.elements, A.elements, size, cudaMemcpyHostToDevice);
Matrix d_B;
d_B.width = B.width;
d_B.height = B.height; size = B.width * B.height * sizeof(float);
cudaMalloc((void**)&d_B.elements, size);
cudaMemcpy(d_B.elements, B.elements, size, cudaMemcpyHostToDevice);
// Allocate C in device memory
Matrix d_C;
d_C.width = C.width;
d_C.height = C.height;
size = C.width * C.height * sizeof(float);
cudaMalloc((void**)&d_C.elements, size);
// Invoke kernel
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
dim3 dimGrid(B.width / dimBlock.x, A.height / dimBlock.y);
MatMulKernel<<<dimGrid, dimBlock>>>(d_A, d_B, d_C);
// Read C from device memory cudaMemcpy(C.elements, Cd.elements, size, cudaMemcpyDeviceToHost);
// Free device memory cudaFree(d_A.elements); cudaFree(d_B.elements);
cudaFree(d_C.elements);
}
// Matrix multiplication kernel called by MatMul()
__global__ void MatMulKernel(Matrix A, Matrix B, Matrix C)
{
// Each thread computes one element of C
// by accumulating results into Cvalue
float Cvalue = 0;
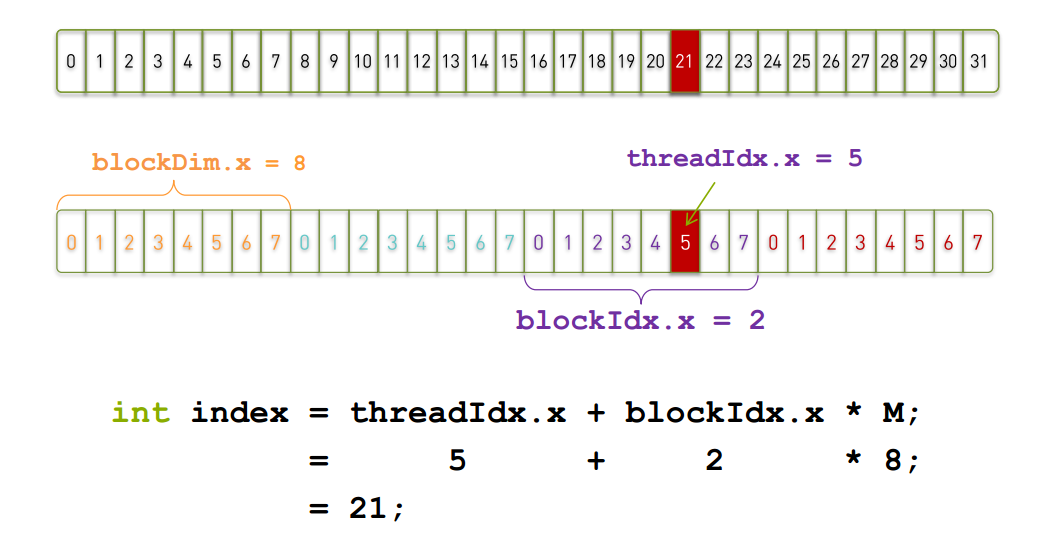
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
for (int e = 0; e < A.width; ++e) Cvalue += A.elements[row * A.width + e] * B.elements[e * B.width + col];
C.elements[row * C.width + col] = Cvalue;
} 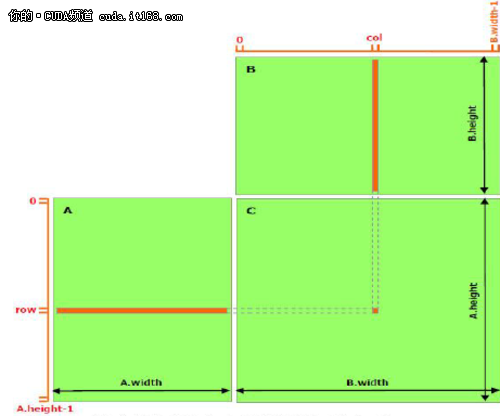
▲ Figure 1 Matrix multiplication without shared memory
The following example code uses shared memory to achieve matrix multiplication. In this implementation, each thread block is responsible for calculating a small square matrix Csub, Csub is a part of C, and each thread in the block calculates an element of Csub. as shown in picture 2. Csub is equal to the product of two rectangular matrices: A's sub-matrix size is (A.width, block_size), row index is the same as Csub, B's sub-matrix size is (block_size, A.width), column index is the same as Csub. In order to satisfy the resources of the device, the two rectangular sub-matrices are divided into square matrices of size block_size, and Csub is the sum of these square matrix products. The calculation of each multiplication is like this. First, two corresponding square matrices are loaded into the shared memory from the global memory. The loading method is that one thread loads one matrix element, and then one thread calculates one element of the product. Each thread accumulates the result of each multiplication and writes it to the register, and then writes it to the global memory after the end.
In this way of dividing the calculation into blocks, the use of fast shared memory saves a lot of global memory bandwidth, because in global memory, A is only read (B.width / block_size) times while B reads (A. height / block_size) times.
The Matrix type in the previous code adds a stride field, so that the submatrix can be effectively represented by the same type. The __device__ function (mentioned in the related reading article) is used to read and write elements and create sub-matrices from the matrix.
// Matrices are stored in row-major order:
// M(row, col) = *(M.elements + row * M.stride + col)
typedef struct {
int width;
int height; int stride;
float* elements;
}
Matrix;
// Get a matrix element
__device__ float GetElement(const Matrix A, int row, int col)
{
return A.elements[row * A.stride + col];
}
// Set a matrix element
__device__ void SetElement(Matrix A, int row, int col, float value)
{
A.elements[row * A.stride + col] = value;
}
// Get the BLOCK_SIZExBLOCK_SIZE sub-matrix Asub of A that is
// located col sub-matrices to the right and row sub-matrices down
// from the upper-left corner of A
__device__ Matrix GetSubMatrix(Matrix A, int row, int col) {
Matrix Asub;
Asub.width = BLOCK_SIZE;
Asub.height = BLOCK_SIZE;
Asub.stride = A.stride;
Asub.elements = &A.elements[A.stride * BLOCK_SIZE * row + BLOCK_SIZE * col];
return Asub;
}
// Thread block size #define BLOCK_SIZE 16
// Forward declaration of the matrix multiplication kernel
__global__ void MatMulKernel(const Matrix, const Matrix, Matrix);
// Matrix multiplication - Host code
// Matrix dimensions are assumed to be multiples of BLOCK_SIZE
void MatMul(const Matrix A, const Matrix B, Matrix C)
{
// Load A and B to device memory Matrix d_A;
d_A.width = d_A.stride = A.width;
d_A.height = A.height;
size_t size = A.width * A.height * sizeof(float);
cudaMalloc((void**)&d_A.elements, size);
cudaMemcpy(d_A.elements, A.elements, size, cudaMemcpyHostToDevice);
Matrix d_B;
d_B.width = d_B.stride = B.width;
d_B.height = B.height;
size = B.width * B.height * sizeof(float);
cudaMalloc((void**)&d_B.elements, size);
cudaMemcpy(d_B.elements, B.elements, size,cudaMemcpyHostToDevice);
// Allocate C in device memory Matrix d_C;
d_C.width = d_C.stride = C.width;
d_C.height = C.height;
size = C.width * C.height * sizeof(float); cudaMalloc((void**)&d_C.elements, size);
// Invoke kernel dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
dim3 dimGrid(B.width / dimBlock.x, A.height / dimBlock.y);
MatMulKernel<<<dimGrid, dimBlock>>>(d_A, d_B, d_C);
// Read C from device memory cudaMemcpy(C.elements, d_C.elements, size, cudaMemcpyDeviceToHost);
// Free device memory cudaFree(d_A.elements); cudaFree(d_B.elements);
cudaFree(d_C.elements);
}
// Matrix multiplication kernel called by MatMul()
__global__ void MatMulKernel(Matrix A, Matrix B, Matrix C) {
// Block row and column
int blockRow = blockIdx.y;
int blockCol = blockIdx.x;
// Each thread block computes one sub-matrix Csub of C
Matrix Csub = GetSubMatrix(C, blockRow, blockCol);
// Each thread computes one element of Csub
// by accumulating results into Cvalue
float Cvalue = 0;
// Thread row and column within Csub
int row = threadIdx.y;
int col = threadIdx.x;
// Loop over all the sub-matrices of A and B that are
// required to compute Csub
// Multiply each pair of sub-matrices together
// and accumulate the results
for (int m = 0; m < (A.width / BLOCK_SIZE); ++m) {
// Get sub-matrix Asub of A
Matrix Asub = GetSubMatrix(A, blockRow, m);
// Get sub-matrix Bsub of B
Matrix Bsub = GetSubMatrix(B, m, blockCol);
// Shared memory used to store Asub and Bsub respectively
__shared__ float As[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE];
// Load Asub and Bsub from device memory to shared memory
// Each thread loads one element of each sub-matrix
As[row][col] = GetElement(Asub, row, col);
Bs[row][col] = GetElement(Bsub, row, col);
// Synchronize to make sure the sub-matrices are loaded
// before starting the computation
__syncthreads();
// Multiply Asub and Bsub together
for (int e = 0; e < BLOCK_SIZE; ++e)
Cvalue += As[row][e] * Bs[e][col];
// Synchronize to make sure that the preceding
// computation is done before loading two new
// sub-matrices of A and B in the next iteration
__syncthreads(); }
// Write Csub to device memory
// Each thread writes one element
SetElement(Csub, row, col, Cvalue);
} 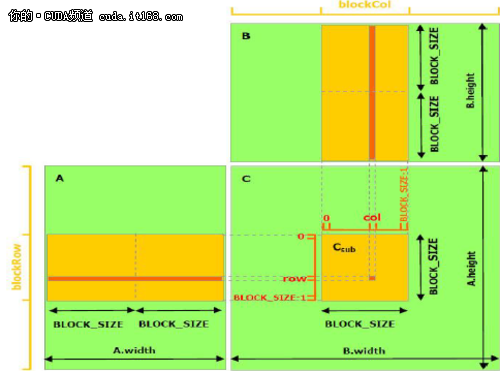
▲ Figure 2 Matrix multiplication using shared memory
Intelligent Recommendation
CUDA PYTHON matrix multiplication
CUDA PYTHON matrix multiplication One, CUDA thread index 2. CUDA matrix calculation 1. Convolution calculation 2. Matrix multiplication Three, CUDA shared memory Four, CUDA python matrix multiplicatio...
Multiplication of CUDA vector and matrix
I have been busy with matrix multiplication due to learning needs, and I have completed the code of one-dimensional index and two-dimensional index. Although it is still There are many shortcomings, b...
CUDA Shared_Memory Matrix Multiplication
The control code and the following description are helpful....
CUDA programming matrix multiplication
CUDA programming matrix multiplication Just a simple example a n*n X b n * n a line of a line of * b as a thread Code Matmul.cu https://github.com/Smallflyf...
CUDA programming --Matrix Multiplication
Calculation matrix A \mathbf{A} A Matrix B \mathbf{B} B The result, where A ∈ R 1000 × 800 \mathbf{A}\in\mathbb{R}^{1000\times800} A∈R1000×800, B ∈ R 800 × 1200 \mathb...
More Recommendation
CUDA SHARED MEMORY
In the global memory section, data alignment and continuation are important topics. When using L1, the alignment problem can be ignored, but non-contiguous memory acquisition will still degrade perfor...
About CUDA-shared memory
Shared memory can only be shared by threads in one block. Shared memory cannot be shared between different blocks. The key to simply declaring a shared memory is __shared__ Declare an array like Dynam...
cuda programming shared memory
@cuda shared memory programming...
cuda cases of shared memory
1. Code 2. Description The above code, __ shared__ shared memory for all threads within a block, the block that is its life cycle life cycle, which can only be accessed by threads within the block. __...

CUDA memory (2) shared memory shared memory
other: CUDA memory (1) register table of Contents Shared memory Sort using shared memory: Test Results Shared memory Shared memory is actually a level 1 cache that can be controlled by the user. [1] I...