Spark source understanding withScope
tags: spark
Spark source understanding withScope
When you understand the role of each operator by looking at the RDD source code, you can always see withScope, withScope what is it?
First you need to know a few things: scala currying, loan pattern
Scala currying
In scala, a currying function supports multiple parameter lists when applied, rather than just one. When the first call passes only the first argument, it returns a function value for the second call.
scala> def curriedSum(x: Int)(y: Int) = x + y
curriedSum: (x: Int)(y: Int)
scala> curriedSum(1)(2)
res1: Int = 3
scala> val add3 = curriedSum(3)_
add3: Int => Int = <function1>
scala> add3(4)
res2: Int = 7
curriedSum(3)_in_Is a placeholder, indicating that the second parameter is not passed first, and the return value is a function value.
We look at the RDD source code
/**
* Execute a block of code in a scope such that all new RDDs created in this body will
* be part of the same scope. For more detail, see {{org.apache.spark.rdd.RDDOperationScope}}.
*
* Note: Return statements are NOT allowed in the given body.
*/
Private[spark] def withScope[U](body: => U): U = RDDOperationScope.withScope[U](sc)(body) // Here is the currying
Loan pattern
Extract the public part (function body) into a method, and pass the non-public part through the function value.
/**
* Execute the given body such that all RDDs created in this body will have the same scope.
*
* If nesting is allowed, any subsequent calls to this method in the given body will instantiate
* child scopes that are nested within our scope. Otherwise, these calls will take no effect.
*
* Additionally, the caller of this method may optionally ignore the configurations and scopes
* set by the higher level caller. In this case, this method will ignore the parent caller's
* intention to disallow nesting, and the new scope instantiated will not have a parent. This
* is useful for scoping physical operations in Spark SQL, for instance.
*
* Note: Return statements are NOT allowed in body.
*/
private[spark] def withScope[T](
sc: SparkContext,
name: String,
allowNesting: Boolean,
ignoreParent: Boolean)(body: => T): T = {
// Save the old scope to restore it later
val scopeKey = SparkContext.RDD_SCOPE_KEY
val noOverrideKey = SparkContext.RDD_SCOPE_NO_OVERRIDE_KEY
val oldScopeJson = sc.getLocalProperty(scopeKey)
val oldScope = Option(oldScopeJson).map(RDDOperationScope.fromJson)
val oldNoOverride = sc.getLocalProperty(noOverrideKey)
try {
if (ignoreParent) {
// Ignore all parent settings and scopes and start afresh with our own root scope
sc.setLocalProperty(scopeKey, new RDDOperationScope(name).toJson)
} else if (sc.getLocalProperty(noOverrideKey) == null) {
// Otherwise, set the scope only if the higher level caller allows us to do so
sc.setLocalProperty(scopeKey, new RDDOperationScope(name, oldScope).toJson)
}
// Optionally disallow the child body to override our scope
if (!allowNesting) {
sc.setLocalProperty(noOverrideKey, "true")
}
Body // non-public part
} finally {
// Remember to restore any state that was modified before exiting
sc.setLocalProperty(scopeKey, oldScopeJson)
sc.setLocalProperty(noOverrideKey, oldNoOverride)
}
}
Because each RDD operator method has a common part and a common parameter, so use the scope with the scope to encapsulate the public part code, use Cory to pass the common parameters first.
Then the non-public part code is passed in via the second parameter. Here the body parameter is the non-public part function value.
Understanding operator
/**
* Return a new RDD by applying a function to all elements of this RDD.
*/
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}
Here is an example, the map method
In fact, this is equivalent to directly calling the withScope method, followed by the function literals inside the curly braces, which are parameters.
In scala, when a method has only one argument, curly brackets can be used instead of parentheses.
Intelligent Recommendation
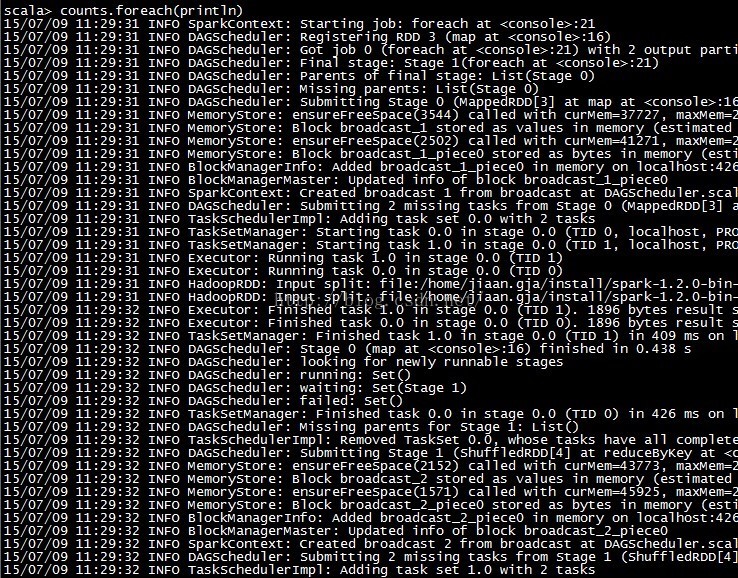
"In-depth understanding of SPARK: core ideas and source code analysis" (Chapter 1)
I have sacrificed 7 months of weekends and free time after work. By studying the source code and principles of Spark, the book "In-depth Understanding of Spark: Core Ideas and Source Code Analysi...
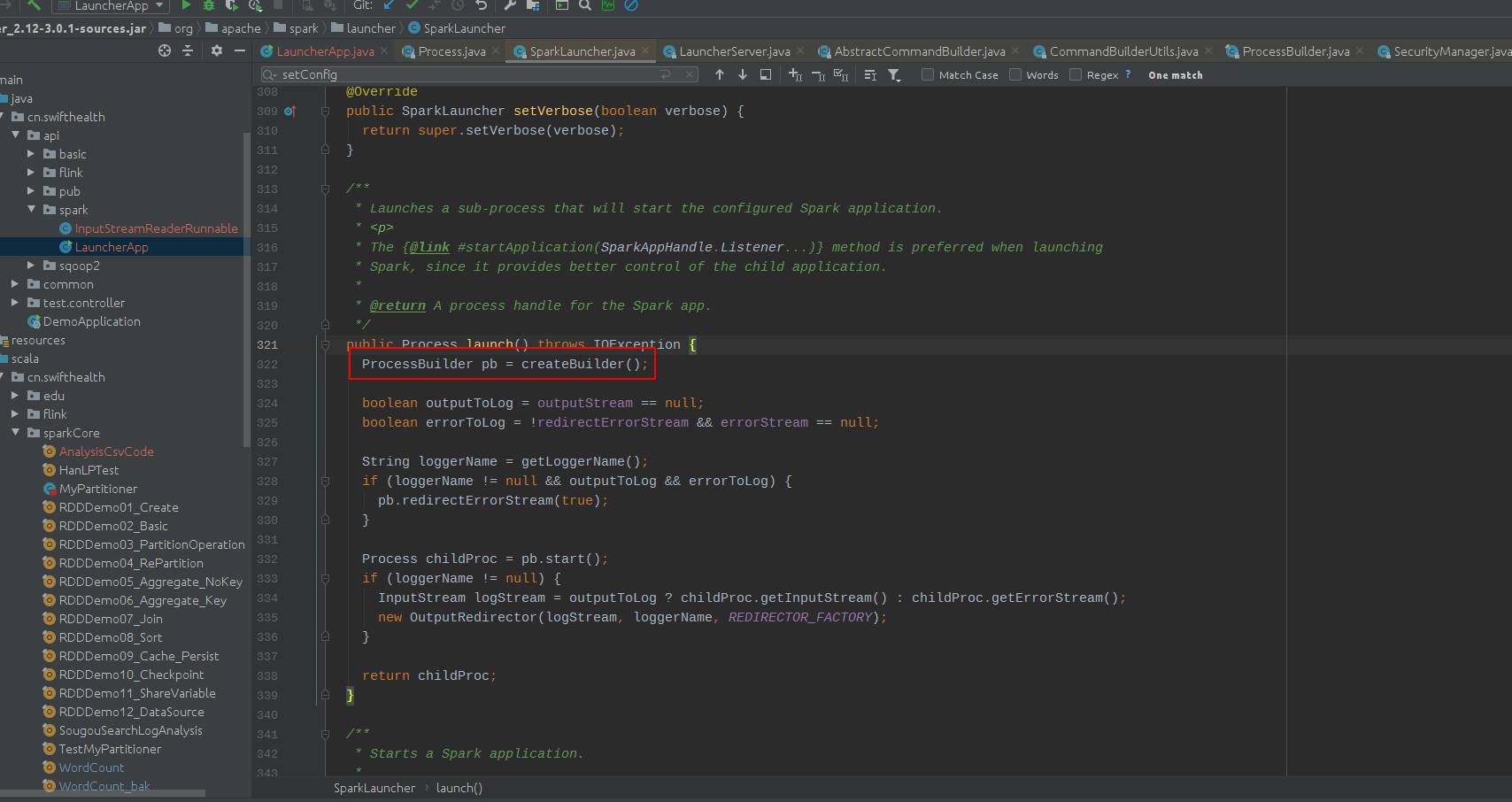
SparkLauncher class (Java calls Spark task source code understanding)
(1) Turn on the process of processing the spark app through the launch () method (2) There are two important ways in point into the createBuilder () method. (3) Click FindsparkSubmit () method Positio...
Initial understanding and understanding of spark
Learn about hadoop system and scala language before learning about spark 1. concept Spark is a fast, versatile and scalable big data analytics engine The spark ecosystem has evolved into a collection ...
"In-depth understanding of Spark: core ideas and source code analysis" - Section 3.12 Spark environment update
This section of the book is from Chapter 3 of the Huazhang Community "In-depth understanding of Spark: Core Thoughts and Source Code Analysis", Section 3.12 Spark Environment Update, author ...

"In-depth understanding of Spark - core ideas and source code analysis" (2) Chapter 2 Spark design concepts and basic architecture...
If Rove takes the righteousness of the heavens and the earth, and the defense of the six qis, he will swim infinitely, and he will be awkward? - "Zhuangzi. Happy Travel" Translation: ...
More Recommendation
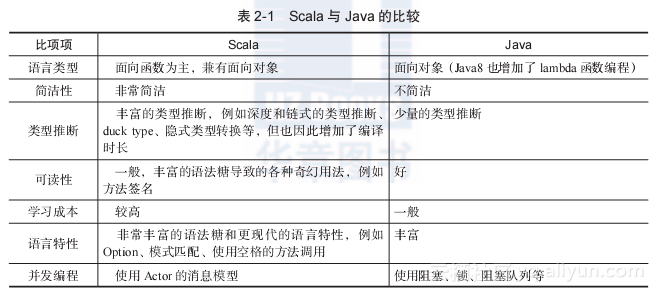
"In-depth understanding of Spark: core ideas and source code analysis"-Section 2.2 Spark basics
The book excerpt of this section comes from Chapter 2 and Section 2.2 of the book "In-depth Understanding of Spark: Core Ideas and Source Code Analysis" in Huazhang Community. The author Gen...
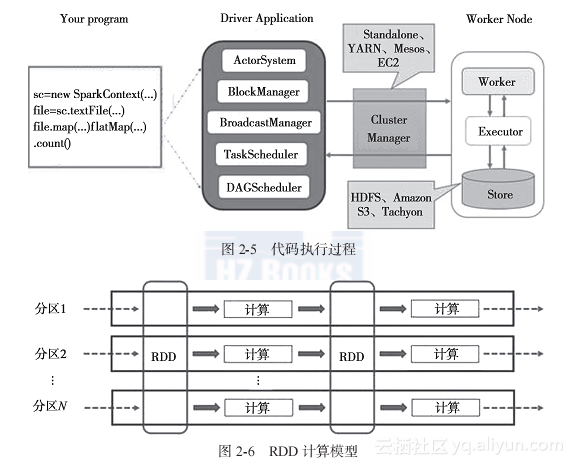
"In-depth understanding of Spark: core ideas and source code analysis"-Section 2.3 Spark basic design ideas
The book excerpt of this section comes from Chapter 2 and Section 2.3 of the book "In-depth Understanding of Spark: Core Ideas and Source Code Analysis" from Huazhang Community, author Geng ...
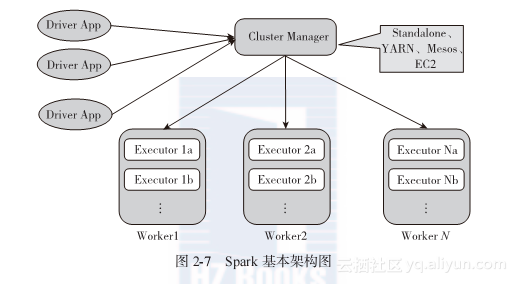
"In-Depth Understanding of Spark: Core Ideas and Source Code Analysis"-Section 2.4 Spark Basic Architecture
This section is an excerpt from Chapter 2 and Section 2.4 of the book "In-depth Understanding of Spark: Core Ideas and Source Code Analysis" in Huazhang Community. The author Geng Jia'an, th...
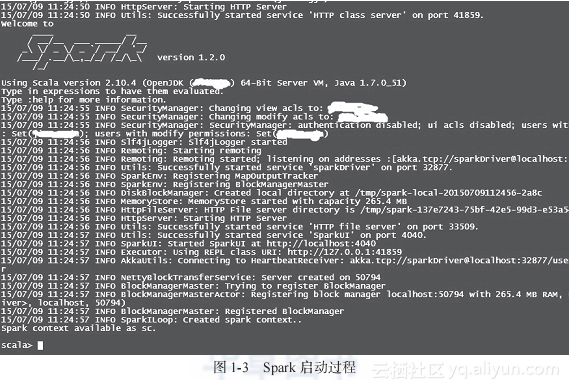
"Deep Understanding of Spark: Core Ideas and Source Code Analysis"-Section 1.2 First Experience with Spark
The book excerpt of this section comes from Chapter 1 and Section 1.2 of the book "In-depth Understanding of Spark: Core Ideas and Source Code Analysis" in Huazhang Community. The first expe...

[Spark] Deep understanding of Spark localization
spark.locality.wait 3s How long to wait to launch a data-local task before giving up and launching it on a less-local node. The same wait will be used to step through multiple locality levels (...