Deep learning optimization algorithm analysis and python implementation
tags: Deep learning optimization python Neural Networks
Preface
Sort out the optimization algorithms used before to facilitate the reproduction of Learning to learn by gradient descent by gradient descent paper work. The author uses LSTM optimizer to replace traditional optimizers such as (SGD, RMSProp, Adam, etc.), and then uses gradient descent to optimize The optimizer itself, if you are interested, you can take a look at this paper. It’s a little bit to accumulate a little. What will be the final result?
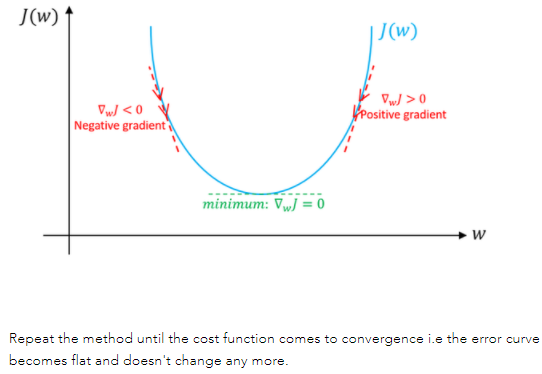
1. Gradient Descent
Gradient descentIt is an iterative method that can be used to solve least squares problems (both linear and nonlinear). When solving the model parameters of the machine learning algorithm, that is, the unconstrained optimization problem,Gradient descent(Gradient Descent) is one of the most commonly used methods
pyhton implementation code
def update_parameters_with_gd(parameters, grads, learning_rate):
L = len(parameters) // 2 # Number of neural network layers
# Update gradient
for l in range(L):
parameters["W" + str(l+1)] = parameters["W" + str(l + 1)] - learning_rate * grads["dW" + str(l + 1)]
parameters["b" + str(l+1)] = parameters["b" + str(l + 1)] - learning_rate * grads["db" + str(l + 1)]
return parameters
Batch Gradient Descent
Batch gradient descentIs the most primitive form, it refers toEvery iterationuseAll samplesTo update the gradient
advantage:
(1) One iteration is to perform calculations on all samples. At this time, the matrix is used to perform operations to achieve parallelism.
(2) The direction determined by the full data set can better represent the sample population, and thus more accurately face the direction of the extreme value. When the objective function is a convex function, BGD must be able to obtain the global optimum.
Disadvantages:
(1) When the number of samples mm is large, all samples need to be calculated in each iteration step, and the training process will be slow. In terms of the number of iterations, the number of BGD iterations is relatively small.
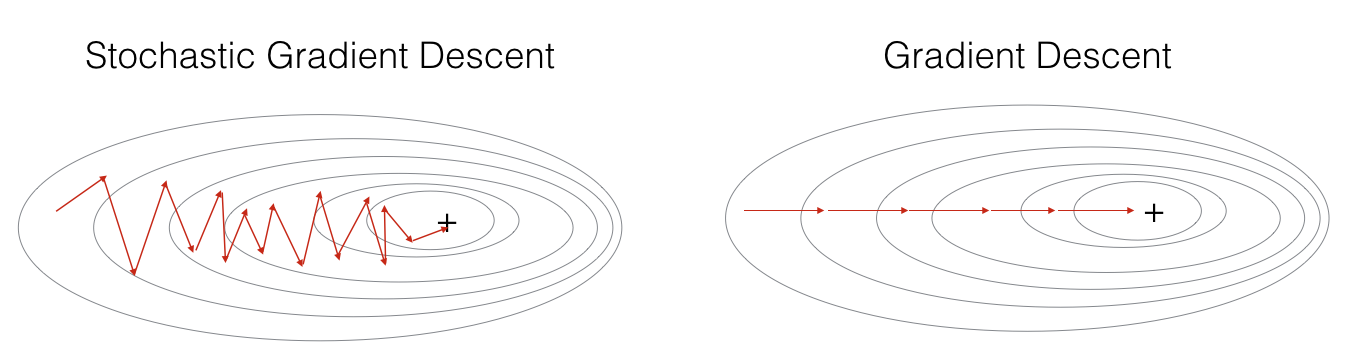
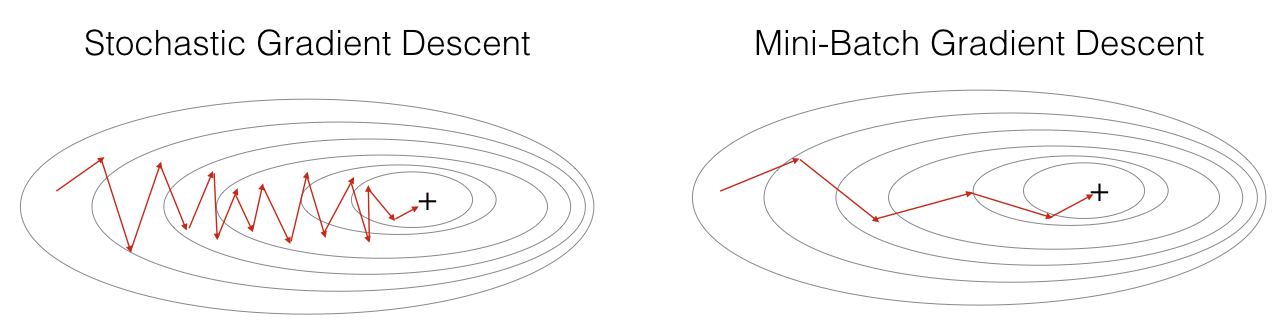
Stochastic Gradient Descent
Stochastic gradient descentUnlike batch gradient descent, stochastic gradient descent isEvery iterationuseA sampleTo update the parameters. Makes training speed faster.
advantage:
(1) Because it is not the loss function on all training data, but in each iteration, the loss function on a certain piece of training data is randomly optimized, so that each round of parameter update The speed is greatly accelerated.
Disadvantages:
(1) The accuracy is reduced. Because even when the objective function is a strong convex function, SGD still cannot achieve linear convergence.
(2) may converge to a local optimum, because a single sample cannot represent the trend of the entire sample.
(3) is not easy to implement in parallel.
2. Exponential weighted average
Exponential weighted average(Exponentially weighted averges), also called exponentially weighted moving average, is a commonly used method of processing sequence data.
When using exponential weighted average, if the deviation between the first few estimates V_t and the actual θ_t is too large, the deviation correction is required, namely:
When t is small, β is useful; when t is large, β^t approaches 0.
3. Momentum gradient descent method (momentum)
Calculate the weighted average of the gradient and use the weighted average to follow the new gradient. Generally speaking, the momentum gradient descent is faster than the standard gradient descent.
Gradient update formula:
Gradient Descent each step is independent of the previous gradient, and momentum can get the previous gradient.
pyhton implementation code
def initialize_velocity(parameters):
L = len(parameters) // 2 # Number of neural network layers
v = {}
# Initialize velocity
for l in range(L):
v["dW" + str(l+1)] = np.zeros_like(parameters["W" + str(l + 1)])
v["db" + str(l+1)] = np.zeros_like(parameters["b" + str(l + 1)])
return v
def update_parameters_with_momentum(parameters, grads, v, beta, learning_rate):
L = len(parameters) // 2 # Number of neural network layers
# Update the parameters of each layer
for l in range(L):
# Calculate velocities
v["dW" + str(l+1)] = beta * v["dW" + str(l + 1)] + (1 - beta) * grads["dW" + str(l + 1)]
v["db" + str(l+1)] = beta * v["db" + str(l + 1)] + (1 - beta) * grads["db" + str(l + 1)]
# Update parameters
parameters["W" + str(l+1)] = parameters["W" + str(l + 1)] - learning_rate * v["dW" + str(l + 1)]
parameters["b" + str(l+1)] = parameters["b" + str(l + 1)] - learning_rate * v["db" + str(l + 1)]
return parameters, v
4.RMSprop(root mean square prop)
RMSPropThe full name of the algorithm is Root Mean Square Prop, which is an optimization algorithm proposed by Geoffrey E. Hinton in the Coursera course. In order to further optimize the problem of excessive swing amplitude in the update of the loss function, and further accelerate the convergence speed of the function, RMSProp The algorithm uses the gradient of weight W and bias bDifferential square weighted average。
Gradient update formula:
Both RMSprop and momentum can eliminate gradient swings to a certain extent.
pyhton implementation code
def initialize_S(parameters):
L = len(parameters) // 2
s = {}
for l in range(L):
s["dW" + str(l+1)] = np.zeros_like(parameters["W" + str(l + 1)])
s["db" + str(l+1)] = np.zeros_like(parameters["b" + str(l + 1)])
return s
def update_parameters_with_RMSprop(parameters, grads, s, beta, learning_rate):
L = len(parameters)
for l in range(L):
s["dW" + str(l+1)] = beta * s["dW" + str(l + 1)] + (1 - beta) * np.square(grads["dW" + str(l + 1)])
s["db" + str(l+1)] = beta * s["db" + str(l + 1)] + (1 - beta) * np.square(grads["db" + str(l + 1)])
parameters["W" + str(l+1)] = parameters["W" + str(l + 1)] - learning_rate * grads["dW" + str(l + 1)]/np.sqrt(s["dW" + str(l + 1)]+1e-8)
parameters["b" + str(l+1)] = parameters["b" + str(l + 1)] - learning_rate * grads["db" + str(l + 1)]/np.sqrt(s["db" + str(l + 1)]+1e-8)
return parameters, s
5.Adam
With the above two optimization algorithms, one can use momentum similar to that in physics to accumulate gradients, and the other can make the convergence faster while making the amplitude of fluctuations smaller. Then the combination of the two algorithms will achieve better performance.Adam(Adaptive Moment Estimation) The algorithm is toMomentum algorithmwithRMSProp algorithmAn algorithm used in combination.
Gradient update formula:
(1)momentum
(2)RMSprop
(3) Correction deviation
(4) Update
pyhton implementation code
def initialize_adam(parameters) :
L = len(parameters)
v = {}
s = {}
for l in range(L):
v["dW" + str(l + 1)] = np.zeros_like(parameters["W" + str(l + 1)])
v["db" + str(l + 1)] = np.zeros_like(parameters["b" + str(l + 1)])
s["dW" + str(l + 1)] = np.zeros_like(parameters["W" + str(l + 1)])
s["db" + str(l + 1)] = np.zeros_like(parameters["b" + str(l + 1)])
return v, s
def update_parameters_with_adam(parameters, grads, v, s, t, learning_rate = 0.01,
beta1 = 0.9, beta2 = 0.999, epsilon = 1e-8):
L = len(parameters) // 2
v_corrected = {}
s_corrected = {}
for l in range(L):
v["dW" + str(l + 1)] = beta1 * v["dW" + str(l + 1)] + (1 - beta1) * grads["dW" + str(l + 1)]
v["db" + str(l + 1)] = beta1 * v["db" + str(l + 1)] + (1 - beta1) * grads["db" + str(l + 1)]
#Calculate the estimated value after the deviation correction of the first stage, input "v, beta1, t", output: "v_corrected"
v_corrected["dW" + str(l + 1)] = v["dW" + str(l + 1)] / (1 - np.power(beta1,t))
v_corrected["db" + str(l + 1)] = v["db" + str(l + 1)] / (1 - np.power(beta1,t))
#Calculate the moving average of the squared gradient, input: "s, grads, beta2", output: "s"
s["dW" + str(l + 1)] = beta2 * s["dW" + str(l + 1)] + (1 - beta2) * np.square(grads["dW" + str(l + 1)])
s["db" + str(l + 1)] = beta2 * s["db" + str(l + 1)] + (1 - beta2) * np.square(grads["db" + str(l + 1)])
#Calculate the estimated value after the deviation correction of the second stage, input: "s, beta2, t", output: "s_corrected"
s_corrected["dW" + str(l + 1)] = s["dW" + str(l + 1)] / (1 - np.power(beta2,t))
s_corrected["db" + str(l + 1)] = s["db" + str(l + 1)] / (1 - np.power(beta2,t))
#Update parameters, input: "parameters, learning_rate, v_corrected, s_corrected, epsilon". Output: "parameters".
parameters["W" + str(l + 1)] = parameters["W" + str(l + 1)] - learning_rate * (v_corrected["dW" + str(l + 1)] / np.sqrt(s_corrected["dW" + str(l + 1)] + epsilon))
parameters["b" + str(l + 1)] = parameters["b" + str(l + 1)] - learning_rate * (v_corrected["db" + str(l + 1)] / np.sqrt(s_corrected["db" + str(l + 1)] + epsilon))
return parameters, v, s
Reference: Wu Enda Deeplearning Course
Intelligent Recommendation
Optimizer algorithm and python implementation of deep learning
opitimizers 1. Optimizer algorithm 1.1 SGD algorithm SGD algorithm without momentum: θ ← θ − l r ∗ g \theta \leftarrow \theta - lr * g θ←θ−lr&lowas...
Optimization problems in deep learning and optimization algorithm realization (1) optimization problem analysis
Two challenges of optimization in deep learning: local minimum and saddle point (1) Local minimum : For the objective function f(x), if the value of f(x) is smaller than other values adjacent to x, ...

Deep learning optimization algorithm summary
This article summarizes the optimization learning algorithms that are used in deep learning. 1 Optimization algorithm in deep learning Optimization algorithm discussed two issues: (1) Local minimum ...
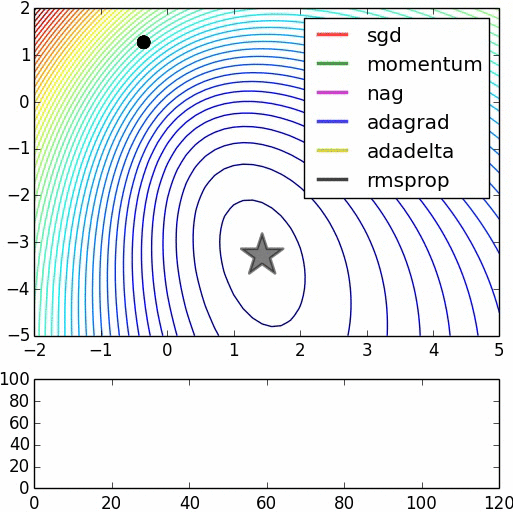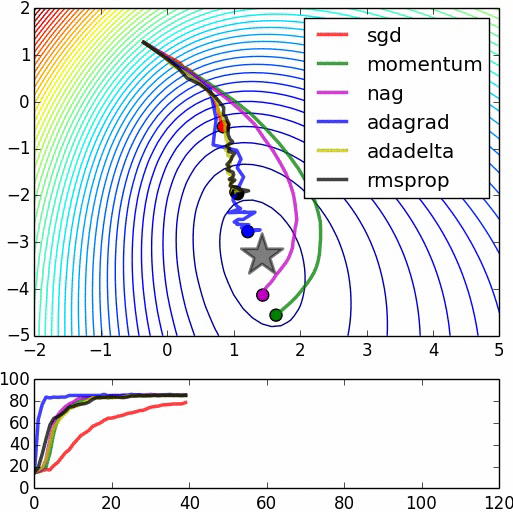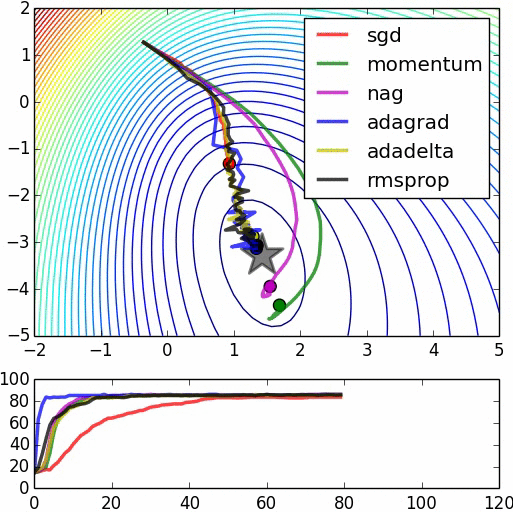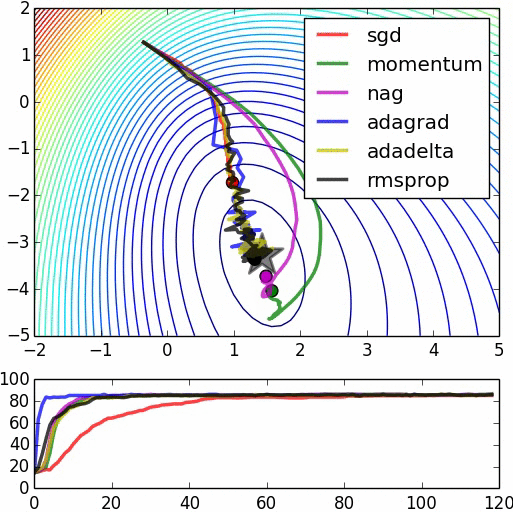
3.1 Deep learning optimization algorithm
3.1 Deep learning optimization algorithm learning target aims Know the local optimal problem, saddle points and Hessian matrix Explain the optimization of batch gradient descent algorithm Explain thre...

Deep learning notes: optimization algorithm
1. Mini batch gradient descent The traditional batch gradient descent is to vectorize all samples into a matrix. Each iteration traverses all samples and performs a parameter update. In this way, the ...
More Recommendation
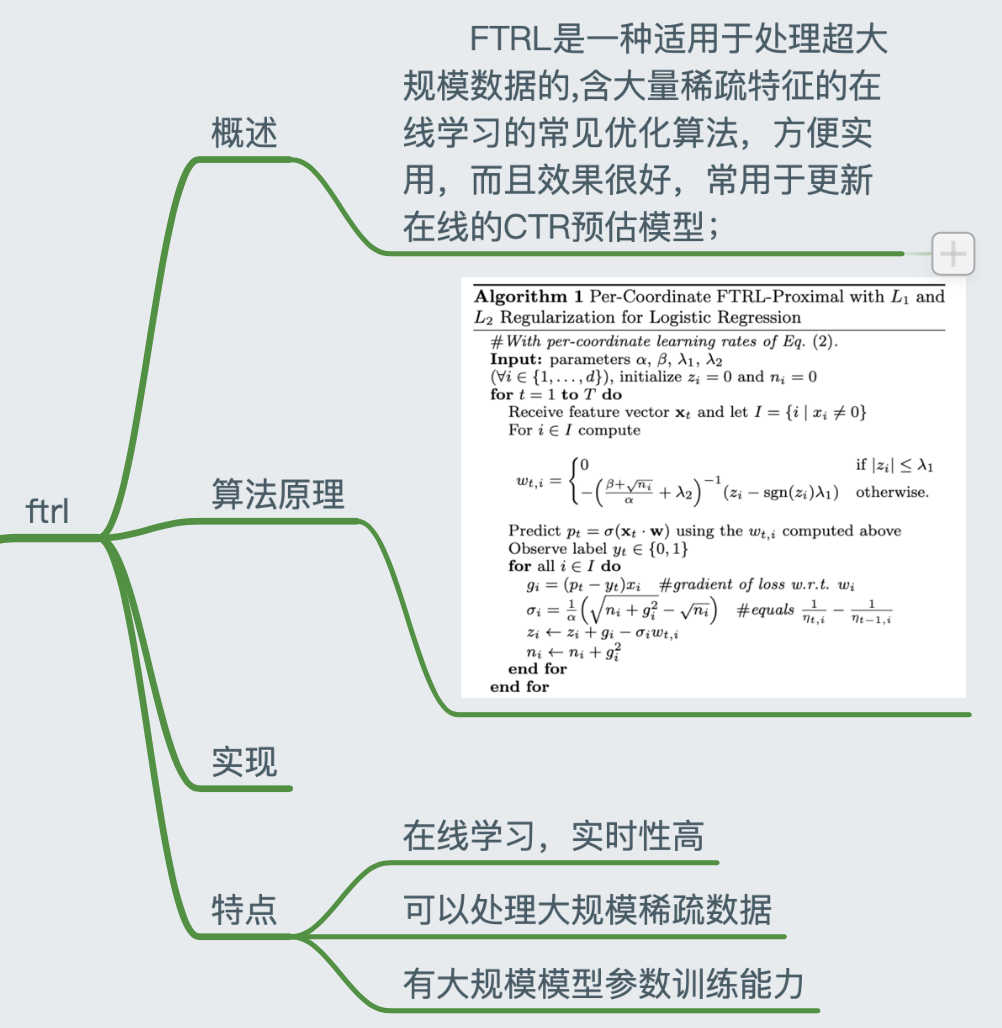
Optimization algorithm in deep learning SGD
Before Introduce the decline of gradient, there are three forms of common gradient decline:BGD、SGD、MBGDTheir difference is how much data is used to calculate the gradient of the target function。 Most ...
Optimization algorithm of deep learning notes
Articles directory 1. Optimization algorithm 1.1 Basic algorithm 1.1.1 Random gradient decrease (SGD) 1.1.2 momentum 1.2 Adaptive learning rate algorithm 1.2.1 AdaGrad 1.2.2 RMSProp 1.2.3 Adam 1.3 New...
Summary of deep learning optimization algorithm
Momentum algorithm The introduction of Momentum can solve the "canyon" and "saddle point" problems while accelerating SGD In the case of a gradient with high curvature, small ampli...

Deep learning python implementation
This article is to seeIntroduction to deep learning (based on Python theory and implementation)The study notes made by this book. This article ignores the mathematical principles of neural netw...