Machine Learning Chapter 9 Classic KMEANS Exercise (Watermelon Data Collection 4.0)
tags: Machine learning Cluster kmeans
1. Code part
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams["font.sans-serif"] = ["SimHei"]
class Kmeans:
def __init__(self,k,epochs,data):
'''
: Param K: Polytes
: Param Epochs: Ievant
: Param Data: Watermelon Data Collection Two -dimensional array
'''
self.k = k
self.epochs = epochs
self.data = data
self.center_points = []
# Get the initial random cluster center point
for i in range(self.k):
self.center_points.append(self.data[np.random.randint(0, len(self.data))])
self.center_points = np.array(self.center_points, dtype=float)
def calc_dist(self,a):
dist = (self.center_points - a)**2
mean_dists = np.mean(dist,axis=1)
return mean_dists.argmin()
def process_iter(self):
# kmeans core iteration process
for i in range(self.epochs):
self.cluster = {}
for i in range(len(self.data)):
index = self.calc_dist(self.data[i])
if index not in self.cluster:
self.cluster[index] = [self.data[i]]
else:
self.cluster[index].append(self.data[i])
self.upgrade()
# Update center cluster
def upgrade(self):
for i in range(self.k):
# print(self.cluster[i])
self.center_points[i] = np.array(self.cluster[i]).mean(axis=0)
def get_cluster(self):
return self.cluster
# Function
def plot_scatter(self):
# Scatter
color = ['b','c','g','k','m','r','w','y']
for i in range(self.k):
x = np.array(self.cluster[i])[:,0]
y = np.array(self.cluster[i])[:,1]
plt.scatter(x,y,c=color[i])
print(self.center_points)
#
x = self.center_points[:,0]
y = self.center_points[:,1]
plt.scatter(x,y,marker='+',c='r')
plt.title('Watermelon dataset 4.0 cluster result'+'epoch{}'.format(self.epochs))
plt.xlabel('density')
plt.ylabel('Sweetness')
plt.show()
def load_data():
data = pd.read_csv("watermelon4.0.csv")
data = pd.DataFrame(data)
print(data,data.shape)
data_t = []
len = data.shape[0]
for i in range(len):
data_t.append([data["density"][i],data["sugercontent"][i]])
return data_t
def main():
data = load_data()
kmeans = Kmeans(3,100,data)
kmeans.process_iter()
print(kmeans.get_cluster())
kmeans.plot_scatter()
if __name__ == '__main__':
main()
2. Experimental results
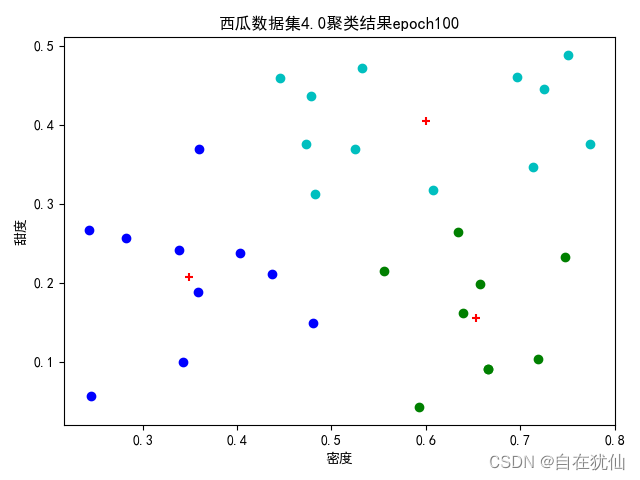
2.1 Cluster (three central vectors)
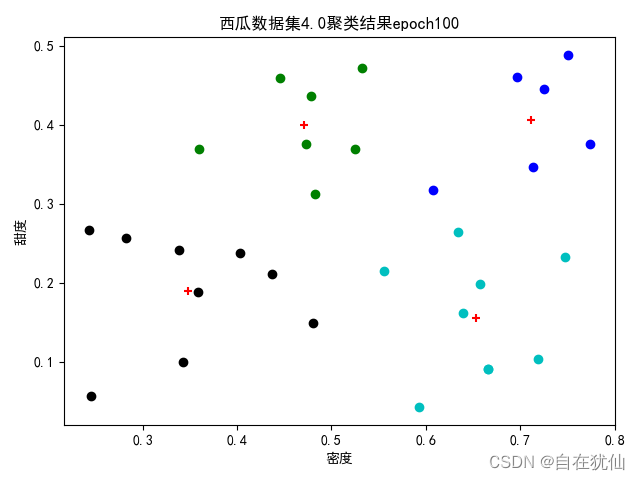
2.2 Cluster (four central vectors)
Intelligent Recommendation
Machine Learning Watermelon Book Chapter 9 Clustering --- k-means algorithm (with c ++ code)
This article is about some conclusions drawn by reference to the machine learning watermelon book during machine learning. Some of the formulas are not listed one by one. As a beginner,It may not be w...

Machine Learning (Zhou Zhihua) Watermelon Book Chapter 9 After-Class Exercises 9.10-Python Implementation
Machine Learning (Zhou Zhihua) Watermelon Book Chapter 9 After-Class Exercise 9.10-Python Implementation Experiment title Try to design an improvement that can automatically determine the number of cl...

Machine Learning (watermelon book) notes - the first chapter
Chapter One Introduction 1.1 Introduction For what is machine learning, the book gives an explanation: working on machine learning how to calculate the means, use the experience to improve the perform...

Machine Learning (watermelon Book) - The first chapter
This book introduces get the results from the data: Code: https: //github.com/Tsingke/Machine-Learning_ZhouZhihua After-school exercise: https: //blog.csdn.net/snoopy_yuan/article/details/62045353 &nb...
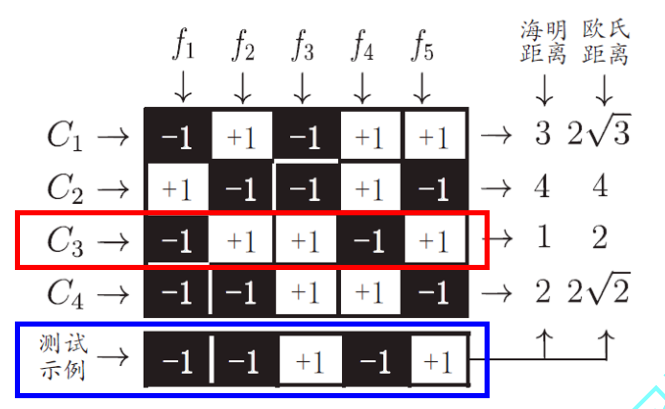
Machine Learning (Watermelon Book) Chapter Three Notes
Part5About multi-class learning The above two methods can analyze the advantages of the model from the perspective of storage overhead and training time. Hamming distance:Is to compare the numbe...
More Recommendation
Machine Learning (Watermelon Book) Chapter 2
This note was taken during the study of the book "Machine Learning" by teacher Zhou Zhihua Part1 Empirical error and overfitting Accuracy=1-error rate Generalization error: error on the new ...

Machine Learning Watermelon Book-Chapter 1 Introduction
Overall evaluation: Simple, concept oriented Knowledge points: machine learning: machine learning Mitchell gave a more formal definition in 1997: Suppose that P is used to evaluate the performance of ...
"Machine Learning" Watermelon Book Exercises Chapter 4
exercise 4.1 Try to prove that for a training set that does not contain conflicting data (that is, the feature vectors are exactly the same but the labels are different), there must be a decision tree...
"Machine Learning" Watermelon Book Exercises Chapter 3
exercise 3.1 Try to analyze under what type ( 3.2 ) (3.2) (3.2) Do not need to consider the offset term b b b . mentioned in the book, you can put x x x with b b b Absorb into vector form w ^ = ( w...
Machine learning - Watermelon books first, second chapter
Chapter One Introduction basic concepts Data set: Collection of all data Training set: Collection of training samples Attributes (feature): a matter of a thing or object in a certain aspect Property v...