Semantic similarity calculation of pretrained models (VI)--cross-encoder
tags: Natural Language Processing Deep Learning
The models for semantic similarity calculation mentioned above are basically double tower structures. The main advantage of the double tower structure is the fast similarity calculation. The fast here refers not to the inference speed of the model's single data, but to the calculation in a large number of question scenarios, such as the recall scenarios of similar questions. Because the double tower model actually produces a single question expression, the similarity calculation is just a simple calculation at the end, and the most time-consuming question expression operation can be completed offline. Cross-encoder performs splicing input when inputting the model, so that the two questions interact deeper, and similar sentence tasks are completed directly in the model, rather than just the semantic representation model of the questions. Therefore, the similar calculation effect of cross-encoder is also significantly better than that of bi-encoder with a double tower structure, but cross-encoder cannot get the vector representation of the question. Similar calculations between a large number of questions require real-time model inference calculations and consume more time. Cross-encoder is suitable for a small number of candidate question scenarios, so we can use it in the sorting stage of question questions to obtain better similar recognition effects.
The model structure is as follows. The bi-encoder with a double tower structure on the left is the cross-encoder structure on the right.
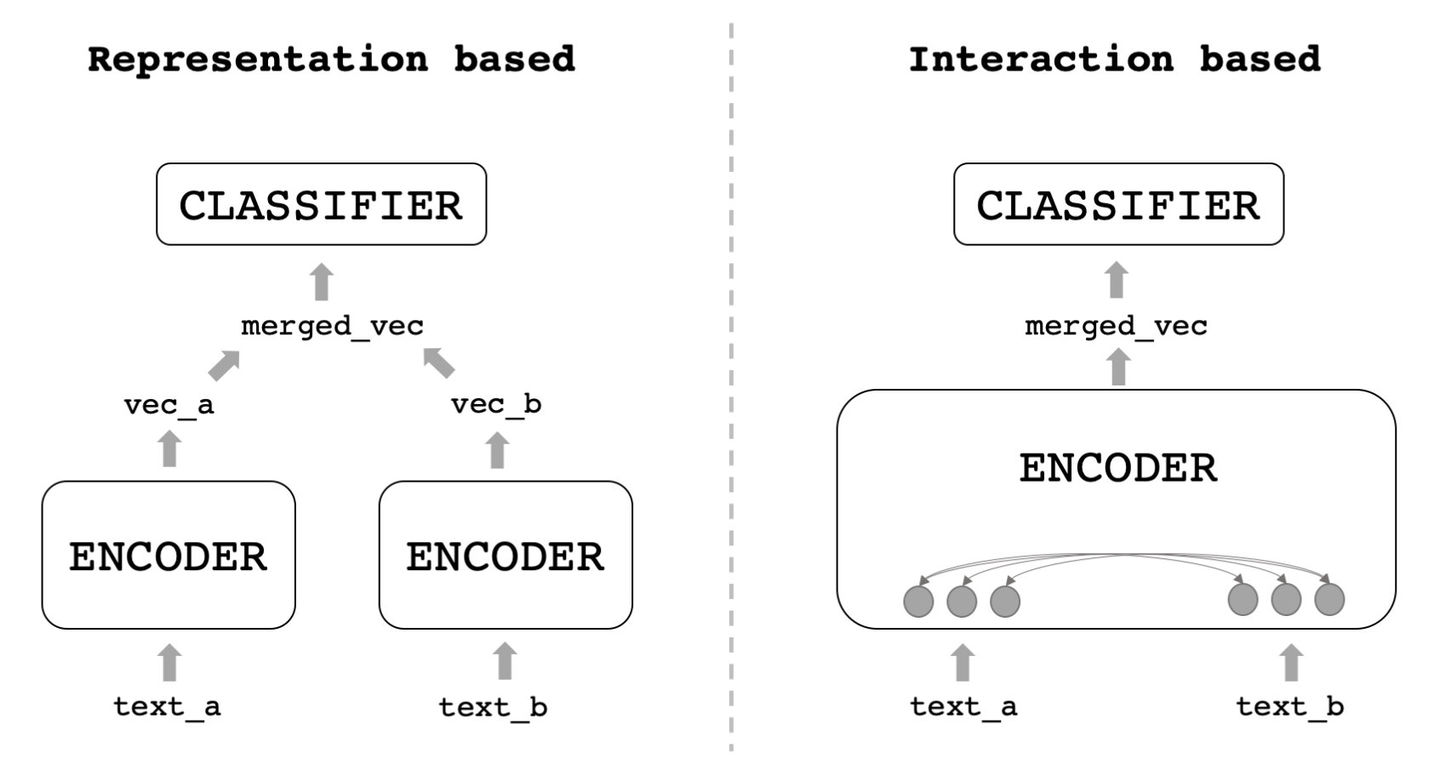
Source of the picture:21 classic deep learning inter-sentence relationship models|Code & Skills - Zhihu
Experiment
| hfl/chinese-roberta-wwm-ext(5 epoch) | 96.25% | 82.03% | 87.46% |
| hfl/chinese-roberta-wwm-ext-large(5 epoch) | 96.78% | 81.98% | 87.71% |
| hfl/chinese-electra-180g-large-discriminator(5 epoch) | 97.11% | 81.56% | 87.63% |
| hfl/chinese-roberta-wwm-ext(q1,q2 exchange)(1 epoch) | 96.69% | 83.30% | 88.41% |
| hfl/chinese-roberta-wwm-ext(q1,q2 exchange)(5 epoch) | 97.11% | 81.60% | 87.66% |
Tests were carried out on different pre-trained models. As in the table, hfl/chinese-roberta-wwm-ext(390M), hfl/chinese-roberta-wwm-ext-large(1.2G), and hfl/chinese-electra-180g-base-discriminator(1.2G) were used respectively. Perhaps because the training set data volume is already relatively large (50w+), the benefits of the pre-trained model after it becomes larger are not particularly obvious. During training, it was found that the effect of cross-encoder will also improve after exchanging two questions and adding them to the training set again, because the difference in sentence position was eliminated. Another point is that cross-encoder does not require too much training time. It has achieved better results with 1 epoch, which is better than 5 epoch.
Intelligent Recommendation
3-4 text semantic similarity calculation
The answer is pre-stored, and one or one is given. head -20 vocab.txt The CLS itself is the output of the CLS corresponding to the CLS, which is the result of the interaction of the model for the rear...

Fine-tune with Pretrained Models
1 Fine-tune with Pretrained Models 2 9.2. Fine tuning A common technique in migration learning: fine tuning. As shown in Figure 9.1, fine tuning consists of the follow...

Java's word meaning similarity calculation (semantic recognition, words emotional trend, similarity forest similarity, pinyin similarity, conceptual similarity, literal similarity)
Java's word meaning similarity calculation (semantic recognition, words emotional trend, similarity forest similarity, pinyin similarity, conceptual similarity, literal similarity) 1. Calculation of w...
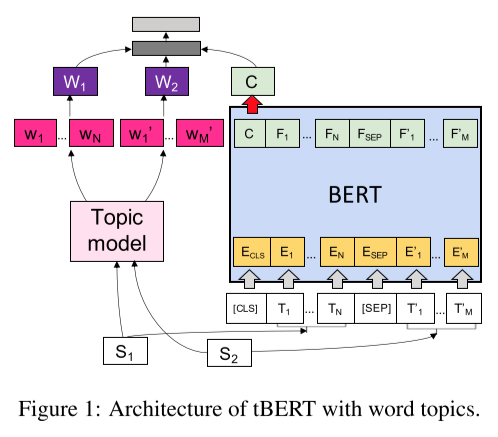
tBERT: Topic Models and BERT Joining Forces for Semantic Similarity Detection
tBERT: Topic Models and BERT Joining Forces for Semantic Similarity Detection The article was published in ACL2020. Here is a brief record of the main content of this article. Model...
Pretrained models for Pytorch (Work in progress)
Original link: The goal of this repo is: to help to reproduce research papers results (transfer learning setups for instance), to access pretrained ConvNets with a unique interface/API inspired by tor...
More Recommendation
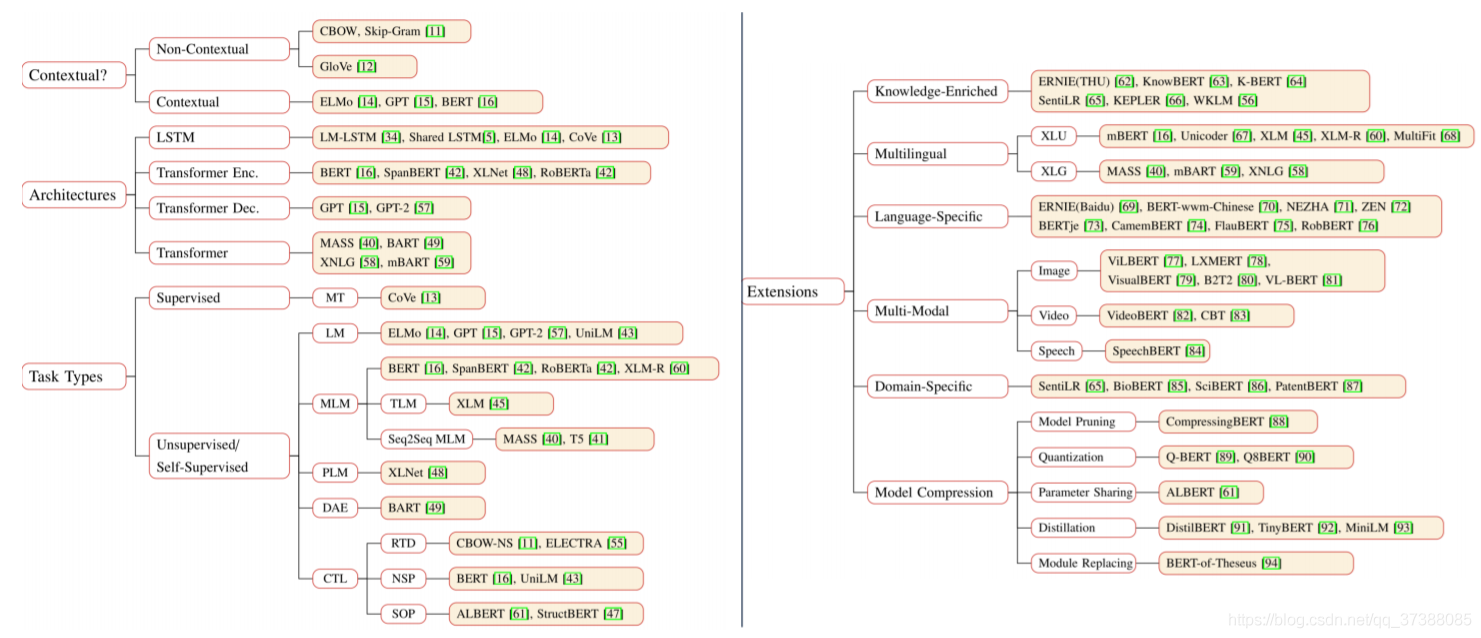
Pretrained models in natural language processing
Write the directory title here Pre-trained model classification system Typical Model Bert SpanBert StructBert XLNet T5 GPT-3 Extension of pre-trained models Knowledge-Enriched PTMs Multilingual and La...
Transformer-based semantic similarity calculation model DSSM and code open source
github:https://github.com/makeplanetoheaven/NlpModel/tree/master/SimNet/TransformerDSSM background knowledge byKnowledge Based Questions and Answers (KBQA) - Semantic Dependency Analysis and Code Open...
WordNet related API introduction and semantic similarity calculation method
WordNet Introduction WordNet is a cognitive linguistic English dictionary designed by PRINCETON psychologists, linguists and computer engineers. It is not light to arrange words in alphabetical order,...
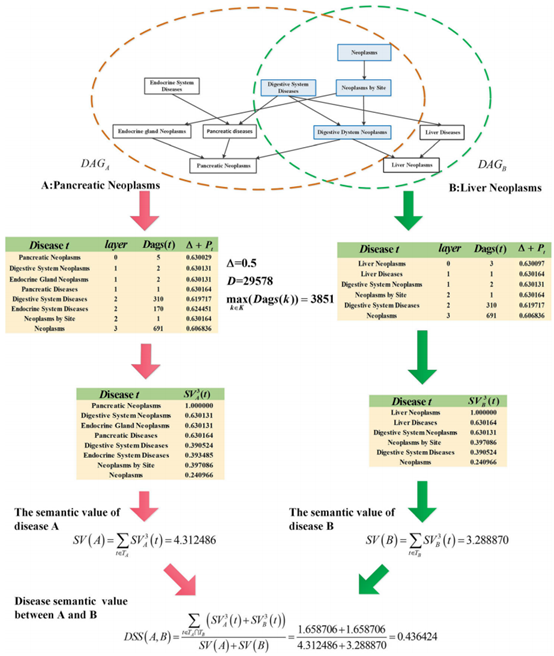
"Idssim: LNCRNA function similarity calculation model based on improved disease semantic similarity method"
Quote: Fan W, Shang J, Li F, Sun Y, Yuan S, Liu JX. IDSSIM: an lncRNA functional similarity calculation model based on an improved disease semantic similarity method. BMC Bioinformatics. 2020 Jul 31;2...
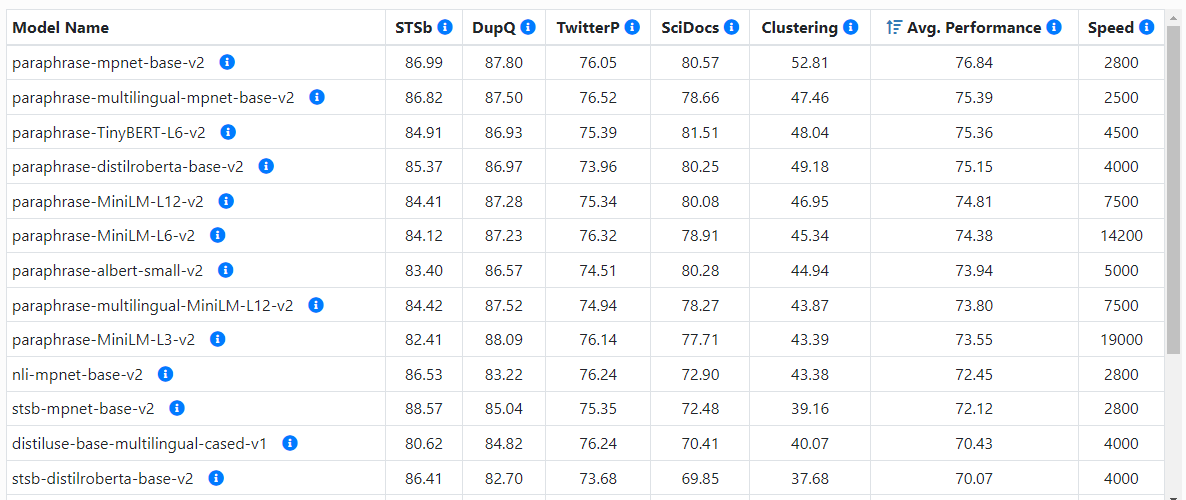
Sentence_transFormers semantic search, semantic similarity calculation, picture content understanding, pictures and text matching.
Table of contents Introduce the actual combat code of Sentence_TRANSFORMERS: Semantic similarity calculation: Semantic search Sentence cluster, similar sentence cluster Picture content understanding: ...